Почему задание Flink не обрабатывает потоковые данные из топика Kafka и при чем здесь водяные знаки: причины потери данных или растущей задержки вычислений и способы их решения.
Почему задание Flink не обрабатывает потоковые данные и при чем здесь водяные знаки?
Рассмотрим простой потоковый конвейер на Apache Flink и Kafka: задание Flink потребляет записи из топика Kafka, выполняет их агрегацию по времени и публикует результат в другой топик. После запуска задания данные в результирующем топике отсутствуют, хотя в исходном топике они есть. Такая ситуация часто возникает из-за проблем с водяными знаками (watermark).
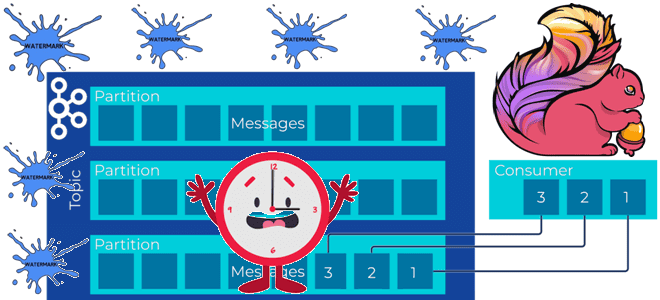
Напомним, топики Kafka разделены на разделы, где сообщения хронологически упорядочены. Сообщения в разделе будут потребляться в том порядке, в котором они были получены. Это гарантирует, что все записи для данного ключа раздела потребляются последовательно.
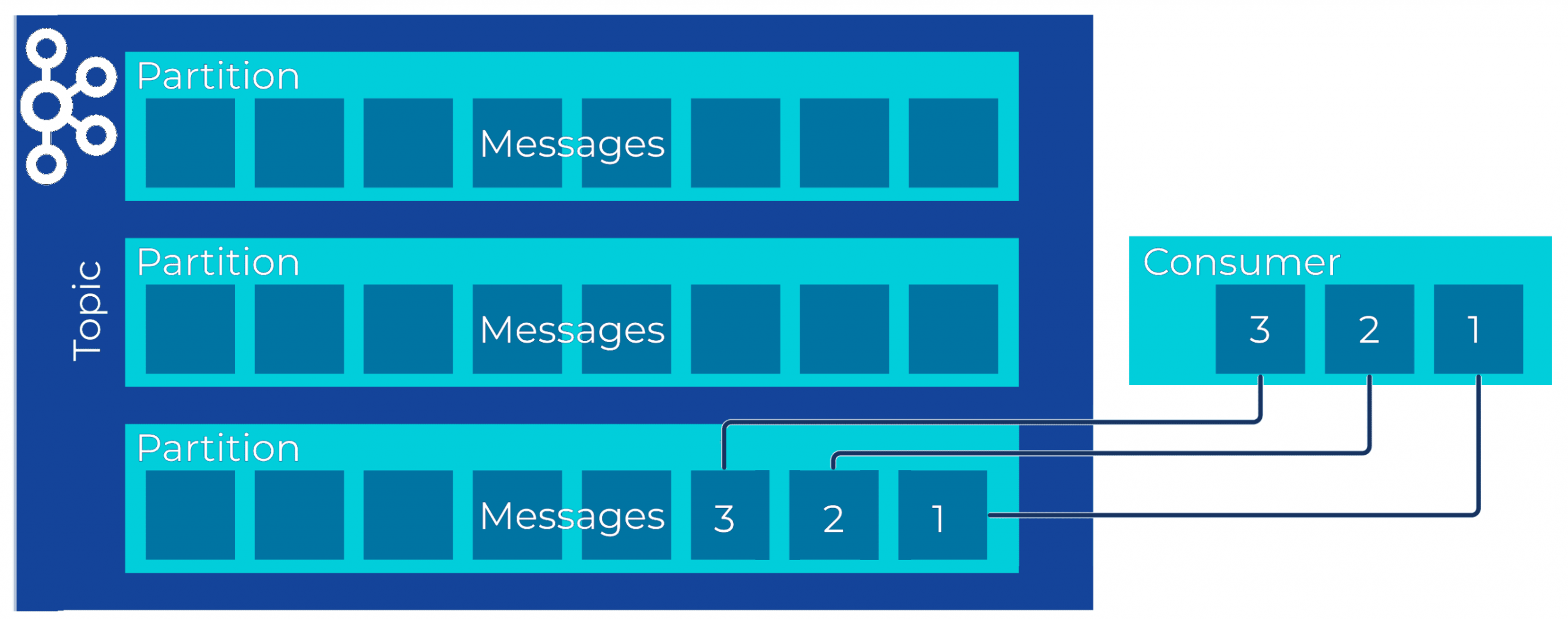
Однако, в Kafka отсутствует глобальное упорядочение, т.е. сквозное по всем разделам топика. Это означает, что параллельное потребление сообщений из нескольких разделов может привести к их неупорядоченной обработке. Для большинства задач это не имеет значения, например, фильтрация данных применяет условие к записям по мере их поступления, независимо от порядка появления.
