 316
316 
Содержание
- Что такое KRaft и зачем он нужен?
- Архитектура кластера Apache Kafka KRaft в однонодовом режиме
- Установка кластера Apache Kafka 4.X Требования к системе.
- Шаг 1. Установка Java 17
- Шаг 2. Загрузка Apache Kafka 4.2.0
- Шаг 3. Конфигурация KRaft
- Шаг 4. Форматирование хранилища
- Шаг 5. Запуск брокера
- Шаг 6. Проверка установки
- Как остановить Apache Kafka Kraft кластер
- Установка с ZooKeeper vs KRaft. Сравнение подходов
- Что дальше?
- Референсные ссылки
- Все уроки курса
Изучаем Apache Kafka с нуля. Урок 2. Установка Apache Kafka в режиме KRaft
ПО: Apache Kafka 4.2.0
Окружение: Ubuntu 22.04 LTS, Java 17
Уровень: начинающий
В первом уроке мы установили Apache Kafka 3.9.0 в связке с ZooKeeper. Это был классический способ развернуть кластер — тот, которым пользовались годами. Но начиная с Apache Kafka 4.0.0, ZooKeeper полностью убрали из дистрибутива. Его заменил встроенный механизм консенсуса — Apache Kafka KRaft. Так что если вы устанавливаете Kafka сегодня, путь только один.
В этом уроке мы разберём, что такое KRaft и почему он заменил ZooKeeper, а потом шаг за шагом установим Apache Kafka 4.2.0 на Ubuntu 22.04. Никаких внешних зависимостей — только сама Kafka и Java. В итоге у вас будет работающий брокер, готовый к следующим урокам.
Важный момент: в первом уроке мы установили Kafka 3.9.0 в каталог /opt/kafka. Чтобы две версии не конфликтовали, для Kafka 4.2.0 используем отдельный каталог — /opt/kafka4. Это позволяет держать обе установки рядом и не запутаться.
Если хотите разобраться с Kafka глубже — посмотрите на наш курс KAFKA: Администрирование кластера Kafka. Там три дня практики и 24 академических часа теории про KRaft, репликацию и всё, что нужно для работы с кластером в продакшне.
Что такое KRaft и зачем он нужен?
Исторически Apache Kafka хранила метаданные кластера в ZooKeeper — отдельном сервисе на основе протокола ZAB. Это создавало заметную операционную нагрузку: нужно было отдельно устанавливать, мониторить и масштабировать ZooKeeper, синхронизировать его версии с Kafka, думать о топологии кластера как о двух разных системах.
KRaft (Kafka Raft) — это реализация алгоритма консенсуса Raft прямо внутри Kafka. Метаданные теперь хранятся во внутреннем топике __cluster_metadata, а контроллер Kafka сам управляет кворумом. Внешний ZooKeeper больше не нужен.
Что изменилось на практике по сравнению с архитектурой из первого урока:
- Один процесс. Kafka сама является и брокером, и контроллером. Для одноузлового кластера это один процесс с двумя ролями.
- Быстрее восстановление. Контроллер больше не перечитывает состояние из ZooKeeper при перезапуске — метаданные всегда доступны локально.
- Нет лимита на партиции. ZooKeeper плохо масштабировался при сотнях тысяч партиций. KRaft этого ограничения не имеет.
- Проще операционка. Один сервис вместо двух, одна точка мониторинга, меньше точек отказа.
Таким образом, KRaft — это не просто внутреннее изменение архитектуры. Это принципиальное упрощение эксплуатации Kafka-кластера.
Архитектура кластера Apache Kafka KRaft в однонодовом режиме
Прежде чем перейти к установке, полезно понять, что именно мы запускаем. В однонодовом режиме один процесс Kafka выполняет обе роли — брокера и контроллера. Порты у них разные: 9092 для клиентских подключений, 9093 для внутреннего трафика контроллера.
Диаграмма ниже показывает, как это выглядит изнутри.
