 33
33 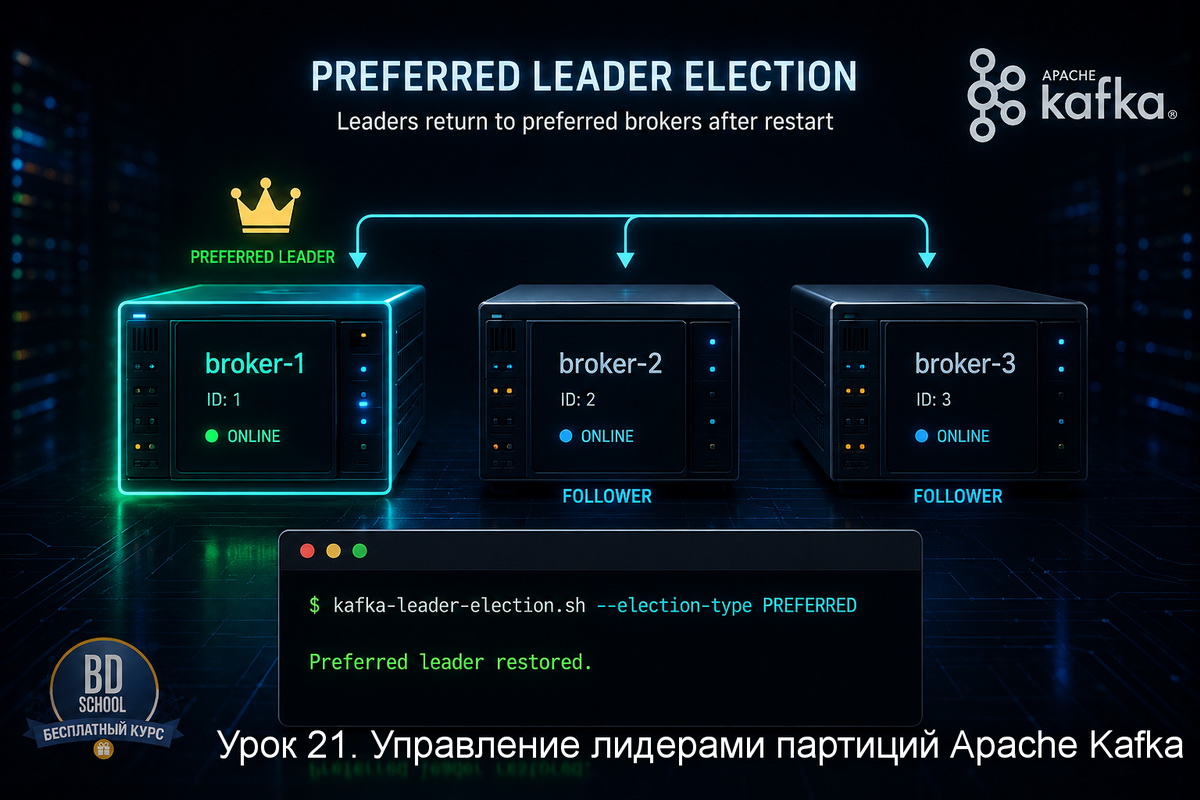
Содержание
В уроке 20 мы разбирали kafka-streams-application-reset.sh — инструмент для сброса состояния Kafka Streams приложений. Там речь шла о внутренних топиках, changelog-топиках и локальных state store.
Сегодня переключаемся на другую задачу — управление лидерами партиций. kafka-leader-election.sh нужна когда лидер партиции после сбоя или перезапуска брокера оказался не там, где должен быть. Утилита позволяет вернуть лидерство предпочтительной реплике или, в крайнем случае, принудительно выбрать лидера из неподходящих кандидатов.
Тема лидерства партиций и репликации активно разбирается в курсе «Администрирование кластера Kafka» — там же практика по балансировке нагрузки и работе с ISR.
Лидер партиции и почему он важен
Каждая партиция в Kafka имеет одну реплику, которая называется лидером (leader). Именно через лидера идут все операции записи и чтения. Остальные реплики — фолловеры — только синхронизируют данные с лидером и держатся в очереди на замену.
