 40
40 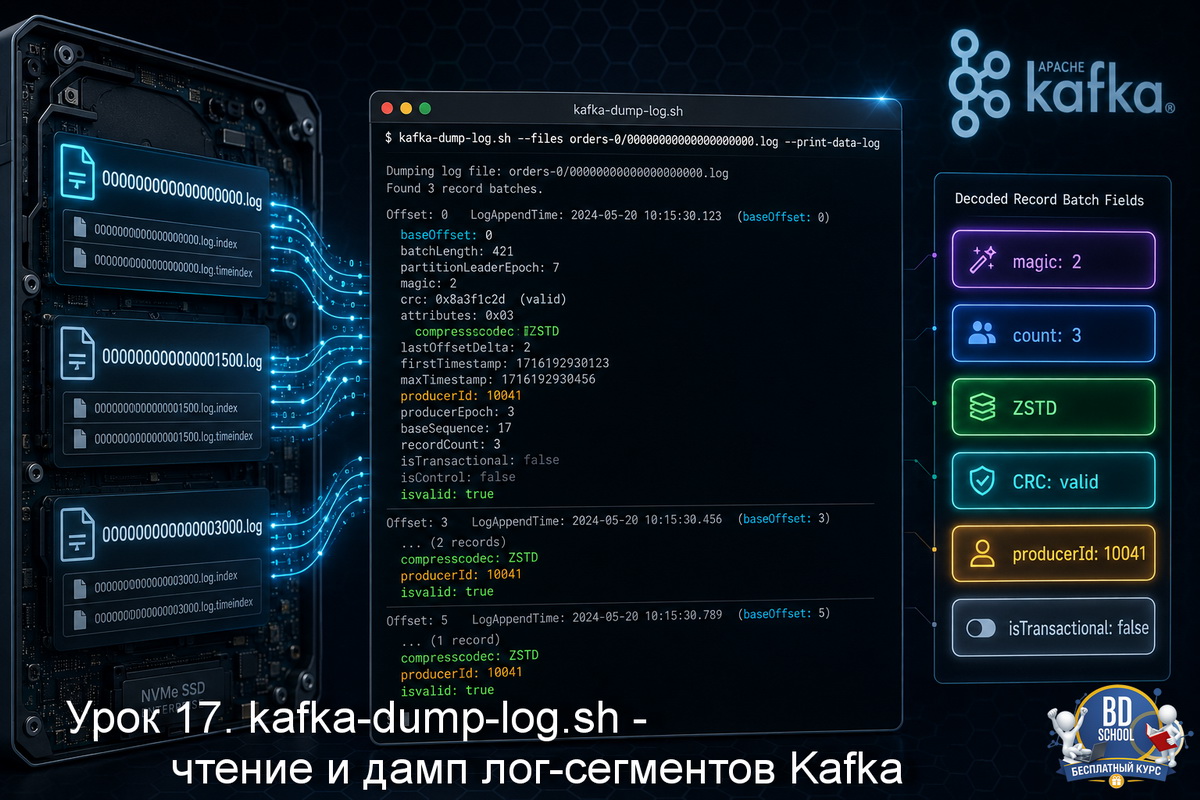
Содержание
- Что делает kafka-dump-log.sh
- Как Kafka хранит данные на диске
- Синтаксис и основные флаги
- Шаг 1. Смотрим заголовки батчей
- Шаг 2. Читаем содержимое сообщений
- Шаг 3. Внутри сжатых батчей
- Шаг 4. Служебные топики и метаданные KRaft
- Декодирование __consumer_offsets
- Декодирование метаданных KRaft
- Проверка индексных файлов
- Практические сценарии
- Анализ нескольких сегментов сразу
- Альтернативы kafka-dump-log.sh
- Что дальше
- Референсы
- Все уроки курса
В уроке 16 мы использовали kafka-log-dirs.sh, чтобы узнать, сколько места занимают партиции и в каких директориях они лежат. Утилита работает через API брокера и возвращает агрегированные метаданные. Это удобно, но иногда нужно копнуть глубже — посмотреть прямо в файл и понять, что именно там лежит.
kafka-dump-log.sh делает именно это. Она читает .log-файлы сегментов прямо с диска, минуя брокер, и выводит содержимое в человекочитаемом виде. Никакого подключения к кластеру не нужно — только путь к файлу.