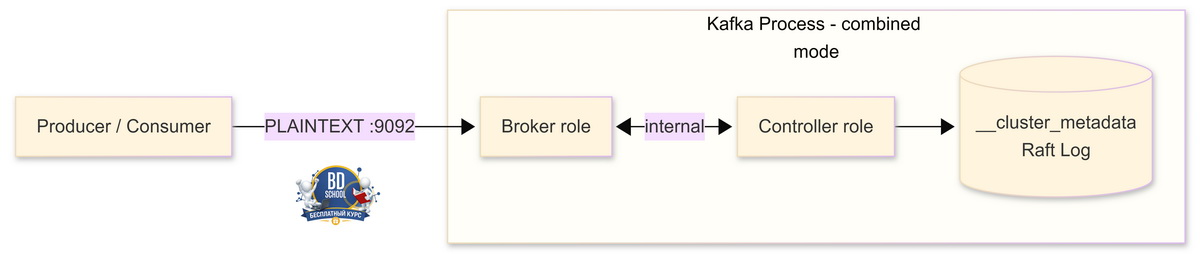
Продюсеры и консьюмеры подключаются к брокеру на порт 9092. Контроллер на порту 9093 занимается исключительно метаданными — топиками, партициями, состоянием реплик. При масштабировании на несколько узлов роли можно разделить, но для разработки и обучения комбинированный режим удобнее.
Установка кластера Apache Kafka 4.X Требования к системе.
Для установки Apache Kafka 4.2.0 в режиме KRaft нужно совсем немного. Проверьте, что у вас есть следующее перед началом работы.
- ОС. Ubuntu 22.04 LTS или любой современный Linux-дистрибутив. На macOS всё то же самое, кроме команды установки Java.
- Java 17. Начиная с Kafka 4.0, минимально поддерживаемая версия — Java 11, но рекомендуется Java 17. Ниже мы установим именно её.
- Свободное место. Минимум 2 ГБ — для архива, логов и данных брокера.
- Порты 9092 и 9093. Убедитесь, что они не заняты другими процессами. ( Нельзя запускать одновременно односолодовую Kafka из 1 урока с данной:-)
Никаких других зависимостей — ни ZooKeeper, ни отдельных баз данных, ни сторонних сервисов. Это одно из главных преимуществ KRaft-режима.
Шаг 1. Установка Java 17
Kafka написана на Java и требует JDK для запуска. Проверяем, есть ли Java в системе. ( Если вы уже выполнили урок 1 то Java у вас точно есть)
java -version
Если видите ошибку «command not found» или версию ниже 11 — устанавливаем OpenJDK 17.
sudo apt update sudo apt install -y openjdk-17-jdk java -version
После установки команда java -version должна вернуть что-то вроде openjdk 17.x.x. Если у вас несколько версий Java — убедитесь, что по умолчанию выбрана нужная через update-alternatives —config java.
Шаг 2. Загрузка Apache Kafka 4.2.0
Скачиваем архив с официального сайта Apache и распаковываем его. Обычно удобно хранить Kafka в директории /opt.
wget https://downloads.apache.org/kafka/4.2.0/kafka_2.13-4.2.0.tgz tar -xzf kafka_2.13-4.2.0.tgz sudo mv kafka_2.13-4.2.0 /opt/kafka4
Здесь 2.13 — это версия Scala, с которой собрана Kafka. Для повседневной работы это не важно — просто берите самую новую сборку со страницы загрузок. После распаковки структура директорий выглядит так.
- bin/ — все скрипты управления: kafka-topics.sh, kafka-console-producer.sh и другие утилиты, которые мы разберём в уроках 6-33.
- config/ — конфигурационные файлы. Для KRaft нас интересует config/kraft/server.properties.
- libs/ — библиотеки Kafka. Трогать не нужно.
- logs/ — директория для логов сервера (создаётся при первом запуске).
Для удобства добавим /opt/kafka4/bin в переменную окружения PATH, чтобы не писать полный путь к каждой утилите. Подробнее о настройке переменных окружения мы поговорим в уроке 5.