У каждой партиции есть предпочтительная реплика (preferred replica) — брокер, указанный первым в списке реплик топика. Kafka стремится держать лидерство именно там, чтобы нагрузка была равномерно распределена по кластеру.
Проблема возникает после перезапуска брокера. Когда брокер падает, лидерство его партиций переходит к другим фолловерам. После того как брокер возвращается в строй, он не становится лидером автоматически — если только не включён параметр auto.leader.rebalance.enable. По умолчанию он включён, но это фоновый процесс с задержкой. Если нужно вернуть лидерство здесь и сейчас — вот для этого и существует kafka-leader-election.sh.
Два типа выборов
Утилита поддерживает два принципиально разных типа выборов лидера. Разница между ними критическая — в одном случае данные не теряются, в другом могут.
| Тип | Флаг | Кандидат на лидера | Риск потери данных | Когда использовать |
|---|---|---|---|---|
| PREFERRED | —election-type PREFERRED | Только preferred replica из ISR | нет | Возврат лидера после перезапуска брокера |
| UNCLEAN | —election-type UNCLEAN | Любая доступная реплика, даже вне ISR | да (возможна потеря сообщений) | Только когда все ISR-реплики недоступны |
ISR (In-Sync Replicas) — это список реплик, которые синхронизированы с лидером. Выборы типа PREFERRED безопасны именно потому, что preferred replica уже в ISR и имеет все актуальные данные. UNCLEAN-выборы — это крайняя мера: реплика за пределами ISR могла отстать, и часть сообщений после её назначения лидером окажется недоступна навсегда.
Флаги kafka-leader-election.sh
| Флаг | Что делает | Обязательный |
|---|---|---|
| —bootstrap-server | Адрес брокера в формате host:port | да |
| —election-type | Тип выборов: PREFERRED или UNCLEAN | да |
| —all-topic-partitions | Запустить выборы для всех партиций всех топиков в кластере | нет* |
| —topic | Имя конкретного топика | нет* |
| —partition | Номер партиции внутри топика (используется вместе с —topic) | нет |
| —path-to-json-file | Путь к JSON-файлу со списком топиков и партиций | нет* |
* Один из трёх способов задать цель — —all-topic-partitions, —topic или —path-to-json-file — обязателен. Использовать их одновременно нельзя.
Примеры. PREFERRED election
Самый частый сценарий: после перезапуска брокера нужно вернуть лидерство preferred replica. Начнём с проверки текущего состояния через kafka-topics.sh.
# Смотрим текущих лидеров топика orders kafka-topics.sh --bootstrap-server localhost:9092 \ --describe --topic orders
В выводе ищем колонку Leader и сравниваем с колонкой Replicas. Первый брокер в Replicas — это preferred replica. Если Leader и первый в Replicas совпадают — всё в порядке. Если нет — пора запускать выборы.
Preferred election для одной партиции топика:
# Preferred election для партиции 0 топика orders kafka-leader-election.sh --bootstrap-server localhost:9092 \ --election-type PREFERRED \ --topic orders \ --partition 0
Для всего топика сразу (все партиции):
# Preferred election для всех партиций топика orders kafka-leader-election.sh --bootstrap-server localhost:9092 \ --election-type PREFERRED \ --topic orders
Для всех топиков кластера — флаг —all-topic-partitions:
# Preferred election для всех партиций во всём кластере kafka-leader-election.sh --bootstrap-server localhost:9092 \ --election-type PREFERRED \ --all-topic-partitions
Если preferred replica уже является лидером, Kafka просто пропустит партицию без ошибки. Команда для всего кластера безопасна в любой момент — лишних переключений не будет.
Apache Kafka: администрирование кластера
Код курса
KAFKA
Ближайшая дата курса
13 июля, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
Выборы через JSON-файл
Когда нужно точно указать несколько конкретных партиций из разных топиков, удобнее использовать JSON-файл. Это особенно актуально в больших кластерах с десятками топиков, где выборы для всего кластера могут затронуть лишние партиции.
