 300
300 
Содержание
- Зачем изучать ZooKeeper-режим, если он уже не актуален?
- Архитектура за одну минуту
- Что понадобится
- Шаг 1. Установка Java
- Шаг 2. Загрузка и распаковка Kafka 3.9.2 и подготовка каталога для данных и логов Apache Kafka
- Шаг 3. Настройка ZooKeeper
- Шаг 4. Настройка Kafka-брокера
- Шаг 5. Запуск ZooKeeper
- Шаг 6. Запуск Kafka-брокера
- Шаг 7. Быстрая проверка работы
- Шаг 8. Корректная остановка
- Альтернатива: запуск через systemd
- Что здесь не так для продакшна
- Что дальше
- Референсные ссылки
Изучаем Apache Kafka с нуля. Урок 1. Установка с Zookeeper
Версии: Apache Kafka 3.9.0, Apache ZooKeeper (встроен в дистрибутив)
Окружение: Ubuntu 24.04 LTS, Java 17
Сложность: начальный уровень
Кто мы и зачем этот курс
Мы — команда bigdataschool.ru. Уже несколько лет мы обучаем инженеров и аналитиков работе с большими данными: Kafka, Spark, Hadoop, Airflow и всем, что окружает современный дата-стек.
За это время через наши курсы прошло немало студентов, и мы заметили одну закономерность: многие начинают изучение Kafka с середины. Читают статьи про консюмеров и продюсеров, смотрят видео про партиции — и всё равно через месяц не могут самостоятельно поднять локальный кластер и объяснить, зачем нужен ZooKeeper.
Этот бесплатный курс — наш ответ на этот пробел. Мы идём с самого начала: от установки одиночного узла до разбора каждой утилиты из каталога bin/. Всё на практике, всё с примерами, всё с объяснением «зачем», а не только «как». Курс рассчитан на тех, кто уже умеет работать в терминале и знает базовые команды Linux.
Примечание: Если в процессе изучения материала у Вас возникнет какой либо вопрос или вы захотите высказать пожелание или комментарий ( вдруг найдете неточность или ошибку) сообщите нам в Телеграм Группу созданную для Изучения Кафки, мы с удовольствием постараемся ответить на ваш вопрос в свободное время.
Хотите глубже — у нас есть платные продвинутые курсы
Бесплатный курс даёт прочную основу. Если вы хотите продвинуться дальше и работать с Kafka на профессиональном уровне, мы приглашаем на два специализированных курса.
KAFKA: Администрирование кластера Kafka — трёхдневный практический интенсив для администраторов, DevOps-инженеров и дата-инженеров. Вы научитесь разворачивать и настраивать распределённые кластеры Kafka 4.0 в KRaft-режиме, балансировать нагрузку, настраивать мониторинг через Prometheus + Grafana и управлять безопасностью кластера. 24 академических часа плюс 12 часов лабораторных работ.Подробности — на странице курса.
Apache Kafka: администрирование кластера
Код курса
KAFKA
Ближайшая дата курса
Продолжительность
24 ак.часов
Стоимость обучения
76 800
DEVKI: Apache Kafka для инженеров данных — пятидневный интенсив для разработчиков и дата-инженеров. Фокус на коде: Producer/Consumer API на Java и Python, Kafka Streams DSL, ksqlDB, Kafka Connect, Avro-сериализация и Schema Registry. 24 академических часа, реальные кейсы, которые можно применять сразу на работе. Подробности — на странице курса.
Apache Kafka для инженеров данных
Код курса
DEVKI
Ближайшая дата курса
24 августа, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
Зачем изучать ZooKeeper-режим, если он уже не актуален?
Если вы читаете это в 2026 году, наверняка возникнет вопрос, а зачем начинать с ZooKeeper, если в Kafka 4.0 его поддержка полностью убрана?
Причин несколько.
- Во-первых, огромное количество продуктивных кластеров до сих пор работает на связке Kafka + ZooKeeper.
