 29
29 
Содержание
- Что делает kafka-replica-verification.sh
- Флаги и параметры
- Первый запуск и вывод утилиты
- Типичные сценарии использования
- Проверка после переназначения партиций
- Проверка конкретной группы топиков по regex
- Проверка с начала лога
- Ограничение нагрузки через fetch-size
- Как интерпретировать результат
- Ограничения и когда использовать другие инструменты
- Запуск на ограниченное время
- Альтернативы и дополнение к утилите
- Что дальше
- Референсные ссылки
- Все уроки курса
В уроке 22 мы разобрались с kafka-reassign-partitions.sh: генерировали план переноса партиций, запускали его с троттлингом и проверяли статус через —verify. После того как переназначение завершилось — данные физически переехали, реплики поднялись на новых брокерах.
Но как убедиться, что данные во всех репликах одинаковые? Что ни одна реплика не отстала и не разошлась с лидером по содержимому? Для этого в стандартной поставке Kafka есть отдельный инструмент — kafka-replica-verification.sh. Он читает данные с каждой реплики напрямую и сравнивает смещения.
Тема мониторинга репликации подробно разбирается в курсе «Администрирование кластера Kafka» — там же практика настройки алертов на under-replicated partitions и интеграция с Prometheus.
Что делает kafka-replica-verification.sh
Утилита работает иначе, чем большинство инструментов из bin/. Она не просто смотрит на метаданные — она сама подключается к каждому брокеру, у которого есть реплика нужного топика, и запрашивает данные через Fetch API. Потом сравнивает смещения: что лидер отдаёт на определённый момент времени и что отдают фолловеры.
Вывод появляется периодически — по умолчанию раз в 30 секунд — и показывает, насколько каждая реплика отстала от лидера. Если реплики синхронизированы, лаг равен нулю. Если нет — утилита покажет, в каком именно топике и партиции есть расхождение и на сколько сообщений.
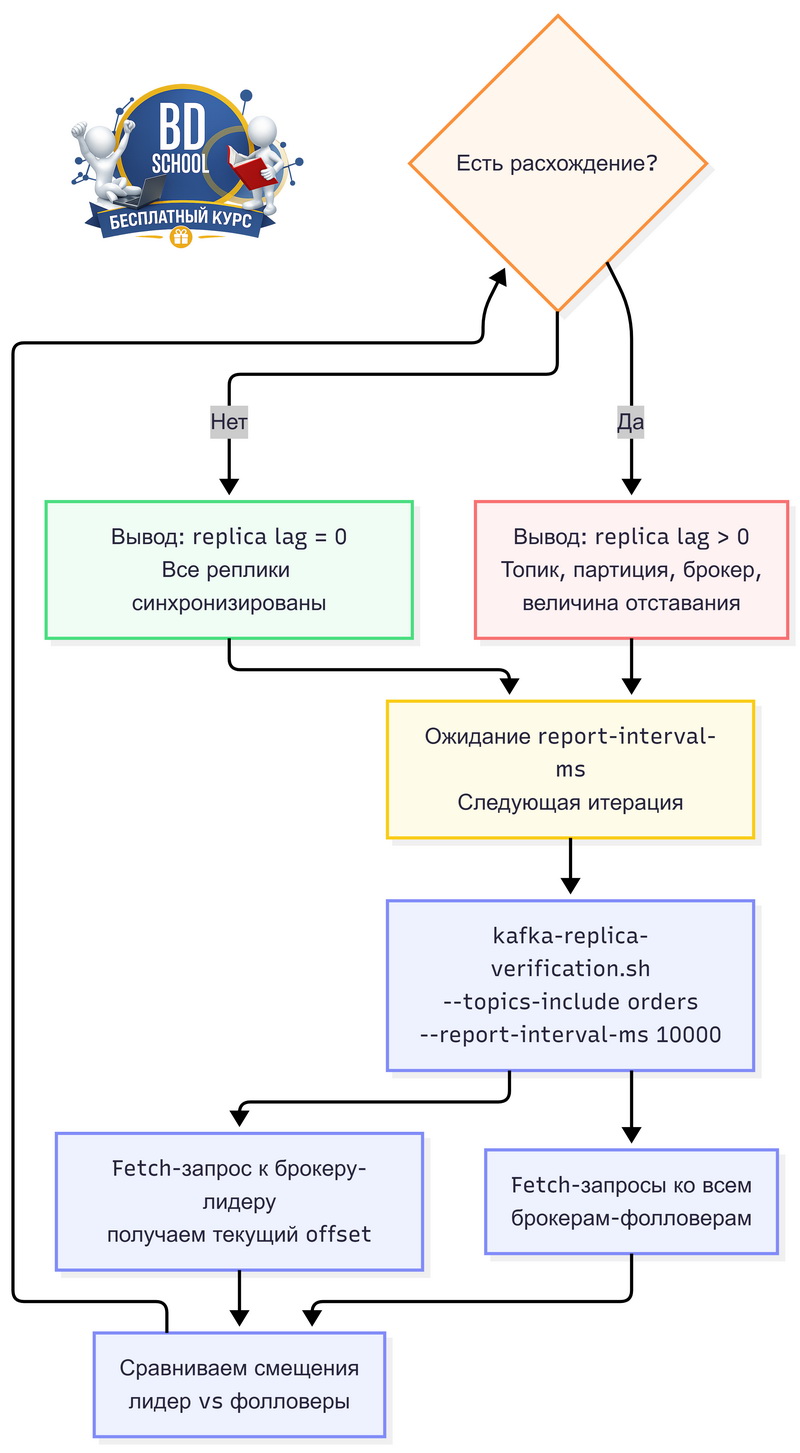
Важная особенность: kafka-replica-verification.sh работает как непрерывный процесс. Она не завершается сама по себе — нужно либо прерывать вручную через Ctrl+C, либо ограничивать количество итераций снаружи. Это делает её скорее инструментом мониторинга в реальном времени, чем разовой проверкой.
Флаги и параметры
Набор флагов у утилиты небольшой, но у каждого есть нюансы, которые влияют на результат.
| Флаг | По умолчанию | Описание |
|---|---|---|
| —bootstrap-server | — | Адрес брокера для начального подключения. Обязательный. |
| —topics-include | .* | Regex-фильтр топиков для проверки. Если не указан — проверяются все топики. |
| —fetch-size | 1048576 (1 МБ) | Размер данных, запрашиваемых за одну операцию Fetch. Влияет на нагрузку на брокеры. |
| —max-wait-ms | 1000 | Максимальное время ожидания ответа от брокера в миллисекундах. |
| —time | -1 | Временная точка для проверки: -1 — latest (конец лога), -2 — earliest (начало лога). |
| —report-interval-ms | 30000 | Интервал между выводами отчёта в миллисекундах. 30 секунд по умолчанию. |
Флаг —topics-include принимает Java-совместимое регулярное выражение. Например, orders.* покроет все топики, начинающиеся на «orders». Без фильтра утилита пойдёт во все топики кластера, включая внутренние — это создаёт заметную нагрузку на больших кластерах.
Устаревший флаг —topic-white-list в Kafka 4.x уже убран — используйте только —topics-include.
Первый запуск и вывод утилиты
Запустим проверку на топике orders с интервалом 10 секунд — чтобы не ждать полминуты до первого вывода:
# Проверяем реплики топика orders каждые 10 секунд kafka-replica-verification.sh \ --bootstrap-server localhost:9092 \ --topics-include "orders" \ --report-interval-ms 10000
Если реплики синхронизированы, вывод будет выглядеть примерно так:
2025-04-01 12:00:10,123: verification process is started. 2025-04-01 12:00:20,456: max lag is 0 for partition orders-0 at offset 18432 among 3 partitions monitored
Здесь важны два числа: max lag is 0 — реплики не отстают, и among 3 partitions monitored — утилита действительно видит все три партиции топика. Если число партиций неожиданно маленькое, проверьте regex в —topics-include.