# Добавить в ~/.bashrc или ~/.zshrc echo 'export KAFKA_HOME=/opt/kafka4' >> ~/.bashrc echo 'export PATH=$PATH:$KAFKA_HOME/bin' >> ~/.bashrc source ~/.bashrc
Шаг 3. Конфигурация KRaft
Apache Kafka 4.2.0 уже поставляется с готовым конфигом для KRaft — это файл config/kraft/server.properties. Для однонодового кластера его настроек по умолчанию достаточно для старта. Тем не менее разберём ключевые параметры, чтобы понимать, что именно запускаем.
# Ключевые параметры из config/kraft/server.properties # Роли этого узла: брокер и контроллер одновременно process.roles=broker,controller # ID этого узла в кластере. Должен быть уникальным node.id=1 # Список контроллеров кворума: node.id@host:port controller.quorum.voters=1@localhost:9093 # Слушатели: клиентский и контроллерный listeners=PLAINTEXT://:9092,CONTROLLER://:9093 advertised.listeners=PLAINTEXT://localhost:9092 # Имена слушателей inter.broker.listener.name=PLAINTEXT controller.listener.names=CONTROLLER # Куда писать данные log.dirs=/tmp/kraft-combined-logs
Менять что-то в этом конфиге на данном этапе не нужно. Единственное, что стоит поправить при работе на сервере — advertised.listeners: замените localhost на реальный IP или hostname машины, если к брокеру будут подключаться извне.
Шаг 4. Форматирование хранилища
Это шаг, которого не было при установке с ZooKeeper. Перед первым запуском Kafka в KRaft-режиме нужно инициализировать директорию данных. Это делается в два действия.
Сначала генерируем уникальный идентификатор кластера — Cluster UUID. Он записывается в метаданные и связывает все узлы кластера между собой.
KAFKA_CLUSTER_ID="$(kafka-storage.sh random-uuid)" echo $KAFKA_CLUSTER_ID
Теперь форматируем хранилище данных. Команда создаёт нужную структуру директорий и записывает метафайл с UUID кластера.
kafka-storage.sh format \ -t $KAFKA_CLUSTER_ID \ -c /opt/kafka4/config/server.properties \ --standalone

Standalone используется для однонодовой инсталляции кластера Kafka Kraft. При успешном выполнении увидите сообщение Formatting /tmp/kraft-combined-logs. Эту команду нужно выполнить только один раз — при первоначальной установке. Если запустить повторно без флага —ignore-formatted, команда вернёт ошибку и откажется перезаписывать данные. Это сделано намеренно для защиты от случайного затирания данных кластера.
Шаг 5. Запуск брокера
Всё готово — запускаем Kafka. В учебных целях удобно запускать в фоновом режиме с помощью флага -daemon.
kafka-server-start.sh -daemon /opt/kafka4/config/server.properties
Kafka пишет логи в /opt/kafka4/logs/server.log. Следить за запуском в реальном времени можно так.
tail -f /opt/kafka4/logs/server.log
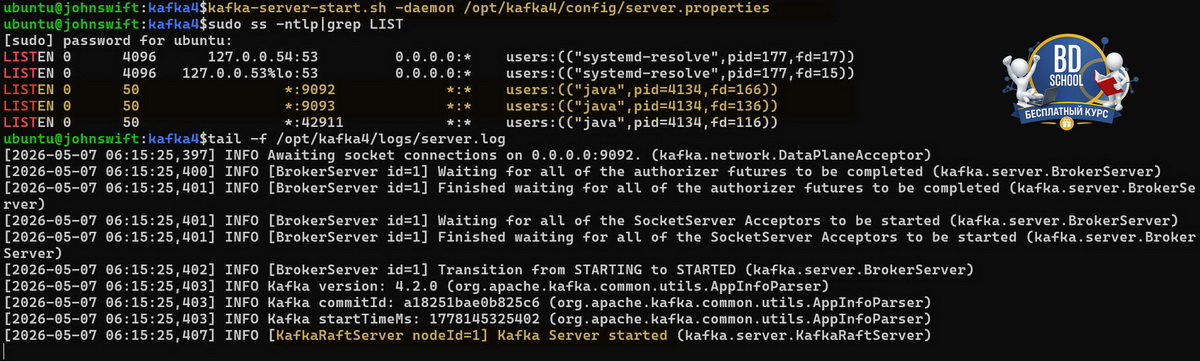
Строка KafkaServer id=1] started в логах означает, что брокер успешно поднялся и готов принимать подключения. Если видите ошибки — чаще всего это занятый порт или неверный путь к конфигу.