Формат файла (назовём его partitions.json):
{
"partitions": [
{"topic": "orders", "partition": 0},
{"topic": "orders", "partition": 2},
{"topic": "payments", "partition": 1}
]
}
Запуск с JSON-файлом:
kafka-leader-election.sh --bootstrap-server localhost:9092 \ --election-type PREFERRED \ --path-to-json-file /tmp/partitions.json
JSON-файл удобно использовать в скриптах автоматизации. Например, выгружать проблемные партиции из мониторинга и передавать сюда без ручного перебора.
UNCLEAN election. Когда и как
UNCLEAN election — это последний рубеж. Применяется только когда все ISR-реплики партиции недоступны и кластер не может выбрать лидера обычным способом. Партиция при этом «offline» — читать из неё и писать в неё невозможно.
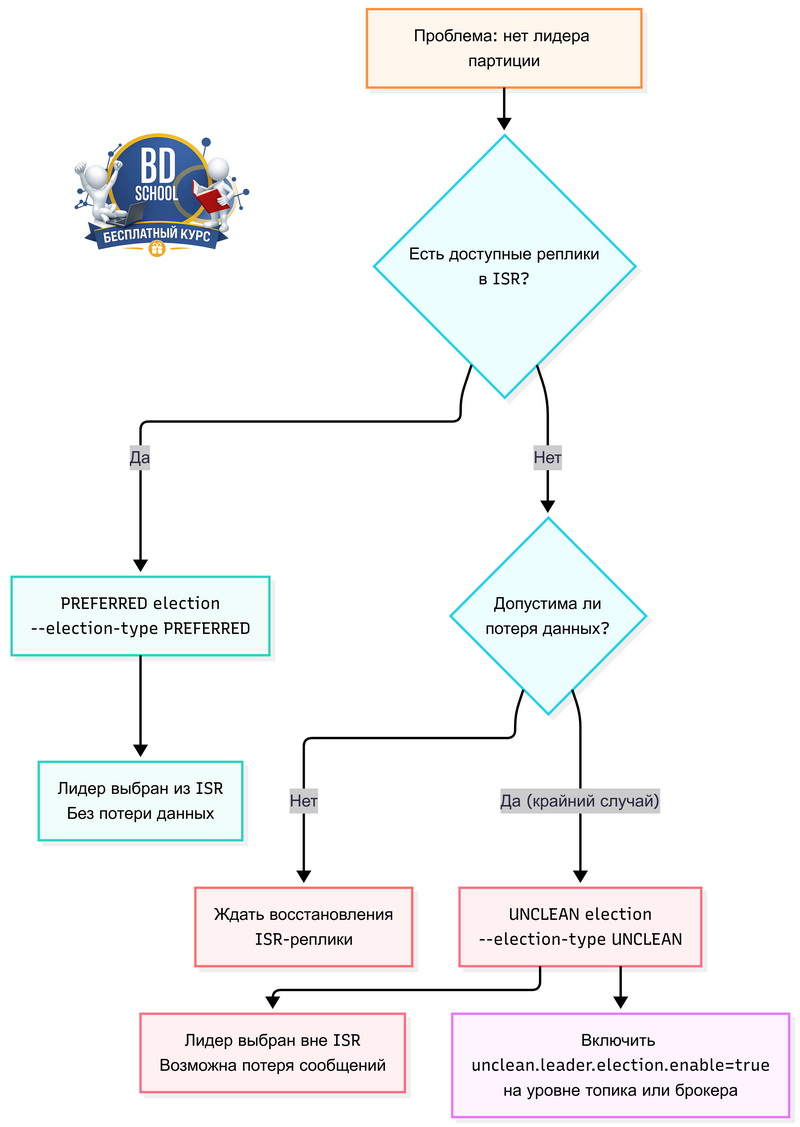
Важный нюанс: чтобы UNCLEAN election сработал, на уровне топика должен быть включён параметр unclean.leader.election.enable=true. По умолчанию он false. Без этого параметра команда вернёт ошибку, даже если синтаксис правильный.