- Во-вторых, понимание роли ZooKeeper помогает ощутить, какую именно проблему решает внешний координатор. Это делает KRaft-режим, который мы рассмотрим в уроке 2, гораздо понятнее — не как «просто новый способ», а как осознанный архитектурный выбор.
Kafka 3.9.2 — последняя версия ветки 3.x с официальной поддержкой ZooKeeper.
Архитектура за одну минуту
В ZooKeeper-режиме запущено два независимых процесса.
ZooKeeper — распределённый координатор. Он хранит метаданные кластера: список брокеров, конфигурации топиков, информацию о лидерах партиций. По сути это отдельная система с собственной базой данных (znodes), своими логами и конфигурацией.
Kafka-брокер — сам мессенджер. Принимает сообщения от продюсеров, хранит их в партиционированных логах и отдаёт консюмерам. При старте брокер регистрируется в ZooKeeper и с этого момента участвует в жизни кластера.
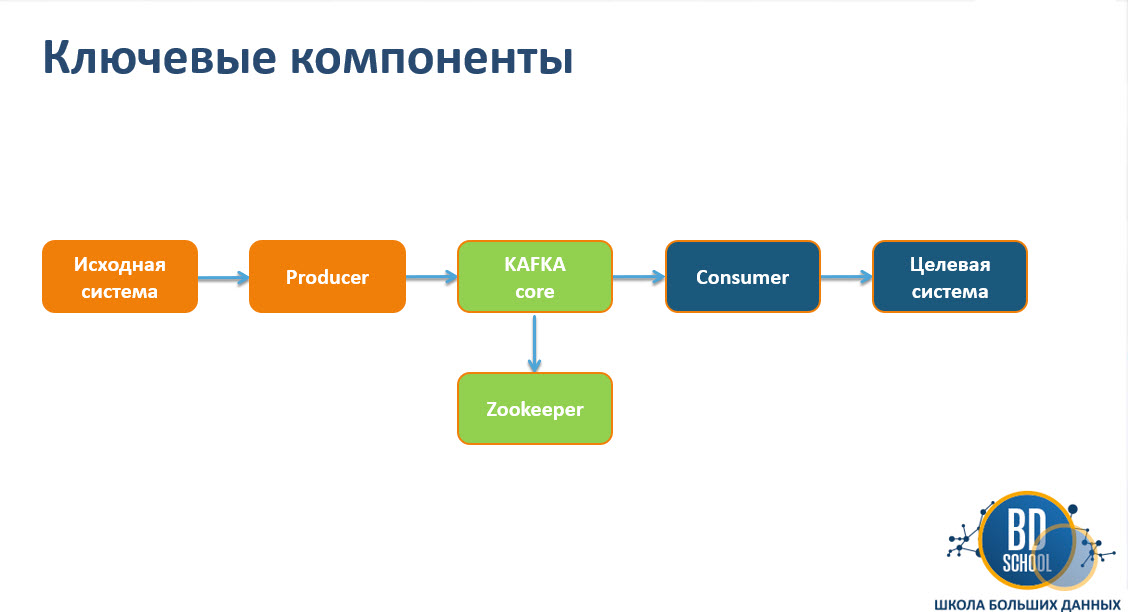
Для локальной установки оба процесса запускаются на одной машине. Для разработки и обучения этого достаточно.
Что понадобится
- Ubuntu 22.04 или 24.04
- Java 17 (рекомендуется; Java 11 тоже работает, Java 21 поддерживается с Kafka 3.7+)
- Минимум 2 ГБ RAM и 5 ГБ свободного места
- Права sudo
Шаг 1. Установка Java
Проверяем, есть ли уже Java в системе:
java -version #---Если команда не найдена или версия ниже 11 - ставим: sudo apt update sudo apt install -y openjdk-17-jdk #--- Проверяем результат: java -version # openjdk version "17.x.x" ...
