 38
38 
Содержание
- Что такое kafka-storage.sh и зачем она нужна
- Три подкоманды утилиты
- Шаг 1. Генерация cluster ID через random-uuid
- Шаг 2. Форматирование хранилища через format
- Шаг 3. Проверка состояния через info
- Флаг --ignore-formatted и когда он нужен
- Форматирование в многонодовом кластере
- Что происходит при принудительном переформатировании
- Сравнение сценариев использования kafka-storage.sh
- Процесс инициализации KRaft-кластера
- Что дальше
- Референсные ссылки
- Все уроки курса
В уроке 9 мы разобрали kafka-server-start.sh и kafka-server-stop.sh — как запускать брокер в foreground и daemon-режиме, какие переменные окружения влияют на JVM и как правильно останавливать процесс без потери данных. Но прежде чем брокер вообще сможет стартовать в KRaft-режиме, нужно сделать один обязательный шаг — отформатировать хранилище метаданных.
Этот шаг мы уже делали в уроке 2 по инструкции. Настало время разобраться, что именно происходит за кулисами, что записывается на диск и почему без этого шага KRaft-брокер откажется запускаться. Всем этим занимается утилита kafka-storage.sh.
Понимание того, как устроено хранилище метаданных KRaft, — обязательная тема для администраторов Kafka. Глубже она разбирается в курсе «Администрирование кластера Kafka», включая сценарии восстановления после сбоев.
Что такое kafka-storage.sh и зачем она нужна
kafka-storage.sh — утилита для управления хранилищем метаданных KRaft. В отличие от большинства утилит из предыдущих уроков, она не работает с живым брокером через сеть. Она работает напрямую с файловой системой — читает и создаёт файлы в директории, указанной в параметре log.dirs конфигурации.
В KRaft-режиме метаданные кластера (список топиков, количество партиций, распределение реплик, ACL и многое другое) хранятся в специальном внутреннем топике __cluster_metadata. Этот топик — обычный Kafka-лог, но обслуживается не брокером, а контроллером. Перед первым запуском этот лог нужно инициализировать — присвоить кластеру уникальный идентификатор и создать служебный файл.
Если форматирование не выполнено, kafka-server-start.sh завершится с ошибкой: брокер увидит пустую директорию и откажется стартовать. Именно поэтому kafka-storage.sh всегда идёт в паре с командой запуска.
Три подкоманды утилиты
У kafka-storage.sh есть три рабочих подкоманды. Каждая из них отвечает за отдельный этап работы с хранилищем.
- random-uuid. Генерирует случайный UUID — уникальный идентификатор кластера. Этот идентификатор потом передаётся в команду форматирования.
- format. Форматирует директорию хранилища: создаёт служебный файл meta.properties и инициализирует структуру для лога метаданных.
- info. Показывает текущее состояние директории хранилища: отформатирована она или нет, какой cluster ID записан, версия метаданных.
На практике вы будете использовать их строго по порядку: сначала random-uuid, затем format, а info — для диагностики и проверки.
Apache Kafka: администрирование кластера
Код курса
KAFKA
Ближайшая дата курса
13 июля, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
Шаг 1. Генерация cluster ID через random-uuid
random-uuid — самая простая из трёх подкоманд. Она генерирует случайный UUID в формате Base64 и выводит его в stdout. Никаких файлов при этом не создаётся.
# Проверено: Apache Kafka 4.2.0, Ubuntu 22.04 kafka-storage.sh random-uuid
Вывод будет выглядеть примерно так:
xtzWnoMyEkahzrAFKnMzmg
Это строка из 22 символов — UUID, закодированный в URL-safe Base64. Он уникален для каждого кластера. Удобнее всего сразу записать его в переменную окружения, чтобы не копировать вручную.
# Проверено: Apache Kafka 4.2.0, Ubuntu 22.04 KAFKA_CLUSTER_ID=$(kafka-storage.sh random-uuid) echo $KAFKA_CLUSTER_ID
Этот приём особенно полезен при автоматизации — в скриптах развёртывания переменная передаётся напрямую в следующую команду без ручного вмешательства.
Шаг 2. Форматирование хранилища через format
Подкоманда format выполняет основную работу: инициализирует директорию хранилища для работы в KRaft-режиме. Без этого шага брокер не запустится.
# Проверено: Apache Kafka 4.2.0, Ubuntu 22.04 kafka-storage.sh format \ --cluster-id $KAFKA_CLUSTER_ID \ --config $KAFKA_HOME/config/kraft/server.properties
Два обязательных флага команды.
- —cluster-id (-t). UUID кластера, полученный на предыдущем шаге. Именно это значение будет записано в meta.properties и станет идентификатором кластера навсегда.
- —config (-c). Путь к файлу конфигурации брокера. Утилита читает из него параметр log.dirs, чтобы найти директорию для форматирования.
После успешного выполнения вы увидите сообщение вроде этого:
Formatting /tmp/kraft-combined-logs with metadata.version 4.0-IV3.
Теперь хранилище готово — брокер можно запускать.
Что именно записывается на диск
После форматирования в директории log.dirs появляется файл meta.properties. Это обычный текстовый файл в формате Java properties. Посмотреть его можно командой cat:
# Проверено: Apache Kafka 4.2.0, Ubuntu 22.04 cat /tmp/kraft-combined-logs/meta.properties
Содержимое файла выглядит так:
# #Thu May 01 12:34:56 UTC 2025 cluster.id=xtzWnoMyEkahzrAFKnMzmg node.id=1 version=1
Три ключевых поля этого файла.
- cluster.id. UUID кластера, который вы передали через —cluster-id. По нему брокер идентифицирует, к какому кластеру он принадлежит.
- node.id. Идентификатор узла, берётся из параметра node.id в server.properties. Должен быть уникальным в кластере.
- version. Версия формата хранилища. Меняется при мажорных обновлениях Kafka.
Кроме meta.properties, в директории создаётся поддиректория __cluster_metadata-0 — это партиция 0 внутреннего топика метаданных. В ней будет храниться Raft-лог с историей всех изменений кластера.
Шаг 3. Проверка состояния через info
Подкоманда info позволяет в любой момент проверить, в каком состоянии находится хранилище. Это особенно полезно при диагностике проблем с запуском брокера.
# Проверено: Apache Kafka 4.2.0, Ubuntu 22.04 kafka-storage.sh info \ --config $KAFKA_HOME/config/kraft/server.properties
Если хранилище отформатировано, вывод покажет cluster ID и версию метаданных:
Found log directory: /tmp/kraft-combined-logs: FORMATTED: cluster ID = xtzWnoMyEkahzrAFKnMzmg, metadata.version = 4.0-IV3 (3).
Если хранилище пустое — ещё не форматировалось:
Found log directory: /tmp/kraft-combined-logs: EMPTY
Статус EMPTY означает, что брокер при попытке старта выдаст ошибку. Нужно сначала выполнить format.
Apache Kafka: администрирование кластера
Код курса
KAFKA
Ближайшая дата курса
13 июля, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
Флаг —ignore-formatted и когда он нужен
По умолчанию kafka-storage.sh format завершится с ошибкой, если директория уже отформатирована. Это защита от случайного стирания метаданных живого кластера.
Log directory /tmp/kraft-combined-logs is already formatted. Use --ignore-formatted to skip this check.
Флаг —ignore-formatted отключает эту проверку. Если директория уже отформатирована, команда просто пропустит её без ошибки. Это полезно в двух сценариях.
- Скрипты развёртывания. Если скрипт запускается повторно (например, при перезапуске provisioning), форматирование не сломает уже настроенный узел.
- Docker и оркестраторы. При перезапуске контейнера с persistent volume хранилище уже будет существовать. Флаг позволяет переиспользовать его без ручной проверки.
# Безопасное форматирование - не затронет уже отформатированную директорию kafka-storage.sh format \ --cluster-id $KAFKA_CLUSTER_ID \ --config $KAFKA_HOME/config/kraft/server.properties \ --ignore-formatted
Важно понимать: —ignore-formatted не перезаписывает данные. Он просто говорит «если уже готово — пропусти». Принудительно перезаписать хранилище этот флаг не позволяет.
Форматирование в многонодовом кластере
При развёртывании кластера из нескольких узлов все брокеры должны получить одинаковый cluster ID. Это критически важно: узлы с разными cluster ID не смогут образовать кластер — они будут считать себя принадлежащими к разным кластерам.
Типичный порядок действий при инициализации кластера из трёх узлов такой.
- Генерация UUID. Выполняется один раз на любом из узлов — или вообще на отдельной машине. Главное — сохранить полученный UUID.
- Форматирование на каждом узле. Команда format запускается на каждом сервере отдельно, но с одним и тем же cluster ID и с конфигом именно этого узла.
- Запуск брокеров. После форматирования всех узлов можно запускать брокеры.
# --- Шаг 1: генерация UUID (один раз, на любой машине) --- KAFKA_CLUSTER_ID=$(kafka-storage.sh random-uuid) echo "Cluster ID: $KAFKA_CLUSTER_ID" # --- Шаг 2: форматирование на каждом узле (broker-1, broker-2, broker-3) --- # Выполнить на каждом сервере, передав одинаковый $KAFKA_CLUSTER_ID kafka-storage.sh format \ --cluster-id $KAFKA_CLUSTER_ID \ --config $KAFKA_HOME/config/kraft/server.properties # --- Шаг 3: проверка перед запуском --- kafka-storage.sh info \ --config $KAFKA_HOME/config/kraft/server.properties
На практике UUID удобно распространять через переменную окружения в системе управления конфигурацией — Ansible, Chef или аналогах. Именно так это делается в production-окружениях.
Что происходит при принудительном переформатировании
Если нужно полностью сбросить кластер и начать заново, хранилище можно переформатировать вручную. Для этого нужно сначала удалить содержимое директории, а затем выполнить format с новым или тем же UUID.
# ВНИМАНИЕ: команда удаляет все данные кластера безвозвратно # Использовать только на тестовых окружениях # Остановить брокер перед очисткой kafka-server-stop.sh # Удалить содержимое директории хранилища (не саму директорию) rm -rf /tmp/kraft-combined-logs/* # Сгенерировать новый UUID и отформатировать заново KAFKA_CLUSTER_ID=$(kafka-storage.sh random-uuid) kafka-storage.sh format \ --cluster-id $KAFKA_CLUSTER_ID \ --config $KAFKA_HOME/config/kraft/server.properties
После такого сброса кластер становится чистым — все топики, сообщения и конфигурации удалены. В учебных целях это удобно: быстрый способ вернуть Kafka в исходное состояние.
Сравнение сценариев использования kafka-storage.sh
Соберём основные сценарии в таблицу — чтобы сразу было понятно, какую комбинацию команд использовать в каждом случае.
| Сценарий | Команды | —ignore-formatted | Данные сохраняются? |
|---|---|---|---|
| Первый запуск одного узла | random-uuid + format | нет | н/д (данных ещё нет) |
| Первый запуск кластера (3 узла) | random-uuid (1 раз) + format на каждом узле | нет | н/д |
| Idempotent-скрипт развёртывания | format —ignore-formatted | да | да (существующие данные не трогаются) |
| Docker с persistent volume | format —ignore-formatted | да | да |
| Полный сброс тестового кластера | rm -rf + random-uuid + format | нет | нет (всё удаляется) |
| Проверка перед стартом | info | н/д | да (read-only) |
Для production-окружений всегда добавляйте —ignore-formatted в скрипты форматирования. Это страховка от случайного сноса данных при повторном прогоне автоматизации.
Apache Kafka для инженеров данных
Код курса
DEVKI
Ближайшая дата курса
24 августа, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
Процесс инициализации KRaft-кластера
Для наглядности — полная последовательность шагов от генерации UUID до готового к работе брокера.
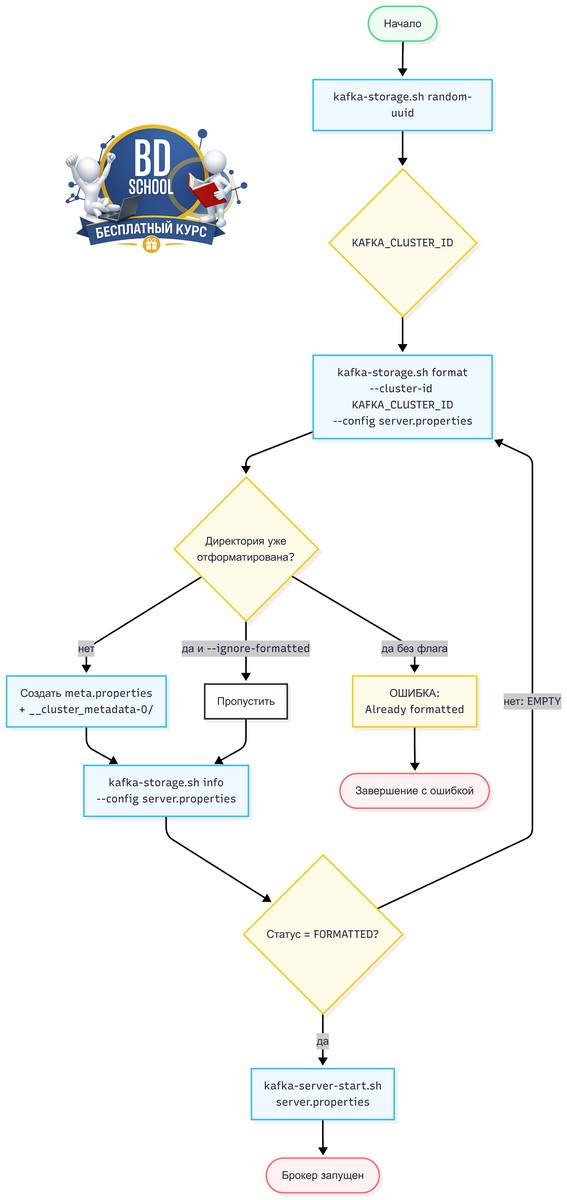
Что дальше
Теперь вы понимаете, что происходит с хранилищем до первого старта Kafka: как генерируется cluster ID, что записывается в meta.properties и как обеспечить идемпотентность при автоматическом развёртывании.
В уроке 11 разберём утилиту kafka-cluster.sh. Она позволяет получить идентификатор уже запущенного кластера через сеть — полезно для сверки с тем, что записано в meta.properties, и для диагностики проблем с membership в многонодовых конфигурациях.
Референсные ссылки
- Apache Kafka 4.2.0 — KRaft Storage Formatting (официальная документация)
- Apache Kafka 4.2.0 — KRaft Mode Overview (официальная документация)
- KIP-833. Mark KRaft as Production Ready (Apache Kafka Wiki)
- kafka-storage.sh — исходный код на GitHub (Apache Kafka)
- Apache Kafka — Migration from ZooKeeper to KRaft и форматирование хранилища (Release Notes)