Включаем параметр для топика через kafka-configs.sh:
# Разрешаем unclean election для топика orders kafka-configs.sh --bootstrap-server localhost:9092 \ --alter --entity-type topics \ --entity-name orders \ --add-config unclean.leader.election.enable=true
После этого запускаем UNCLEAN election:
# UNCLEAN election для партиции 0 топика orders kafka-leader-election.sh --bootstrap-server localhost:9092 \ --election-type UNCLEAN \ --topic orders \ --partition 0
После восстановления не забудьте отключить unclean.leader.election.enable обратно. Держать этот параметр включённым постоянно — плохая практика, он существенно снижает гарантии консистентности данных.
Как выглядит вывод утилиты
При успехе утилита печатает короткое подтверждение для каждой партиции, где лидер действительно сменился:
Successfully completed leader election (PREFERRED) for partitions: orders-0 orders-2 payments-1
Если preferred replica уже была лидером, партиция в вывод не попадает — это нормально, не сигнал ошибки. Если же что-то пошло не так, утилита выдаст ERROR с описанием причины — например, что preferred replica не входит в ISR или что брокер недоступен.
Автоматические выборы и когда утилита не нужна
Kafka умеет балансировать лидеров сама — без ручного вмешательства. За это отвечают два параметра конфигурации брокера.
- auto.leader.rebalance.enable=true. Контроллер периодически проверяет, являются ли preferred replica лидерами своих партиций. Если нет — запускает выборы автоматически. По умолчанию включён.
- leader.imbalance.check.interval.seconds. Как часто контроллер делает эту проверку. По умолчанию 300 секунд (5 минут).
Если автобалансировка включена, после возврата брокера в кластер лидерство восстановится само — но с задержкой до 5 минут. Если это критично, запускайте kafka-leader-election.sh вручную сразу после того, как брокер снова в строю. В нагруженных кластерах администраторы часто отключают автобалансировку (auto.leader.rebalance.enable=false) и делают её вручную в окно обслуживания — это предсказуемее.
Управлять этими параметрами можно через kafka-configs.sh или напрямую в server.properties.
Практический сценарий. Брокер вернулся после падения
Разберём типичный сценарий: брокер broker-1 упал, лидерство его партиций разошлось по другим брокерам, broker-1 вернулся. Нужно восстановить исходное распределение лидеров.
Шаг 1. Убеждаемся, что broker-1 снова в кластере и его реплики в ISR:
# Смотрим партиции, где leader != preferred (первый в Replicas) kafka-topics.sh --bootstrap-server localhost:9092 \ --describe | grep -v "Leader: $(echo)" | head -20
Шаг 2. Запускаем preferred election для всего кластера:
kafka-leader-election.sh --bootstrap-server localhost:9092 \ --election-type PREFERRED \ --all-topic-partitions
Шаг 3. Проверяем результат — лидеры должны вернуться к preferred replica:
kafka-topics.sh --bootstrap-server localhost:9092 \ --describe --topic orders
Весь сценарий занимает меньше минуты. Это значительно быстрее, чем ждать автобалансировки.
Apache Kafka: администрирование кластера
Код курса
KAFKA
Ближайшая дата курса
13 июля, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
Что дальше
В уроке 22 разберём kafka-reassign-partitions.sh — инструмент для переноса партиций между брокерами. Если kafka-leader-election.sh меняет только лидера внутри уже существующего набора реплик, то kafka-reassign-partitions.sh меняет сам набор — переносит реплики на другие брокеры. Это нужно при масштабировании кластера и при выводе брокера из эксплуатации.
Референсные ссылки
- Apache Kafka Documentation. Leader Balancing — официальная документация по балансировке лидеров (2025)
- Confluent Developer. Kafka Replication and Leader Election — подробно об ISR, preferred replica и механизме выборов (2025)
- Apache Kafka KIP-631. KRaft Controller и управление лидерами в кластере без ZooKeeper (2025)
- Apache Kafka Documentation. unclean.leader.election.enable — описание параметра и рисков UNCLEAN election (2025)