1372
1372 
Содержание
Завершая сравнение SQL-инструментов для больших данных (Big Data), хранящихся в среде Hadoop, сегодня мы рассмотрим аргументы в пользу Apache Hive и Cloudera Impala – когда стоит выбирать ту или иную систему и почему. Также в этой статье мы собрали для вас несколько практических примеров реального использования Импала и Хайв в крупных Big Data проектах.
5 аргументов в пользу Apache Hive для аналитики Big Data
В большинстве случаев выбор Apache Hive в качестве основного SQL-средства для анализа данных, хранящихся в кластере Hadoop (HDFS или HBase), обусловлен ключевыми преимуществами этой системы относительно Cloudera Impala:
- отказоустойчивость, обеспечиваемая тем, что Хайв сохраняет все промежуточные результаты;
- высокая пропускная способность за счет LLAP (Live Long and Process) – кэширование запросов в памяти, что обеспечивает хорошую производительность на низком уровне, включая долговременные системные службы (демоны). Это позволяет напрямую взаимодействовать с узлами данных HDFS [1].
- повышенная (по сравнению с Импала) надежность и скорость обработки сложных SQL-запросов, реализуемая опять же благодаря LLAP и
MR3 – новому механизму выполнения (execution engine) для Hadoop и Kubernetes [2]; - расширяемость за счет вычислительной моделиMapReduce и определяемых пользователем функций – User Defined Function (UDF), User Defined Aggregate Function (UDAF), User Defined Tabular Function (UDTF) [3];
- отлаженная интеграция с Apache Ranger для гибкой RBAC-авторизации с возможностью задания собственных политик безопасности, например, на основе геолокации, опять же благодаря UDF. Об этом мы рассказывали здесь.
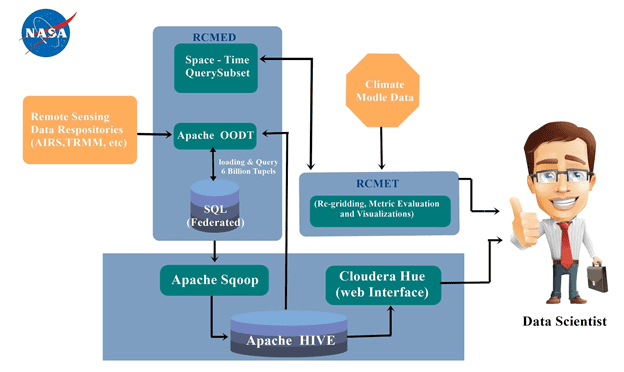
В связи с вышеперечисленными достоинствами Хайв активно применяется в масштабных Big Data проектах. Например, в соцсети знакомств Badoo, которая поддерживает множество языков и работает во всех странах мира, именно Apache Hive используется для ежедневного сбора суточных счетчиков пользователей, агрегации, фильтрации и ручного SQL-анализа данных, хранящихся в Hadoop [4]. Также стоит отметить опыт использования Hive в лаборатории реактивного движения научного центра NASA для построения и оценки климатической модели по данным дистанционного зондирования. Региональная система оценки климатической модели (RCMES) состоит из двух компонентов [5]:
- RCMED – региональная база данных оценки климатической модели: масштабируемая облачная база данных, которая загружает данные дистанционного зондирования и данные повторного анализа, которые связаны с климатом. Здесь данные преобразуются в точечную модель с координатами (широта, долгота, время, значение, высота) и сохраняются в Apache Hive. Клиент может получить пространственные или временные данные RCMED с помощью SQL-запросов.
- RCMET — региональный инструментарий оценки климатической модели, который позволяет пользователю сравнивать справочные данные из RCMED с выходными данными климатической модели, полученными из некоторых других источников, для выполнения различных видов анализа и оценки.