Запускать Kafka и ZooKeeper от имени root — плохая практика. Любая уязвимость в JVM или самом брокере давала бы атакующему полный доступ к системе. Стандартный подход — создать выделенного системного пользователя без интерактивного входа и без домашнего каталога. Мы используем одного пользователяkafka для обоих сервисов. Это упрощает управление правами: оба процесса работают в одном контексте и пишут данные в одни и те же каталоги без ACL-конфликтов.
sudo useradd \ --system \ --no-create-home \ --shell /bin/false \ kafka
Флаги здесь важны.
—system создаёт служебный аккаунт с UID ниже 1000 — он не попадает в список обычных пользователей.
—no-create-home говорит системе не создавать /home/kafka — сервисному пользователю он не нужен.
—shell /bin/false блокирует любой интерактивный вход: даже если кто-то попытается зайти от имени этого пользователя, оболочка немедленно закроется.
Проверяем, что пользователь создан:
![]()
Шаг 2. Загрузка и распаковка Kafka 3.9.2 и подготовка каталога для данных и логов Apache Kafka
Скачиваем дистрибутив с официального зеркала Apache:
cd /opt sudo wget https://downloads.apache.org/kafka/3.9.2/kafka_2.13-3.9.2.tgz
Часть 2.13 в имени файла — версия Scala, под которую собран дистрибутив. На поведение Kafka это не влияет, выбирайте 2.13 как актуальную.
Распаковываем и убираем архив:
sudo tar -xzf kafka_2.13-3.9.2.tgz sudo mv kafka_2.13-3.9.2 kafka sudo rm kafka_2.13-3.9.2.tgz
Передаём каталог установки пользователю `kafka`. Это обязательный шаг — без него процесс не сможет писать логи в `bin/` и читать конфиги:
sudo chown -R kafka:kafka /opt/kafka

Ключевые каталоги:
- bin/ — все утилиты командной строки. С ними мы будем работать начиная с урока 5.
- config/ — конфигурационные файлы брокера и ZooKeeper.
- libs/ — jar-файлы Kafka.
- logs/ — логи процессов, создаётся при первом запуске.
В отличие от учебных руководств, где данные пишут в /tmp, мы сразу делаем правильно: создаём постоянные каталоги за пределами временного хранилища и отдаём их пользователю kafka.
Каталог для данных ZooKeeper:
sudo mkdir -p /var/lib/zookeeper sudo chown kafka:kafka /var/lib/zookeeper
Каталог для данных Kafka (партиционированные логи сообщений):
sudo mkdir -p /var/lib/kafka-logs sudo chown kafka:kafka /var/lib/kafka-logs
После этого оба процесса смогут читать и писать в свои каталоги без sudo.
Шаг 3. Настройка ZooKeeper
ZooKeeper идёт вместе с дистрибутивом Kafka — отдельно ничего устанавливать не нужно. Конфиг лежит здесь:
cat /opt/kafka/config/zookeeper.properties
Для локального одиночного запуска дефолтная конфигурация подходит без изменений. Разберём ключевые параметры:
# Постоянный каталог для данных ZooKeeper (snapshot'ы и transaction log) dataDir=/var/lib/zookeeper # Порт для подключения клиентов (в нашем случае - Kafka-брокера) clientPort=2181 # Максимальное число подключений с одного IP (0 = без ограничений) maxClientCnxns=0 # Базовая единица времени ZooKeeper в миллисекундах tickTime=2000 # Количество тиков для синхронизации фолловеров с лидером при старте initLimit=10 # Допустимое отставание фолловера от лидера в тиках syncLimit=5
dataDir=/tmp/zookeeper — данные не переживут перезагрузку системы. Для учёбы нормально, для постоянной работы лучше заменить на /var/lib/zookeeper.