Но в случае агрегаций по времени упорядочивание очень важно. Например, когда нужно найти максимальное значение поля в пределах одного минутного временного окна. По мере того, как каждая запись проходит через оператор, он сравнивает поле с текущим максимумом. Если он находит большее значение, он может обновить сохраненный максимум. Оператор ищет максимальное значение в пределах одной минуты, проверяя отметку времени у каждого сообщения, чтобы закрыть текущее окно обработки данных и открыть следующее. В упорядоченном потоке это не проблема. Но, когда сообщения приходят не по порядку, приходится делать выбор из следующих вариантов:
- закрыть окно;
- выдать новое сообщение и отбросить любые поздние сообщения из-за нарушения порядка;
- подождать с выдачей сообщения, ожидая прибытия опоздавших данных, т.е. тех, которые произошли раньше, чем конец окна, но поступили в обработку позже.
Для принятия решения Flink использует водяные знаки (watermarks), которые определяют максимальное время ожидания неупорядоченных сообщений. Обычно они рассчитываются как разница максимальной наблюдаемой отметки времени и допустимой неупорядоченности.
Примечательно, что watermark в DataStream Flink версии 2, а является особым событием, которое может быть настроено пользователем и может распространяться по потокам. Однако, изначально водяной знак – это механизм измерения задержки времени события и времени его обработки. В одной и той же программе текущее время события оператора может немного отставать от времени обработки из-за задержки в получении событий. Водяные знаки передаются как часть потока данных и несут временную метку t. Watermark(t) объявляет, что время события достигло времени t в этом потоке, что означает, что больше не должно быть элементов из потока с временной меткой t’ <= t, т. е. событий с временными метками старше или равными водяному знаку. Водяные знаки генерируются в исходных функциях или сразу после них. Каждая параллельная подзадача исходной функции обычно генерирует свои водяные знаки независимо. Эти водяные знаки определяют время события в этом конкретном параллельном источнике.
По мере того, как водяные знаки проходят через потоковую программу, они продвигают время события у операторов, к которым они поступают. Всякий раз, когда оператор продвигает свое время события, он генерирует новый водяной знак ниже по течению для своих последующих операторов. Таким образом, watermark — это особое событие, которое несет данные. Его источником может быть Source или ProcessFunction и он продвигается далее по нижестоящим операторам потока, определяя меру неупорядоченности событий появления и обработки данных.