7 причин выбрать Cloudera Impala в качестве SQL-средства для Apache Hadoop
Как мы уже отмечали, Impala дополняет Hive, предоставляя удобный и быстрый способ анализировать большие данные, хранящиеся в Hadoop (HDFS, HBase) и другие распределенных файловых системах, в частности, Amazon S3. При этом главным плюсом Импала считается высокая скорость обработки простых SQL-запросов, обусловленная следующими факторами:
- вычислительная модель массовой параллельной обработки (MPP, Massive Parallel Processing), которая позволяет распараллеливать обработку данных в режиме онлайн, реализуя интерактивные вычисления;
- отсутствие записи на диск промежуточных результатов;
- трансляция SQL-запроса в исполнительный код во время выполнения (runtime);
- запуск системных служб (демонов) для обработки SQL-запросов во время загрузки (boot time).
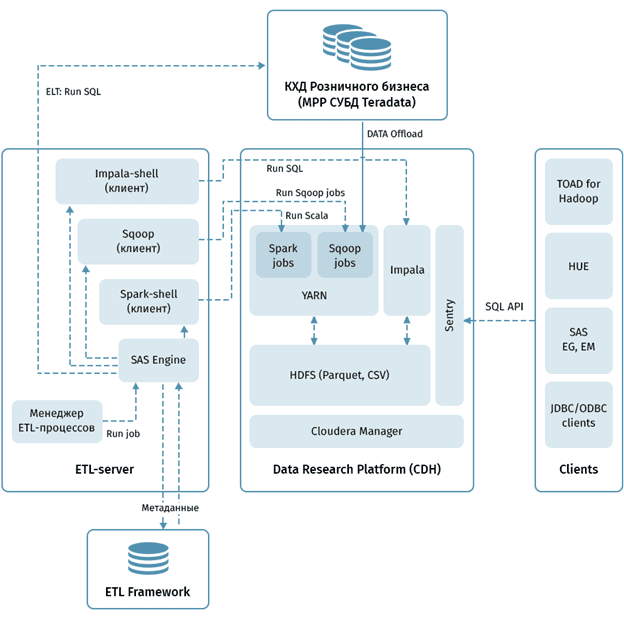
Также среди достоинств Impala можно назвать встроенную поддержку безопасного сетевого протокола аутентификации Kerberos, работу в многопользовательской среде с высокой конкуренцией запросов, кеширование часто запрашиваемых данных в памяти, приоритезацию и возможность управления очередью запросов. Благодаря этим качествам Impala широко востребована на практике для реализации ETL-процессов у аналитиков и ученых по данным (Data Analyst, Data Scientist). В частности, именно Cloudera Impala была выбрана банком ВТБ в качестве дополнительного ETL-инструмента при разгрузке корпоративного хранилища и озера данных (Data Lake) при построении собственной Big Data системы клиентской аналитики [6].
В заключение следует еще раз подчеркнуть, что Импала и Хайв не конкурируют друг с другом, т.к. ориентированы на разные задачи. Быстрота и удобство использования Impala компенсируются отказоустойчивостью и широкой расширяемостью Hive. Импала подходит для интерактивной аналитики в режиме реального времени с помощью множества простых SQL-запросов, а Хайв можно назвать идеальным инструментом для построения сложных ETL-конвейеров. В любом случае, при выборе той или иной платформы стоит, помимо функциональных характеристик самой системы, также учитывать контекст бизнеса, перспективы развития, текущие и будущие особенности эксплуатации.
Станьте профессионалом SQL-аналитики больших данных среды Hadoop, освоив администрирование, настройку и эффективную эксплуатацию Хайв и Импала на наших практических курсах в лицензированном учебном центре обучения и повышения квалификации ИТ-специалистов (менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data) в Москве:
Источники
- https://data-flair.training/blog/impala-vs-hive/
- https://mr3.postech.ac.kr/blog/2019/03/22/performance-evaluation-0.6/
- https://data-flair.training/blog/hive-udf/
- https://habr.com/ru/company/oleg-bunin/blog/319138/
- http://www.bigintellects.com/2018/08/hive-tutorial-hive-architecture-and/
- https://www.vtbcareer.com/article/ozero-dannih/