Шаг 6. Проверка установки
Проверяем, что брокер работает корректно. Для начала убеждаемся, что процесс запущен.
ps aux | grep kafka sudo ss -ntlp|grep LIST
Затем делаем первый реальный тест — создаём топик, отправляем сообщение и читаем его обратно. Это минимальный end-to-end тест, который подтверждает, что и продюсер, и консьюмер работают.
# Создаём тестовый топик kafka-topics.sh \ --bootstrap-server localhost:9092 \ --create \ --topic test-topic \ --partitions 1 \ --replication-factor 1 # Проверяем, что топик создан kafka-topics.sh \ --bootstrap-server localhost:9092 \ --list

# Отправляем сообщение (введите текст и нажмите Ctrl+C) echo "hello kafka kraft" | kafka-console-producer.sh \ --bootstrap-server localhost:9092 \ --topic test-topic
# Читаем сообщение kafka-console-consumer.sh \ --bootstrap-server localhost:9092 \ --topic test-topic \ --from-beginning \ --max-messages 1
Если в терминале появилась строка hello kafka kraft — установка прошла успешно. Брокер принимает подключения, создаёт топики и передаёт сообщения.
Как остановить Apache Kafka Kraft кластер
Для корректной остановки используйте специальный скрипт, а не kill -9. Грубое завершение процесса без flush может привести к повреждению данных в логах.
kafka-server-stop.sh
Kafka пишет в лог сообщение об остановке и корректно закрывает все открытые файловые дескрипторы. Подробнее о скриптах запуска и остановки поговорим в уроке 9.
Установка с ZooKeeper vs KRaft. Сравнение подходов
После двух уроков у вас есть опыт с обоими подходами. Вот краткое сравнение, чтобы разница была наглядной.
| Параметр | ZooKeeper (урок 1) | KRaft (урок 2) |
|---|---|---|
| Версия Kafka | 3.9.0 | 4.2.0 |
| Количество процессов | 2 (ZooKeeper + Kafka) | 1 (только Kafka) |
| Внешние зависимости | ZooKeeper | нет |
| Хранение метаданных | ZooKeeper znodes | __cluster_metadata топик |
| Шаг форматирования хранилища | не нужен | обязателен |
| Порты по умолчанию | 2181 (ZK) + 9092 (Kafka) | 9092 (broker) + 9093 (controller) |
| Поддержка в актуальных версиях | удалён с версии 4.0.0 | единственный режим с 4.0.0 |
С практической точки зрения для новых проектов ZooKeeper-режим больше не актуален. Все уроки этого курса со второго по тридцать третий работают с KRaft на Apache Kafka 4.2.0.
Что дальше?
Мы установили Apache Kafka 4.2.0 в режиме KRaft и убедились, что брокер работает. В следующих уроках разберём, как запускать Kafka в Docker — сначала однонодовый вариант, потом кластер из трёх узлов. В уроке 3 упакуем всё, что сделали сегодня, в Docker-контейнер с помощью Docker Compose. Это удобно для разработки — можно запускать и останавливать Kafka одной командой, не засоряя основную систему.
Референсные ссылки
- Apache Kafka 4.2.0 — Quick Start (официальная документация)
- Apache Kafka KRaft Mode — официальная документация по KRaft
- Removing the ZooKeeper Dependency from Kafka — блог Apache Kafka
- KIP-833. Mark KRaft as Production Ready — Apache Kafka Wiki