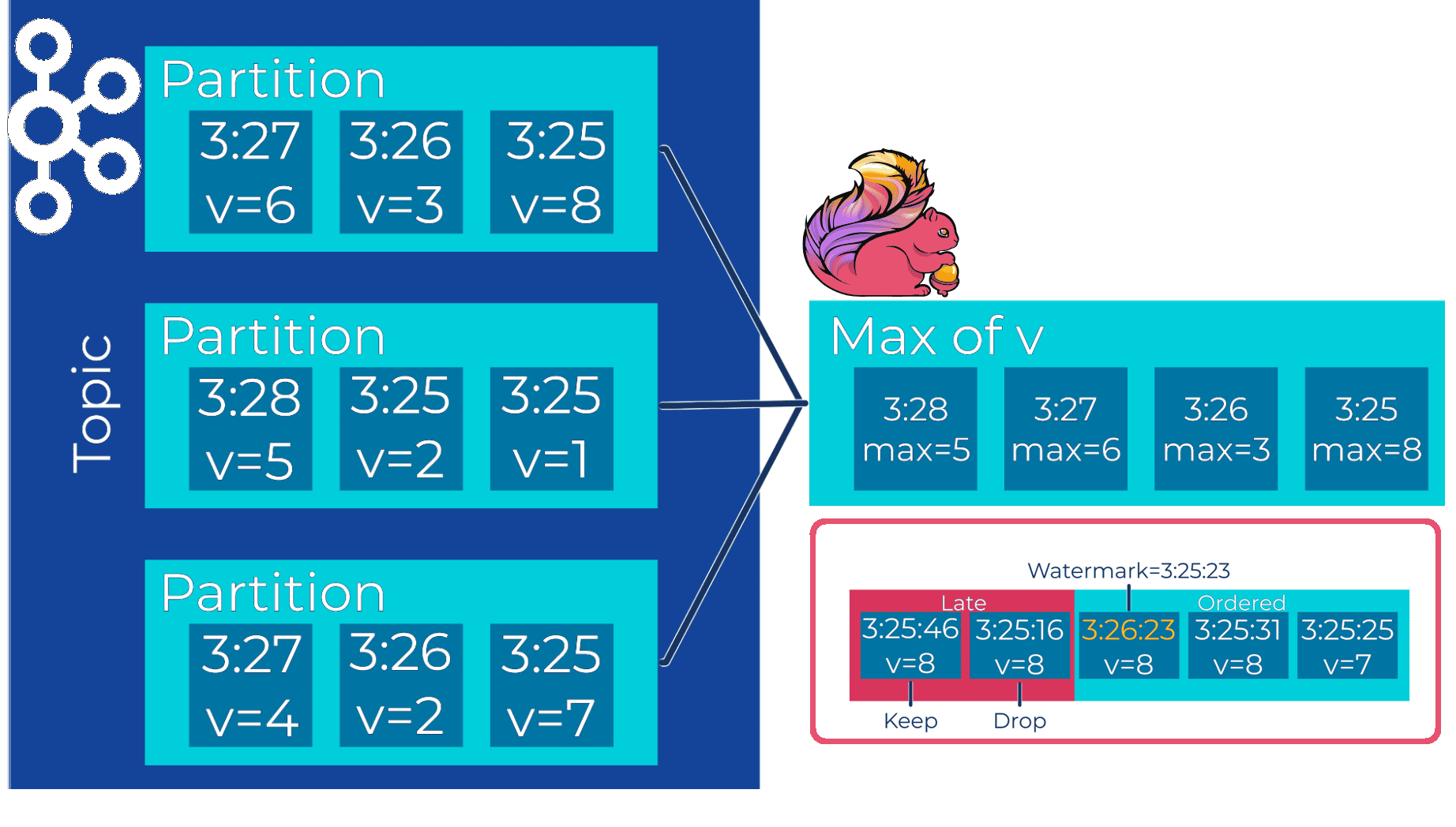
Например, установив неупорядоченность в одну минуту, при появлении сообщения в 3:26:23, водяной знак будет рассчитан как 3:25:23. Затем Flink использует его, чтобы решить, как поступить с оставшимися сообщениями. Когда приходит сообщение в 3:25:16, оно отбрасывается, потому что отметка времени меньше текущей watermark-метки. Если бы отметка времени равна текущей watermark-метке, запись все равно будет отброшена, потому что она должна быть больше водяной метки, чтобы ее сохранить. Это означает, что сообщение в 3:25:46 не будет отброшено. Окно будет закрыто только после того, как водяной знак перейдет за порог окна. Окно с 3:25:00 до 3:25:59 останется открытым, пока водяной знак не перейдет как минимум до 3:26:00.
Нарушение порядка сообщений в их потоковой обработке приводит к таким последствиям:
- опоздавшие сообщения могут быть потеряны;
- возрастает задержка обработки данных, поскольку задание ожидает поздние сообщения.