Этот инструмент незаменим при отладке странного поведения консьюмеров, проблем с компрессией или подозрениях на повреждение данных. В курсе «Администрирование кластера Kafka» анализ сегментов лога разбирают в контексте диагностики инцидентов и восстановления после сбоев.
Что делает kafka-dump-log.sh
kafka-dump-log.sh — утилита для чтения и декодирования лог-сегментов Apache Kafka прямо с файловой системы. Она открывает бинарные .log-файлы, которые брокер записывает на диск, и выводит их содержимое в текстовом виде — заголовки батчей, офсеты, временные метки, идентификаторы продюсеров и, при необходимости, ключи и значения самих сообщений.
Утилита работает локально, без сетевого подключения к брокеру. Это значит, что её можно использовать на остановленном узле, при восстановлении после сбоя или при анализе архивных данных. Она понимает несколько форматов декодирования — обычный пользовательский лог, служебные топики __consumer_offsets и __transaction_state, а в KRaft-режиме — и метаданные кластера.
Как Kafka хранит данные на диске
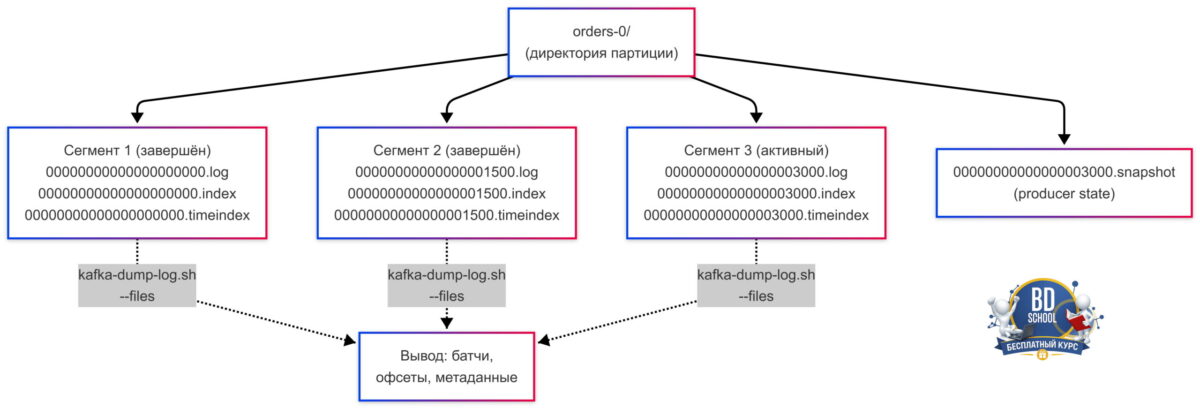
Прежде чем разбирать флаги, важно понять структуру файлов на диске. Каждая партиция — это отдельная директория в лог-директории брокера. Внутри лежат несколько типов файлов.
- .log. Основной файл сегмента — бинарные записи пачками (батчами). Именно его читает kafka-dump-log.sh.
- .index. Индекс офсетов — позволяет быстро найти позицию в .log-файле по офсету.
- .timeindex. Индекс по времени — для поиска по временной метке.
- .snapshot. Снимок состояния продюсера — нужен для exactly-once семантики.
- .txnindex. Индекс транзакционных прерываний — для поиска абортированных транзакций.
Файлы .log разделены на сегменты. Имя файла — это базовый офсет первой записи в сегменте. Например, 00000000000000001500.log начинается с офсета 1500. Активный (последний) сегмент брокер дозаписывает, завершённые — читать уже можно безопасно даже при работающем брокере.
Синтаксис и основные флаги
Единственный обязательный флаг — —files. Все остальные управляют режимом вывода и декодирования. Вот полный список параметров, которые пригодятся на практике.
| Флаг | Что делает | Обязательный |
|---|---|---|
| —files | Список .log-файлов через запятую — что читать | да |
| —print-data-log | Выводить содержимое записей — ключи и значения | нет |
| —deep-iteration | Итерироваться по отдельным записям внутри батчей (нужно при компрессии) | нет |
| —max-message-size | Максимальный размер сообщения в байтах (по умолчанию 5242880, то есть 5 МБ) | нет |
| —verify-index-only | Проверить индекс, не читая .log-файл | нет |
| —index-sanity-check | Быстрая проверка целостности индекса без полного дампа | нет |
| —offsets-decoder | Декодировать как лог топика __consumer_offsets | нет |
| —transaction-log-decoder | Декодировать как лог топика __transaction_state | нет |
| —cluster-metadata-decoder | Декодировать как KRaft metadata log (метаданные кластера) | нет |
Шаг 1. Смотрим заголовки батчей
Начнём с базового запуска без лишних флагов. Утилита прочитает .log-файл и выведет заголовок каждого батча (record batch) — группы записей, упакованных вместе.
# Найти .log-файл нужной партиции ls /var/lib/kafka/data/orders-0/ # Дамп заголовков батчей kafka-dump-log.sh \ --files /var/lib/kafka/data/orders-0/00000000000000000000.log
Вывод будет примерно таким.
Dumping /var/lib/kafka/data/orders-0/00000000000000000000.log Log starting offset: 0 baseOffset: 0 lastOffset: 2 count: 3 baseSequence: 0 lastSequence: 2 producerId: -1 producerEpoch: -1 partitionLeaderEpoch: 0 isTransactional: false isControl: false deleteHorizonMs: OptionalLong.empty position: 0 CreateTime: 1746000000000 size: 187 magic: 2 compresscodec: NONE crc: 2145678901 isvalid: true baseOffset: 3 lastOffset: 3 count: 1 baseSequence: -1 lastSequence: -1 producerId: -1 producerEpoch: -1 partitionLeaderEpoch: 0 isTransactional: false isControl: false deleteHorizonMs: OptionalLong.empty position: 187 CreateTime: 1746000001000 size: 79 magic: 2 compresscodec: NONE crc: 3012456789 isvalid: true
Разберём, что означает каждое поле в заголовке батча.
- baseOffset / lastOffset. Первый и последний офсет записей в этом батче. По ним видно, сколько сообщений попало в одну пачку.
- count. Количество записей в батче. Если продюсер отправлял по одному сообщению, будет 1. При батчевой отправке — больше.
- producerId / producerEpoch. Идентификатор продюсера. Значение -1 означает обычного продюсера без идемпотентности. Ненулевое значение — идемпотентный или транзакционный продюсер.
- partitionLeaderEpoch. Эпоха лидера, при которой записан батч. Используется для обнаружения «зомби»-записей при смене лидера.
- isTransactional. Принадлежит ли батч транзакции.
- isControl. Служебный управляющий батч (commit/abort транзакции, а не пользовательские данные).
- position. Байтовая позиция начала батча в файле. По ней строится .index-файл.
- CreateTime. Unix-timestamp в миллисекундах из заголовка батча. Может быть временем создания на продюсере или временем добавления на брокере.
- size. Размер батча в байтах, включая заголовок.
- magic. Версия формата записи. Значение 2 — актуальный формат (Record Batch), используется с Kafka 0.11+.
- compresscodec. Кодек сжатия батча. Варианты: NONE, GZIP, SNAPPY, LZ4, ZSTD.
- crc. Контрольная сумма батча для проверки целостности.
- isvalid. Результат проверки CRC. Значение false — батч повреждён.
Уже из заголовков батчей видно: какой кодек используется, есть ли транзакционные записи и нет ли повреждённых батчей.
Шаг 2. Читаем содержимое сообщений
Флаг —print-data-log добавляет к каждому батчу вывод отдельных записей — с ключами и значениями. Именно это нужно, когда хочется убедиться, что конкретное сообщение реально попало в лог.
