 40
40 
Содержание
- Что делают эти скрипты
- Запуск брокера в foreground-режиме
- Запуск в фоновом режиме с флагом -daemon
- Переменные окружения, которые влияют на запуск
- Управление памятью JVM
- Управление журналами
- Последовательность запуска в KRaft-режиме
- Как работает kafka-server-stop.sh
- Если kafka-server-stop.sh не находит процесс
- Проверка состояния брокера
- Альтернативные способы управления процессом запуска кластера Kafka
- systemd
- Запуск kafka кластер в Docker
- Сравнение способов запуска
- Что дальше
- Референсные ссылки
- Все уроки курса
В уроке 8 мы разобрали kafka-console-consumer.sh — как читать сообщения из топика, управлять смещениями и фильтровать данные по партициям. Теперь сделаем шаг назад и посмотрим на кое-что фундаментальное: как именно запускается и останавливается сам брокер Kafka.
Казалось бы, вопрос очевидный — мы уже запускали Kafka в уроках 2-4. Но там мы делали это по инструкции, не особо вникая в детали. В этом уроке разберём, что происходит под капотом, какие переменные окружения влияют на запуск, как правильно остановить брокер без потери данных и чем kafka-server-start.sh отличается от прямого запуска JVM-процесса.
Управление процессом брокера — базовый навык для любого администратора Kafka. Если вы планируете работать с Kafka в продакшне, детальное понимание этого урока пригодится на курсе «Администрирование кластера Kafka».
Что делают эти скрипты
kafka-server-start.sh и kafka-server-stop.sh — это тонкие обёртки над JVM-процессом Kafka. Сами по себе они не содержат логики запуска брокера. Их задача — правильно подготовить окружение, найти нужные JAR-файлы и передать управление классу kafka.Kafka.
Внутри kafka-server-start.sh происходит следующее:
- Проверка аргументов. Скрипт ожидает ровно один аргумент — путь к файлу конфигурации. Если аргумент не передан, он выводит подсказку и завершает работу.
- Загрузка окружения. Вызывается kafka-env.sh, который устанавливает KAFKA_HOME, LOG_DIR, JAVA_HOME и другие переменные.
- Вызов kafka-run-class.sh. Основной запуск делегируется этому скрипту с именем класса kafka.Kafka и путём к конфигу.
Итого: всё, что вы передаёте в kafka-server-start.sh, в итоге приходит в JVM как аргументы главного класса Kafka. Никакой магии.
Запуск брокера в foreground-режиме
Самый прямолинейный способ — запустить брокер прямо в терминале. Вывод логов идёт прямо в консоль, процесс завершается при закрытии терминала или нажатии Ctrl+C.
# Проверено: Apache Kafka 4.2.0, Ubuntu 22.04 kafka-server-start.sh $KAFKA_HOME/config/kraft/server.properties
Или через полный путь, если $KAFKA_HOME/bin не добавлен в PATH:
# Проверено: Apache Kafka 4.2.0, Ubuntu 22.04 /opt/kafka/bin/kafka-server-start.sh /opt/kafka/config/kraft/server.properties
Foreground-режим удобен при отладке — все сообщения брокера сразу видны в терминале. Для продакшна или долгосрочного использования он не подходит.
Запуск в фоновом режиме с флагом -daemon
Флаг -daemon переводит процесс в фоновый режим. Терминал освобождается, логи пишутся в файлы. Именно так Kafka обычно запускают на серверах без systemd.
# Проверено: Apache Kafka 4.2.0, Ubuntu 22.04 kafka-server-start.sh -daemon $KAFKA_HOME/config/kraft/server.properties
При запуске с -daemon Kafka создаёт PID-файл. По умолчанию он лежит в /tmp/kafka-{порт}.pid. Этот файл потом использует kafka-server-stop.sh, чтобы найти процесс для остановки.
Логи в daemon-режиме хранятся в нескольких файлах. Разберём какие из них важны.
- server.log. Основной лог брокера. Здесь видны старт, подключение партиций, ошибки.
- controller.log. Активен в KRaft-режиме. Содержит события контроллера — выборы лидера, изменения метаданных.
- state-change.log. Переходы состояний партиций и реплик.
- kafka.out. stdout и stderr самого процесса. Туда попадают JVM-ошибки, которые не попали в log4j.
По умолчанию все эти файлы лежат в $KAFKA_HOME/logs/. Путь переопределяется переменной LOG_DIR.
Apache Kafka: администрирование кластера
Код курса
KAFKA
Ближайшая дата курса
13 июля, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
Переменные окружения, которые влияют на запуск
Поведение kafka-server-start.sh гибко настраивается через переменные окружения. Их нужно экспортировать до запуска скрипта — либо прямо в shell, либо через ~/.bashrc, либо в systemd-юните.
Управление памятью JVM
Самая важная переменная в продакшне — KAFKA_HEAP_OPTS. По умолчанию Kafka стартует с 1 ГБ heap. Для нагруженных брокеров этого обычно мало.
# Задать heap 6 ГБ для нагруженного брокера export KAFKA_HEAP_OPTS="-Xmx6g -Xms6g" kafka-server-start.sh -daemon $KAFKA_HOME/config/kraft/server.properties
Рекомендация от Confluent и команды Apache Kafka — размер heap не должен превышать 6-8 ГБ. Большой heap увеличивает паузы GC. Остальную память лучше отдать под page cache операционной системы — именно через него Kafka читает данные с диска.
Для тонкой настройки JVM есть KAFKA_JVM_PERFORMANCE_OPTS. По умолчанию там уже прописаны разумные значения для G1GC, их обычно не меняют без конкретной причины.
# Посмотреть дефолтные JVM-параметры - они задаются внутри kafka-env.sh cat $KAFKA_HOME/bin/kafka-env.sh | grep KAFKA_JVM_PERFORMANCE_OPTS
Управление журналами
Две переменные управляют тем, куда пишутся логи:
- LOG_DIR. Директория для всех логов Kafka. По умолчанию $KAFKA_HOME/logs.
- KAFKA_LOG4J_OPTS. Путь к конфигурации log4j. По умолчанию $KAFKA_HOME/config/log4j.properties.
# Перенаправить логи в нестандартную директорию export LOG_DIR=/var/log/kafka kafka-server-start.sh -daemon $KAFKA_HOME/config/kraft/server.properties
Задание LOG_DIR особенно важно, если Kafka установлена в директорию без прав на запись для текущего пользователя.
Последовательность запуска в KRaft-режиме
В KRaft-режиме запуск брокера сложнее, чем кажется на первый взгляд. Процесс проходит несколько фаз, прежде чем начнёт принимать клиентские соединения. Ниже показана последовательность для узла с ролями broker+controller — типичный вариант для однонодовой установки из урока 2.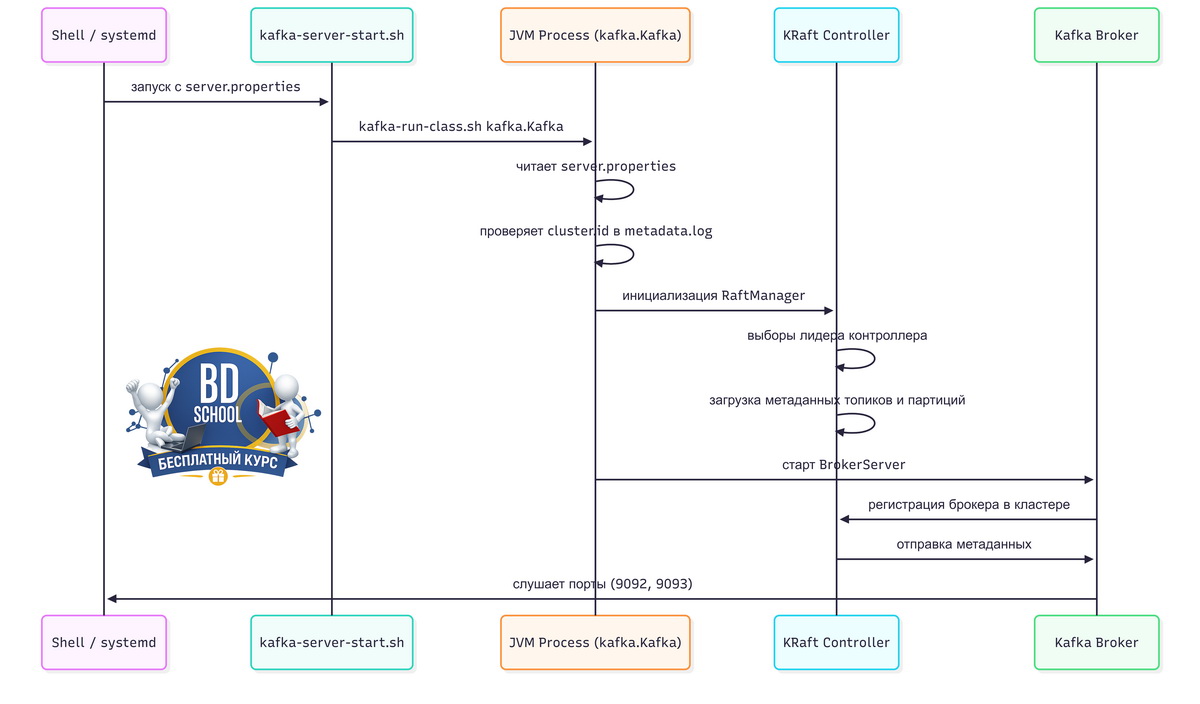
Ключевой момент — брокер начинает принимать клиентские соединения только после успешной регистрации у контроллера. Если контроллер не готов (например, нет кворума в многонодовом кластере), брокер будет ждать. Это нормальное поведение, не ошибка.
Как работает kafka-server-stop.sh
kafka-server-stop.sh выполняет три шага: находит PID процесса, отправляет ему сигнал SIGTERM и ждёт завершения. Всё.
kafka-server-stop.sh
Скрипт не принимает аргументов. PID он ищет двумя способами — сначала в PID-файле, потом через ps aux | grep kafka.Kafka. Если процесс не найден ни так, ни эдак, скрипт завершается с сообщением «No kafka server to stop».
SIGTERM запускает корректную остановку брокера. В этот момент происходит следующее:
- Деregистрация у контроллера. Брокер сообщает контроллеру, что уходит из кластера.
- Сброс буферов на диск (flush). Незаписанные данные из памяти сбрасываются в файлы сегментов.
- Закрытие соединений. Активные соединения с продюсерами и консьюмерами закрываются корректно.
- Запись checkpoint. Брокер записывает финальные offset-чекпойнты, чтобы при следующем старте не пришлось восстанавливать данные с нуля.
Процесс остановки занимает несколько секунд. Не прерывайте его принудительно через SIGKILL — это может привести к частичной потере последних записанных сообщений и замедлит следующий старт из-за восстановления логов.
Если kafka-server-stop.sh не находит процесс
Такое случается, если Kafka запускалась не через kafka-server-start.sh -daemon, а иначе — например, через foreground с последующим переводом в фон через оболочку. PID-файл в таком случае не создаётся. Тогда останавливают вручную:
# Найти PID процесса Kafka ps aux | grep kafka.Kafka | grep -v grep # Корректная остановка по PID kill -s TERM 12345
Проверка состояния брокера
После запуска важно убедиться, что брокер готов к работе. Несколько способов это сделать.
Самый быстрый — проверить, слушает ли процесс нужный порт:
# Проверить, что порт 9092 занят ss -tlnp | grep 9092 # Или через netstat (если установлен) netstat -tlnp | grep 9092
Подключиться к брокеру и запросить метаданные можно через kafka-broker-api-versions.sh — эту утилиту разберём в уроке 25:
kafka-broker-api-versions.sh --bootstrap-server localhost:9092
Если команда вернула список поддерживаемых API-версий — брокер работает и принимает соединения. Если вместо этого ошибка подключения — брокер ещё стартует или уже упал.
Хвост основного лога помогает понять, на каком шаге находится запуск:
tail -f $KAFKA_HOME/logs/server.log
Признак успешного запуска в логе — строка вида [KafkaServer id=1] started.
Apache Kafka: администрирование кластера
Код курса
KAFKA
Ближайшая дата курса
13 июля, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
Альтернативные способы управления процессом запуска кластера Kafka
В продакшне kafka-server-start.sh часто используют не напрямую, а через другие инструменты управления процессами. Разберём два наиболее распространённых варианта.
systemd
systemd — стандартный способ управлять сервисами на Ubuntu 22.04. Он сам перезапускает процесс при падении, управляет логами через journald и позволяет настроить зависимости между сервисами.
Минимальный unit-файл для Kafka:
# /etc/systemd/system/kafka.service [Unit] Description=Apache Kafka Server (KRaft mode) After=network.target [Service] Type=simple User=kafka Environment="JAVA_HOME=/usr/lib/jvm/java-21-openjdk-amd64" Environment="KAFKA_HEAP_OPTS=-Xmx4g -Xms4g" Environment="LOG_DIR=/var/log/kafka" ExecStart=/opt/kafka/bin/kafka-server-start.sh /opt/kafka/config/kraft/server.properties ExecStop=/opt/kafka/bin/kafka-server-stop.sh Restart=on-failure RestartSec=10 [Install] WantedBy=multi-user.target
После создания unit-файла применяем и запускаем:
sudo systemctl daemon-reload sudo systemctl enable kafka sudo systemctl start kafka # Проверить статус sudo systemctl status kafka # Посмотреть логи через journald sudo journalctl -u kafka -f
В этом сценарии kafka-server-start.sh всё так же используется внутри — просто теперь его вызывает systemd, а не вы руками. Тип сервиса simple означает, что systemd считает сервис запущенным сразу после старта процесса, не дожидаясь, когда брокер будет готов принимать соединения.
Запуск kafka кластер в Docker
В Docker-окружениях, которые мы настраивали в уроках 3 и 4, запуск брокера происходит внутри контейнера автоматически — через entrypoint-скрипт образа apache/kafka. Тот же kafka-server-start.sh, только вызывается уже внутри контейнера.
Управление брокером в Docker делается через compose-команды:
# Проверено: apache/kafka:4.2.0, Docker Compose v2.35 # Запустить docker compose up -d # Остановить корректно docker compose stop # Полная остановка с удалением контейнеров (данные в volume сохраняются) docker compose down
docker compose stop отправляет SIGTERM контейнеру, контейнер передаёт его процессу Kafka — и получается та же корректная остановка, что и через kafka-server-stop.sh. Использовать docker compose kill не стоит по той же причине, что и kill -9 в bare-metal сценарии.
Если нужно управлять Kafka из курса по администрированию через systemd и понять все детали production-развёртывания, эти темы разбираются в курсе «Администрирование кластера Kafka» с лабораторными на реальных кластерах.
Сравнение способов запуска
Подведём разницу между вариантами в таблицу — чтобы было понятно, когда что использовать.
| Способ | Когда использовать | Автоперезапуск | Логи |
|---|---|---|---|
| Foreground (без -daemon) | Отладка, разработка | нет | stdout в терминале |
| -daemon | Ручное управление на сервере | нет | $LOG_DIR/server.log |
| systemd | Продакшн на bare-metal или VM | да (Restart=on-failure) | journald + $LOG_DIR |
| Docker Compose | Разработка, тестирование, dev-стенды | да (restart: unless-stopped) | docker logs |
Для учебных целей достаточно foreground или -daemon. Для любого сервера, который работает без постоянного присмотра, используйте systemd или Docker с политикой перезапуска.
Apache Kafka для инженеров данных
Код курса
DEVKI
Ближайшая дата курса
24 августа, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
Что дальше
Теперь вы знаете, как Kafka стартует и останавливается, что происходит за кулисами и как это вписывается в реальный production-сценарий.
В уроке 10 займёмся утилитой kafka-storage.sh. Это инструмент, без которого невозможно запустить Kafka в KRaft-режиме — именно он форматирует хранилище метаданных перед первым стартом. Разберём, что именно форматируется, что хранится в __cluster_metadata и как восстановить кластер после потери данных контроллера.
Референсные ссылки
- Apache Kafka 4.2.0 — KRaft Mode (официальная документация)
- Apache Kafka Operations — запуск, остановка, мониторинг (официальная документация)
- Apache Kafka — поддерживаемые версии Java и рекомендации по JVM (официальная документация)
- KIP-595. A Raft Protocol for the Metadata Quorum (Apache Kafka Wiki)
- kafka-server-start.sh — исходный код на GitHub (Apache Kafka)
Все уроки курса