Поэтому для настройки watermark-стратегии надо искать баланс между потерей данных и задержкой. Увеличение порога неупорядоченности снизит потерю данных за счет дополнительной задержки их обработки. Подробнее про WatermarkStrategy во Flink-приложениях мы писали здесь. В API Flink DataStream можно определить задание, требующее водяных знаков, без определения их стратегии. Это предотвращает генерацию водяных знаков, т.е. задание не знает, как долго ждать опоздавших сообщений. Такое поведение по умолчанию приводит к вечному ожиданию, но без выдачи уведомлений об ошибках. Примечательно, что Table API и API SQL в Apache Flink имеют проверки для предотвращения ошибок такого типа.
Похожая проблема может возникнуть, если стратегия водяных знаков была настроена с неправильным полем отметки времени: оно не объявлено явно или объявлено неправильно. В итоге задание не может корректно рассчитать водяной знак, и в итоге будет ожидать вечно. Например, установка порога в 24 часа означает, что заданию потребуется обработать полные 24 часа данных, прежде чем выдать результат. Со стороны кажется, что задание зависло, но на самом деле оно выдаст результаты, т.к. на их подсчет нужно много времени.
Как неактивные разделы и потоки влияют на водяные знаки?
Когда Flink вычисляет водяные знаки, он вычисляет их отдельно для каждого раздела. Затем он использует минимальный водяной знак из всех разделов, чтобы определить общий водяной знак. Однако, сообщения распределяются по разделам топика Kafka неравномерно, например, по причине выбора такого ключа или раздел по какой-то причине заблокирован. Таким образом, раздел простаивает, в него не попадают новые сообщения и он не может участвовать в расчете общего водяного знака.
В таком случае Flink может игнорировать простаивающий раздел и вычислять водяной знак только на основе активных. Но, как только простаивающий раздел снова станет активным, в нем будет слишком много опоздавших сообщений. Все они будут проигнорированы заданием Flink, что приведет к значительной потере данных. С другой стороны, Flink может ожидать возобновления активности раздела, не выдавая общий результат. Таким образом, снова возникает поиск компромисса между потерей данных и задержкой их обработки. Если неактивный раздел никогда не становится активным, это может привести к тому, что задание никогда не даст результатов.
Можно настроить стратегию водяных знаков так, чтобы игнорировать неактивные разделы, если это необходимо. Однако, важно понять, почему раздел простаивает. Впрочем, помимо неактивных разделов могут возникнуть и неактивные потоки, тоже связанные с неравномерным трафиком. Предположим, что система выдает 200 событий в течение 20 секунд, а затем останавливается. А оконная операция делит поток на одноминутные окна. Если после начальных 200 событий больше не выдаются новые сообщения, окно не выдает результатов, т.к. водяные знаки продвигаются только при наличии поступающих событий. Всего через 20 секунд события перестают поступать. Однако, окно может закрыться только после того, как водяной знак достигнет порогового значения в одну минуту. Таким образом, поскольку водяной знак не обновляется, окно не закрывается, а выходной поток остается без результатов.
Чтобы избежать этого, в потоковых платформах обработки событий, таких как Confluent Cloud, сообщениям автоматически назначается отметка времени для расчета водяных знаков. Затем используется гистограмму наблюдаемых отметок времени для определения подходящего водяного знака, чтобы отбросить менее определенной доли, например, 5% опоздавших сообщений. В таком расчете есть некоторые ограничения:
- для генерации водяных знаков требуется минимум 250 сообщений на раздел;
- ожидание опоздавших данных нельзя задать менее 50 миллисекунд или более семи дней;
- ожидается, что данные будут поступать непрерывно.
Если эти условия не выполняются, стратегия водяных знаков по умолчанию, применяемая в Confluent Cloud не подойдет, и ее нужно настраивать отдельно. Такое обычно бывает, когда заданию необходимо использовать отметку времени, отличную от автоматически назначенной, или потеря сообщений не допускается. Как это сделать, рассмотрим в другой раз.
Освойте возможности Apache Flink для пакетной и потоковой аналитики больших данных и машинного обучения на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники

