 50
50 
Содержание
- Что такое Raft-кворум и зачем его мониторить
- Подкоманды kafka-metadata-quorum.sh
- Шаг 1. Быстрая проверка через describe --status
- Шаг 2. Детальная диагностика через describe --replication
- Практические сценарии диагностики
- Сценарий 1. Фолловер отстал после перезапуска
- Сценарий 2. Проверка перед остановкой контроллера
- Сценарий 3. Рост LeaderEpoch как сигнал проблемы
- Что kafka-metadata-quorum.sh не умеет
- Что дальше
- Источники
- Все уроки курса
В уроке 11 мы разобрали kafka-cluster.sh — как получить cluster ID от работающего брокера и как корректно вывести брокер из KRaft-кластера через команду unregister. После вывода брокера логично проверить, что кворум не пострадал и кластер продолжает работать нормально. Именно для этого существует утилита следующего урока.
kafka-metadata-quorum.sh — инструмент для проверки состояния Raft-кворума в KRaft-режиме. Она показывает, кто сейчас лидер контроллеров, насколько отстают фолловеры и нет ли проблем с синхронизацией метаданных.
Умение читать вывод этой утилиты — обязательный навык для администратора Kafka. В курсе «Администрирование кластера Kafka» мы разбираем мониторинг кворума в контексте реальных сценариев: плановые работы, потеря нода, диагностика split-brain.
Apache Kafka для инженеров данных
Код курса
DEVKI
Ближайшая дата курса
24 августа, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
Что такое Raft-кворум и зачем его мониторить
В KRaft-режиме роль ZooKeeper выполняет встроенный алгоритм Raft. Несколько нодов с ролью контроллера выбирают лидера, который ведёт лог метаданных. Остальные контроллеры — это фолловеры: они реплицируют лог и готовы взять управление в случае падения лидера.
Пока всё это работает штатно, брокеры об этом не знают — они просто получают обновления метаданных. Но если фолловер начинает отставать, или в кластере не набирается кворум для принятия решений, операции с метаданными начинают зависать. Создать новый топик не получится. Увеличить партиции — тоже.
Три сценария, когда нужно заглянуть в состояние кворума.
- Плановое обслуживание. Перед остановкой контроллер-ноды убедитесь, что кворум выживет без неё.
- Диагностика подвисших операций. Если создание топика зависло — первым делом смотрите на кворум.
- После восстановления после сбоя. Убедитесь, что восставший нод догнал лидера и лаг ушёл в ноль.
Проверить всё это можно одной утилитой — kafka-metadata-quorum.sh.
Подкоманды kafka-metadata-quorum.sh
У утилиты одна рабочая подкоманда — describe. Режим работы задаётся флагом: что именно нужно показать.
| Флаг | Что показывает | Когда использовать |
|---|---|---|
| —status | Сводка по кворуму: лидер, эпоха, high watermark, максимальный лаг | Быстрая проверка — всё ли в порядке |
| —replication | Детальное состояние каждого нода кворума: офсет, лаг, время последнего ответа | Диагностика — кто именно отстаёт и насколько |
Оба флага работают с одним обязательным параметром — —bootstrap-server. Утилита подключается к любому живому брокеру и получает от него информацию о кворуме.
Apache Kafka для инженеров данных
Код курса
DEVKI
Ближайшая дата курса
24 августа, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
Шаг 1. Быстрая проверка через describe —status
Флаг —status — это первое, что запускают при диагностике. Одна команда, несколько секунд, сразу видно общую картину.
kafka-metadata-quorum.sh describe --status \ --bootstrap-server localhost:9092
Вывод будет выглядеть примерно так:
ClusterId: xtzWnoMyEkahzrAFKnMzmg LeaderId: 1 LeaderEpoch: 5 HighWatermark: 12438 MaxFollowerLag: 0 MaxFollowerLagTimeMs: -1 CurrentVoters: [1,2,3] CurrentObservers: []
Разберём каждое поле по порядку.
- ClusterId. UUID кластера — тот самый, что записан в meta.properties и выдаётся командой kafka-cluster.sh cluster-id.
- LeaderId. Node ID текущего лидера Raft-кворума. Это контроллер, который принимает решения по метаданным прямо сейчас.
- LeaderEpoch. Счётчик смены лидера. Каждый раз, когда кворум выбирает нового лидера, эпоха растёт на 1. Если эпоха быстро растёт — лидеры сменяются слишком часто, и это проблема.
- HighWatermark. Офсет в логе метаданных, до которого все участники кворума подтвердили запись. Все операции ниже этой отметки гарантированно зафиксированы.
- MaxFollowerLag. Максимальное отставание любого фолловера от лидера в записях лога. Ноль — норма. Больше нуля — кто-то не успевает.