# Дамп с выводом содержимого записей kafka-dump-log.sh \ --files /var/lib/kafka/data/orders-0/00000000000000000000.log \ --print-data-log
После заголовка батча появятся строки по каждой записи.
baseOffset: 0 lastOffset: 2 count: 3 ...
| offset: 0 CreateTime: 1746000000000 keySize: 8 valueSize: 42
sequence: 0 headerKeys: []
key: order-id payload: {"id":"a1b2","status":"new","amount":150.0}
| offset: 1 CreateTime: 1746000000100 keySize: 8 valueSize: 40
sequence: 1 headerKeys: []
key: order-id payload: {"id":"c3d4","status":"new","amount":75.5}
| offset: 2 CreateTime: 1746000000200 keySize: 8 valueSize: 46
sequence: 2 headerKeys: []
key: order-id payload: {"id":"e5f6","status":"pending","amount":200.0}
Если в записи есть заголовки Kafka (Headers API), они перечислятся в headerKeys. Для сообщений без ключа вместо значения ключа будет выведено null.
Шаг 3. Внутри сжатых батчей
При использовании сжатия Kafka упаковывает несколько записей в один батч и сжимает их вместе. Без —deep-iteration утилита покажет только заголовок батча, но не отдельные записи внутри. Добавляем оба флага вместе.
# Проверено: Apache Kafka 4.2.0, Ubuntu 22.04 # Дамп сжатого лога с итерацией по записям kafka-dump-log.sh \ --files /var/lib/kafka/data/orders-0/00000000000000000000.log \ --print-data-log \ --deep-iteration
Результат будет аналогичен предыдущему, но теперь утилита распакует батч и выведет каждую запись отдельно — даже если кодек GZIP или ZSTD. Без —deep-iteration при компрессии вместо содержимого записей будет только строка с размером сжатых данных.
Важный момент: —deep-iteration влияет только на отображение. Сжатые данные на диске остаются нетронутыми.
Apache Kafka: администрирование кластера
Код курса
KAFKA
Ближайшая дата курса
13 июля, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
Шаг 4. Служебные топики и метаданные KRaft
Кроме пользовательских топиков, Kafka хранит на диске несколько служебных. Их файлы тоже можно читать через kafka-dump-log.sh, но нужен специальный декодер — иначе вместо осмысленного текста будет набор байт.
Декодирование __consumer_offsets
Топик __consumer_offsets хранит зафиксированные офсеты консьюмер-групп. Флаг —offsets-decoder переключает декодирование в соответствующий формат.
# Найти файл нужной партиции __consumer_offsets ls /var/lib/kafka/data/__consumer_offsets-0/ # Декодировать как лог офсетов kafka-dump-log.sh \ --files /var/lib/kafka/data/__consumer_offsets-0/00000000000000000000.log \ --print-data-log \ --offsets-decoder
В выводе появятся записи вида GroupMetadata (состояние группы) и OffsetCommit (зафиксированный офсет). Это единственный способ заглянуть в хранилище офсетов напрямую, без консьюмера.
Декодирование метаданных KRaft
В KRaft-режиме метаданные кластера хранятся в специальном топике @metadata на контроллере. Флаг —cluster-metadata-decoder позволяет его читать.
# Дамп лога метаданных KRaft-контроллера kafka-dump-log.sh \ --files /var/lib/kafka/data/@metadata-0/00000000000000000000.log \ --cluster-metadata-decoder \ --print-data-log
Вывод будет содержать записи об изменениях топиков, партиций, брокеров и конфигураций — по сути, это журнал всех изменений в кластере.
Проверка индексных файлов
Kafka хранит рядом с .log-файлами два типа индексов. Если индекс повреждён, брокер может не стартовать или не находить нужные офсеты. kafka-dump-log.sh умеет проверять оба без полного дампа данных.