Шаг 4. Настройка Kafka-брокера
Меняем log.dirs и раскомменируем listeners — остальные параметры оставляем по умолчанию:
sudo -u kafka nano /opt/kafka/config/server.properties
Основные параметры:
# Уникальный ID брокера в кластере. При одном брокере - всегда 0 broker.id=0 # Адрес и порт, на котором брокер принимает подключения listeners=PLAINTEXT://:9092 # Адрес, который брокер анонсирует клиентам # Если оставить закомментированным - берётся из listeners # advertised.listeners=PLAINTEXT://your-host:9092 # Постоянный каталог для хранения партиционированных логов сообщений log.dirs=/var/lib/kafka-logs # Количество партиций для новых топиков по умолчанию num.partitions=1 # Адрес ZooKeeper - здесь брокер регистрируется при старте zookeeper.connect=localhost:2181 # Таймаут подключения к ZooKeeper в миллисекундах zookeeper.connection.timeout.ms=18000 # Как долго хранить данные (по умолчанию 7 дней) log.retention.hours=168
Пока ничего не меняем — дефолты подходят для первого запуска.
Шаг 5. Запуск ZooKeeper
Запускаем ZooKeeper от имени пользователя `kafka` — Kafka не стартует без него:
sudo -u kafka /opt/kafka/bin/zookeeper-server-start.sh \ -daemon /opt/kafka/config/zookeeper.properties
Флаг —daemon запускает процесс в фоне. Логи пишутся в /opt/kafka/logs/zookeeper.out. Проверяем, что ZooKeeper поднялся:
grep "binding to port" /opt/kafka/logs/zookeeper.out

Шаг 6. Запуск Kafka-брокера
Теперь запускаем сервис Apache Kafka, так же под учетной записью kafka и проверяем функционирование
sudo -u kafka /opt/kafka/bin/kafka-server-start.sh \ -daemon /opt/kafka/config/server.properties
Проверяем в логе:

Оба процесса должны принадлежать пользователю kafka.
Шаг 7. Быстрая проверка работы
Мы ещё не разобрали утилиты bin/ подробно — это тема уроков 5-8. Но минимальную проверку сделаем прямо сейчас.
Создаём топик:
sudo -u kafka /opt/kafka/bin/kafka-topics.sh \ --bootstrap-server localhost:9092 \ --create \ --topic test-topic \ --partitions 1 \ --replication-factor 1
Отправляем несколько сообщений (первый терминал):
/opt/kafka/bin/kafka-console-producer.sh \ --bootstrap-server localhost:9092 \ --topic test-topic
После запуска появляется символ >. Вводите текст и нажимайте Enter. Завершить — Ctrl+C.

Читаем сообщения (второй терминал):
/opt/kafka/bin/kafka-console-consumer.sh \ --bootstrap-server localhost:9092 \ --topic test-topic \ --from-beginning

Подробно об этих трёх утилитах — в уроках 6, 7 и 8.
Шаг 8. Корректная остановка
Порядок важен: сначала останавливаем Kafka, потом ZooKeeper. Если сделать наоборот — брокер не успеет завершить работу корректно.
sudo -u kafka /opt/kafka/bin/kafka-server-stop.sh sudo -u kafka /opt/kafka/bin/zookeeper-server-stop.sh
Альтернатива: запуск через systemd
Запуск через sudo -u kafka удобен для экспериментов, но неудобен для постоянной эксплуатации. Systemd решает это автоматически: нужный пользователь задаётся прямо в юните, процессы поднимаются при старте системы и перезапускаются при падении.
Юнит для ZooKeeper:
sudo nano /etc/systemd/system/zookeeper.service #--- реадктируем содержимое [Unit] Description=Apache ZooKeeper After=network.target [Service] Type=simple User=kafka Group=kafka ExecStart=/opt/kafka/bin/zookeeper-server-start.sh /opt/kafka/config/zookeeper.properties ExecStop=/opt/kafka/bin/zookeeper-server-stop.sh Restart=on-failure RestartSec=5 LimitNOFILE=65536 [Install] WantedBy=multi-user.target
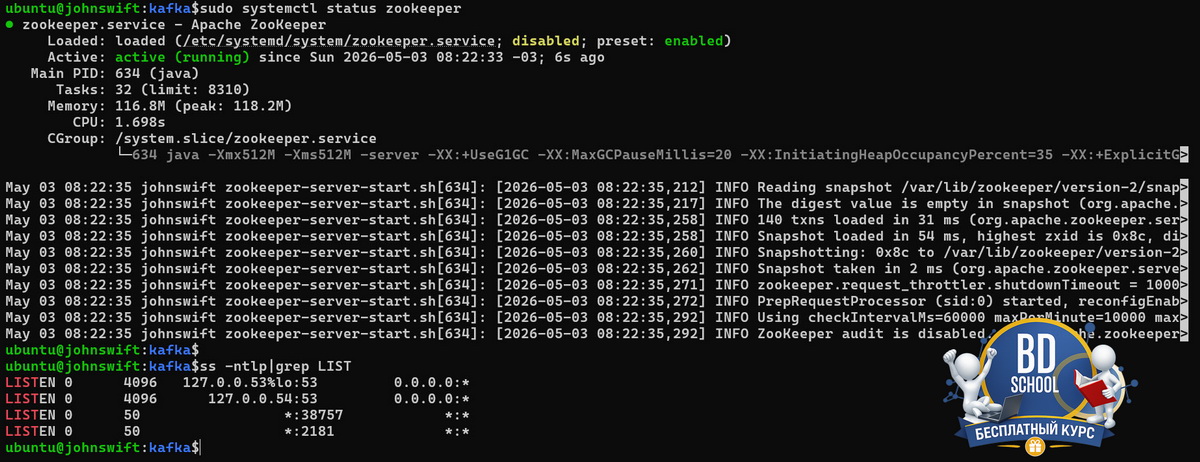
Юнит для Kafka:
sudo nano /etc/systemd/system/kafka.service #--- редактируем содержимое [Unit] Description=Apache Kafka Requires=zookeeper.service After=zookeeper.service [Service] Type=simple User=kafka Group=kafka ExecStart=/opt/kafka/bin/kafka-server-start.sh /opt/kafka/config/server.properties ExecStop=/opt/kafka/bin/kafka-server-stop.sh Restart=on-failure RestartSec=5 LimitNOFILE=65536 [Install] WantedBy=multi-user.target
Параметр LimitNOFILE=65536 увеличивает лимит открытых файловых дескрипторов для процесса. Kafka при нагрузке держит открытыми тысячи сегментных файлов — дефолтный системный лимит в 1024 быстро становится узким местом.
Включаем и запускаем:
sudo systemctl daemon-reload sudo systemctl enable zookeeper kafka sudo systemctl start zookeeper && sudo systemctl start kafka sudo systemctl status kafka
Убеждаемся, что systemd запускает процессы от нужного пользователя и все готово для дальнейшего использования.
Что здесь не так для продакшна
Наша установка годится для обучения. В реальных кластерах картина другая:
- ZooKeeper разворачивается отдельным ансамблем из 3 или 5 узлов для отказоустойчивости.
- Данные хранятся не в /tmp, а на выделенных дисках с отдельными точками монтирования.
- advertised.listeners настраивается явно с реальным FQDN брокера.
- Kafka и ZooKeeper изолированы на отдельные машины или контейнеры.
- Новые кластеры разворачиваются сразу в KRaft-режиме — без ZooKeeper.
Именно о KRaft пойдёт речь в следующем уроке.
Что дальше
В уроке 2 устанавливаем Apache Kafka 4.2.0 в режиме KRaft — без ZooKeeper, с контроллером, встроенным прямо в брокер. Разберём, что изменилось архитектурно и почему Apache в итоге отказался от внешнего координатора.
На всякий случай напоминаем что вы можете задать свои вопросы или сделать свои комментарии в нашей группе в TG LearnApacheKafka

Референсные ссылки
- Apache Kafka 3.9 Documentation — официальная документация по версии 3.9
- KIP-500: Replace ZooKeeper with a Self-Managed Metadata Quorum — оригинальный KIP с обоснованием отказа от ZooKeeper
- Apache ZooKeeper Administrator Guide — руководство администратора ZooKeeper
- Kafka Quickstart — официальный quickstart от Apache