- MaxFollowerLagTimeMs. То же самое, но в миллисекундах. Значение -1 означает, что лаг нулевой и время не измеряется.
- CurrentVoters. Node ID нодов, которые участвуют в голосовании кворума. Обычно это три контроллера.
- CurrentObservers. Node ID нодов, которые реплицируют лог метаданных, но не голосуют. В большинстве стандартных конфигураций этот список пустой.
Самые важные поля при быстрой проверке — MaxFollowerLag и LeaderEpoch. Если лаг ноль и эпоха не скачет — кворум здоров.
Шаг 2. Детальная диагностика через describe —replication
Флаг —status показывает агрегированные цифры. Если что-то не так, нужно понять — кто конкретно отстаёт. Для этого есть —replication.
kafka-metadata-quorum.sh describe --replication \ --bootstrap-server localhost:9092
Вывод — таблица с отдельной строкой для каждого нода кворума:
NodeId LogEndOffset Lag LastFetchTimestamp LastCaughtUpTimestamp Status 1 12438 0 1746194832000 1746194832000 Leader 2 12438 0 1746194832105 1746194832105 Follower 3 12438 0 1746194832210 1746194832210 Follower
Что означает каждая колонка.
- NodeId. Идентификатор ноды контроллера — тот же, что в server.properties в параметре node.id.
- LogEndOffset. Последний офсет в логе метаданных этой ноды. У лидера он самый актуальный.
- Lag. Разница между LogEndOffset лидера и данной ноды. Ноль — нода в полной синхронизации.
- LastFetchTimestamp. Unix timestamp последнего fetch-запроса этой ноды к лидеру. По нему видно, живёт ли нода и общается ли с лидером.
- LastCaughtUpTimestamp. Время, когда нода последний раз была полностью в синхронизации с лидером. Если оно давно в прошлом, а лаг растёт — нода не справляется.
- Status. Роль ноды: Leader, Follower или Observer.
Флаг —replication особенно важен перед плановым обслуживанием. Убедитесь, что все ноды в статусе Follower имеют Lag = 0 до того, как останавливать лидера или любой другой контроллер.
Apache Kafka: администрирование кластера
Код курса
KAFKA
Ближайшая дата курса
13 июля, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
Практические сценарии диагностики
Рассмотрим несколько ситуаций, с которыми сталкиваются на практике.
Сценарий 1. Фолловер отстал после перезапуска
После перезапуска контроллер-ноды она некоторое время догоняет лидера. Пока лаг не ушёл в ноль, лучше не трогать другие ноды кворума.
# Проверено: Apache Kafka 4.2.0, Ubuntu 22.04 # Следить за лагом в цикле с интервалом 5 секунд watch -n 5 "kafka-metadata-quorum.sh describe --replication \ --bootstrap-server localhost:9092"
Как только колонка Lag покажет ноль для всех нодов, нода вернулась в строй. Только после этого продолжайте плановые работы.
Сценарий 2. Проверка перед остановкой контроллера
Перед тем как остановить один из трёх контроллеров, убедитесь, что оставшихся двух хватит для кворума. При трёх нодах кворум — это большинство, то есть двое. Остановить одного — безопасно. Двух одновременно — нет.
# Проверить состояние перед остановкой kafka-metadata-quorum.sh describe --status \ --bootstrap-server localhost:9092 # Убедиться, что MaxFollowerLag = 0 # Убедиться, что в CurrentVoters ровно три ноды # Только потом останавливать один контроллер
Сценарий 3. Рост LeaderEpoch как сигнал проблемы
Если при каждом запуске —status значение LeaderEpoch заметно выросло по сравнению с прошлой проверкой — кворум нестабилен. Лидеры сменяются слишком часто. Это может быть связано с сетью, дисковой задержкой или неправильными таймаутами в конфигурации.
# Запросить эпоху и сохранить
EPOCH=$(kafka-metadata-quorum.sh describe --status \
--bootstrap-server localhost:9092 | grep LeaderEpoch | awk '{print $2}')
echo "LeaderEpoch: $EPOCH"
Если эпоха растёт быстро — смотрите логи контроллеров. Обычно там видно, какая нода инициирует перевыборы и по какой причине.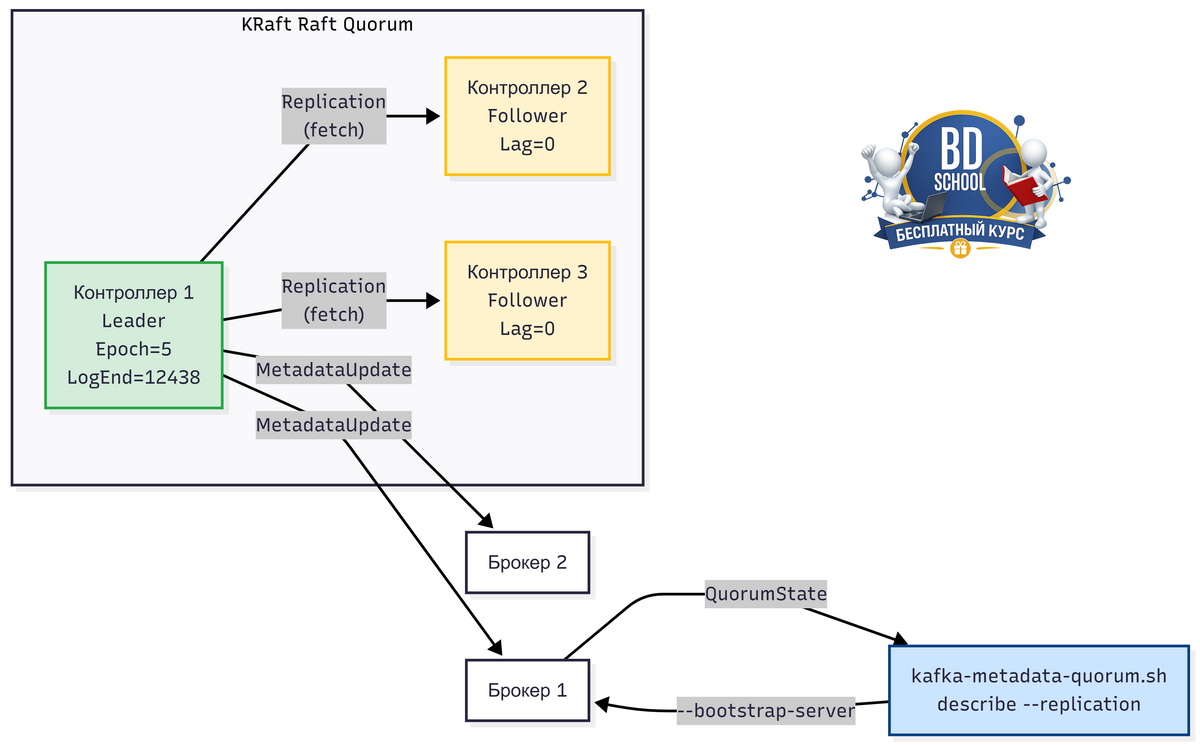
Что kafka-metadata-quorum.sh не умеет
Утилита только читает состояние — никаких изменений она вносить не может. Вот что нужно делать другими инструментами.
- Принудительная смена лидера. Это делается через kafka-leader-election.sh (урок 21) — но там речь о лидерах партиций, а не контроллеров. Смена лидера контроллеров происходит автоматически через Raft.
- Изменение состава кворума. Добавить или убрать контроллер нельзя на горячую через CLI. Это конфигурационное изменение с перезапуском.
- Просмотр содержимого лога метаданных. Для этого есть kafka-metadata-shell.sh (урок 13) — она позволяет буквально зайти внутрь лога и читать записи.
- Проверка версий протокола. За это отвечает kafka-broker-api-versions.sh (урок 25).
Если нужно получить состояние кворума программно, а не через CLI, — можно использовать Java AdminClient: метод describeMetadataQuorum() возвращает тот же набор данных в виде объекта. Это актуально для написания своих health-check скриптов и систем мониторинга.
Что дальше
Мы разобрали kafka-metadata-quorum.sh: научились читать вывод —status и —replication, понимать значение каждого поля и использовать утилиту для диагностики реальных ситуаций.
Следующий урок — kafka-metadata-shell.sh. Это интерактивный шелл для работы с логом метаданных KRaft изнутри. Там можно буквально зайти в кластер и посмотреть, какие записи хранятся в __cluster_metadata. Очень полезно при глубокой отладке. Смотрите урок 13. kafka-metadata-shell.sh.
Отдельный cheatsheet по всем флагам kafka-metadata-quorum.sh — в бонусном файле к этому уроку.
Если хотите разобраться с мониторингом кворума в продакшн-контексте — сценарии rolling restart, split-brain и плановый вывод нодов — это тема курса «Администрирование кластера Kafka».
Источники
- Apache Kafka 4.x Documentation. KRaft: Apache Kafka Without ZooKeeper
- Apache Kafka Documentation. Operations: Rolling Restart
- KIP-595. A Raft Protocol for the Metadata Quorum (Apache Kafka Wiki)
- Confluent. KRaft Mode: Kafka without ZooKeeper (2025)