# Полная проверка индекса офсетов --verify-index-only # Быстрая проверка целостности (быстрее, чем --verify-index-only) kafka-dump-log.sh \ --files /var/lib/kafka/data/orders-0/00000000000000000000.log \ --index-sanity-check
Флаг —verify-index-only читает весь .log-файл и проверяет, что каждая запись индекса указывает на правильную позицию. —index-sanity-check только убеждается, что записи в индексе идут в правильном порядке — это быстрее, но менее детально. При проблемах брокер при старте сам пересоздаёт индексы, однако ручная проверка помогает разобраться в ситуации заранее.
Практические сценарии
Вот конкретные задачи, с которыми помогает kafka-dump-log.sh.
- Найти повреждённое сообщение. Запустить дамп с —print-data-log и искать батчи с isvalid: false — это батч с нарушенной CRC.
- Проверить, что реально используется сжатие. Смотреть поле compresscodec в заголовке батча. Если там NONE при ожидаемом ZSTD — сжатие не включилось на продюсере.
- Убедиться в идемпотентности продюсера. У идемпотентного продюсера producerId будет ненулевым и одинаковым для всей сессии. Меняется только baseSequence.
- Найти транзакционные и управляющие батчи. Признаки — isTransactional: true и isControl: true соответственно. Управляющие батчи содержат маркеры commit/abort, но не пользовательские данные.
- Проверить зафиксированные офсеты группы вручную. Декодировать __consumer_offsets с флагом —offsets-decoder и убедиться, что группа действительно зафиксировала нужный офсет.
- Восстановление данных без брокера. Если брокер не поднимается, можно прочитать данные прямо из .log-файлов и передать их дальше — хотя бы понять, что там было.
Все эти сценарии не требуют запущенного брокера — только доступ к файловой системе.
Анализ нескольких сегментов сразу
Если нужно прочитать несколько сегментов одной партиции подряд, их можно передать через запятую или использовать glob-шаблон через подстановку shell.
# Несколько файлов явно kafka-dump-log.sh \ --files /var/lib/kafka/data/orders-0/00000000000000000000.log,/var/lib/kafka/data/orders-0/00000000000000001500.log \ --print-data-log # Все сегменты партиции через подстановку kafka-dump-log.sh \ --files $(ls /var/lib/kafka/data/orders-0/*.log | tr '\n' ',' | sed 's/,$//') \ --print-data-log
Второй вариант удобен, когда сегментов много и перечислять их вручную нет смысла. Утилита читает файлы в том порядке, в котором они переданы — важно, чтобы это был правильный порядок по базовому офсету.
Альтернативы kafka-dump-log.sh
Задача чтения содержимого топиков решается и другими инструментами, но с важными отличиями.
| Инструмент | Требует брокера | Читает .log-файлы | Служебные топики |
|---|---|---|---|
| kafka-dump-log.sh | нет | да (напрямую) | да (с декодером) |
| kafka-console-consumer.sh | да | нет (через API) | только __consumer_offsets через formatter |
| kcat (kafkacat) | да | нет (через API) | ограниченно |
| hexdump / xxd | нет | да (байты) | нет (нечитаемо) |
Если брокер работает и нужно просто прочитать сообщения — kafka-console-consumer.sh проще. Если брокер недоступен или нужно смотреть низкоуровневые метаданные батчей — только kafka-dump-log.sh.
Apache Kafka для инженеров данных
Код курса
DEVKI
Ближайшая дата курса
24 августа, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
Что дальше
В следующем уроке разберём kafka-delete-records.sh — утилиту для удаления данных из партиций до указанного офсета. Это единственный стандартный способ освободить место в топике с retention by size или принудительно убрать устаревшие записи до истечения срока хранения.
Референсы
- Apache Kafka 4.2 Documentation — Log — официальная документация по структуре лог-сегментов и форматам файлов на диске.
- Apache Kafka 4.2 Documentation — Record Batch Format — спецификация формата RecordBatch (magic 2), включая описание всех полей заголовка батча.
- KIP-98 — Exactly Once Delivery and Transactional Messaging — KIP, описывающий producerId, producerEpoch и поля isTransactional / isControl в батчах.
- KIP-500 — KRaft and Metadata Log — контекст для понимания —cluster-metadata-decoder и формата метаданных KRaft.