Если есть отставание, сообщение изменится:
2025-04-01 12:00:20,789: max lag is 1247 for partition orders-2 at offset 19200 among 3 partitions monitored
Это значит, что реплика партиции orders-2 отстаёт на 1247 сообщений от лидера на смещении 19200. Это не обязательно катастрофа — реплика могла временно отстать из-за нагрузки и сейчас догоняет. Но если лаг не уменьшается между итерациями — это сигнал разбираться.
Apache Kafka: администрирование кластера
Код курса
KAFKA
Ближайшая дата курса
13 июля, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
Типичные сценарии использования
Проверка после переназначения партиций
После того как kafka-reassign-partitions.sh —verify сообщил об успешном завершении, переназначение формально закончено. Но это не гарантирует, что все реплики уже полностью синхронизированы — в ISR они могут попасть чуть позже. Дополнительная проверка через kafka-replica-verification.sh даёт уверенность, что данные действительно совпадают:
# Запускаем с коротким интервалом и смотрим на динамику лага # Ctrl+C для остановки после нескольких итераций kafka-replica-verification.sh \ --bootstrap-server localhost:9092 \ --topics-include "orders|payments" \ --report-interval-ms 5000
Если через несколько итераций лаг остаётся нулём — реплики в порядке.
Проверка конкретной группы топиков по regex
На production-кластерах удобно проверять только нужный набор топиков, не создавая лишнюю нагрузку. Regex в —topics-include даёт нужную гибкость:
# Проверяем только топики с префиксом prod- (production-окружение) kafka-replica-verification.sh \ --bootstrap-server localhost:9092 \ --topics-include "prod-.*" \ --report-interval-ms 15000 # Проверяем несколько конкретных топиков через или (|) kafka-replica-verification.sh \ --bootstrap-server localhost:9092 \ --topics-include "orders|payments|inventory" \ --report-interval-ms 10000
Проверка с начала лога
По умолчанию утилита смотрит на конец лога (latest). Если нужно убедиться в согласованности данных с начала — используйте флаг —time -2. Это полезно после восстановления брокера из резервной копии или при подозрении на потерю исторических данных:
# Проверяем реплики с начала лога (earliest) kafka-replica-verification.sh \ --bootstrap-server localhost:9092 \ --topics-include "orders" \ --time -2 \ --report-interval-ms 10000
Ограничение нагрузки через fetch-size
На кластере с большими топиками стоит уменьшить —fetch-size, чтобы проверка не создавала заметной нагрузки. Стандартный мегабайт — разумное значение, но для чувствительных production-систем в пиковые часы можно снизить до 256 КБ:
# Уменьшаем fetch-size для снижения нагрузки в пиковые часы kafka-replica-verification.sh \ --bootstrap-server localhost:9092 \ --topics-include "orders" \ --fetch-size 262144 \ --report-interval-ms 60000
Как интерпретировать результат
Вывод утилиты лаконичный — одна строка на итерацию с максимальным лагом среди всех проверяемых партиций. Нужно понимать, что именно означает каждое поле.
Разберём строку вывода по частям:
2025-04-01 12:05:30,123: max lag is 0 for partition orders-1 at offset 45231 among 6 partitions monitored
- max lag is 0 — максимальный лаг среди всех реплик всех проверяемых партиций. Именно максимальный, а не средний. Если хотя бы одна реплика отстаёт — вы это увидите.
- for partition orders-1 — партиция, у которой максимальный лаг на этой итерации. При нулевом лаге это просто последняя проверенная партиция.
- at offset 45231 — смещение, по состоянию на которое проводилось сравнение.
- among 6 partitions monitored — сколько партиций попало под проверку с учётом фильтра по топику. Проверьте это число — оно должно совпадать с ожидаемым количеством партиций.
Если лаг ненулевой и не уменьшается между итерациями — переходите к kafka-log-dirs.sh (урок 16) для детального анализа состояния реплик на каждом брокере.
Ограничения и когда использовать другие инструменты
У kafka-replica-verification.sh есть несколько ограничений, которые важно знать:
- Нет вывода по отдельным брокерам. Утилита показывает только максимальный лаг в целом, без разбивки по тому, какой именно брокер отстаёт. Для детализации нужен kafka-log-dirs.sh с флагом —topic-list.
- Нет исторических данных. Это инструмент для наблюдения в реальном времени, а не для анализа прошлого. Для мониторинга с историей подключайте Prometheus + JMX Exporter.
- Не видит ISR напрямую. Утилита сравнивает смещения, но не показывает напрямую, какие реплики входят в ISR. Для этого лучше подходит kafka-topics.sh —describe (урок 6).
- Создаёт реальную нагрузку. Fetch-запросы идут к брокерам напрямую. На кластере с сотнями топиков без фильтра это может создать заметный сетевой трафик.
Если нужно быстро проверить статус ISR и under-replicated partitions без Fetch-нагрузки, используйте kafka-topics.sh —describe —under-replicated-partitions — это легковесный запрос к метаданным:
# Быстрая проверка under-replicated partitions через kafka-topics.sh kafka-topics.sh \ --bootstrap-server localhost:9092 \ --describe \ --under-replicated-partitions
Пустой вывод этой команды означает, что в данный момент under-replicated партиций нет — все реплики в ISR.
Запуск на ограниченное время
Поскольку утилита работает непрерывно, для автоматизации удобно обернуть её в timeout. Например, для проверки в рамках CI/CD-пайплайна или скрипта обслуживания кластера:
# Запускаем проверку на 60 секунд, выводим результат в файл timeout 60 kafka-replica-verification.sh \ --bootstrap-server localhost:9092 \ --topics-include "orders|payments" \ --report-interval-ms 10000 \ | tee /tmp/replica-check-$(date +%Y%m%d_%H%M).log # Ищем ненулевой лаг в выводе grep -v "max lag is 0" /tmp/replica-check-*.log | grep "max lag"
Если grep ничего не нашёл — все итерации показали нулевой лаг. Если нашёл строки с ненулевым лагом — их стоит изучить подробнее.
Альтернативы и дополнение к утилите
В реальном production-мониторинге kafka-replica-verification.sh обычно не используется как единственный инструмент. Вот что работает рядом с ней или вместо неё в зависимости от задачи:
- JMX-метрика ReplicaManager/UnderReplicatedPartitions. Самый надёжный способ непрерывного мониторинга. Экспортируется через JMX, легко подключается к Prometheus через kafka-jmx-exporter. Алерт на значение > 0 — стандартная практика.
- kafka-topics.sh —describe —under-replicated-partitions. Быстрый ситуационный снимок без дополнительной нагрузки. Не видит величину лага, но показывает конкретные топики и брокеры.
- kafka-log-dirs.sh —topic-list <топик>. Даёт размер и смещения по каждой партиции на каждом брокере. Хорошо для детального расследования (урок 16).
- kcat -L. Показывает метаданные включая ISR для всех партиций. Быстрый и удобный для spot-проверки (урок 33).
Для разовой диагностики после обслуживания кластера kafka-replica-verification.sh удобна тем, что работает с любым JDK и не требует дополнительных зависимостей — она уже есть в стандартном bin/.
Apache Kafka: администрирование кластера
Код курса
KAFKA
Ближайшая дата курса
13 июля, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
Что дальше
В уроке 24 переходим к kafka-acls.sh — инструменту управления списками контроля доступа. Тема актуальная: без правильно настроенных ACL любой клиент с доступом к кластеру может читать и писать в любой топик.
Референсные ссылки
- Apache Kafka Documentation. Replication tools and monitoring (official docs, 2025)
- Apache Kafka Documentation. Monitoring Kafka: ReplicaManager metrics (official docs, 2025)
- GitHub. ReplicaVerificationTool.java — исходный код утилиты (Apache Kafka 4.x, 2025)
- Confluent Blog. Monitor Kafka replication lag with Prometheus and Grafana (Confluent, 2025)
- Confluent Developer. Kafka replicas, ISR and under-replicated partitions explained (Confluent, 2025)