 1164
1164 
Содержание
В прошлых выпусках мы рассмотрели, чем занимаются аналитик (Data Analyst), исследователь (Data Scientist) и инженер больших данных (Data Engineer). Завершая цикл статей о самых популярных профессиях Big Data, поговорим об администраторе больших данных – его рабочих обязанностях, профессиональных компетенциях, зарплате и отличиях от других специалистов. Итак, в сегодняшней статье – Administrator Big Data «для чайников».
Что делает администратор Big Data
Администратор больших данных занимается созданием и поддержкой кластерных решений (в том числе облачных платформ на базе Apache Hadoop), включая:
- установку и развертывание кластера;
- выбор начальной конфигурации;
- оптимизацию узлов на уровне ядра;
- управление обновлениями и создание локальных репозиториев;
- настройку репликаций, аутентификаций и средств управления очередями;
- обеспечение информационной безопасности кластеров;
- мониторинг производительности и балансировка нагрузки на серверы;
- обеспечение информационной безопасности кластеров и систем;
- резервное копирование и восстановление данных при сбоях.
При выполнении этих обязанностей администратор взаимодействует с инженерами больших данных, однако их рабочие задачи не дублируют друг друга, хотя и некоторым образом пересекаются. Чем занимается Data Engineer, читайте здесь.

Профессиональные компетенции администратора Big Data
Чтобы решать задачи по созданию, настройке и обслуживанию Big Data кластеров, администратор больших данных должен знать следующие дисциплины и технологии:
- сетевые протоколы стека TCP/IP, в т.ч. nginx, bash и пр.;
- языки программирования Python, Shell, Go;
- экосистема Apache Hadoop, а также кластерные решения HBase, Kafka, Spark;
- системы мониторинга Grafana, Zabbix, ELK, Prometheus;
- планировщики задач и балансировщики нагрузки Cloudera Manager, Apache Ambari, Apache Zookeeper;
- инструменты обеспечения кластерной безопасности Kerberos, Apache Sentry, Cloudera Navigator, Apache Ambari, Apache Ranger, Apache Knox, Apache Atlas;
- облачные платформы для больших данных (Amazon Web Services, Google Cloud Platform, Microsoft Azure и другие подобные решения от крупных PaaS/IaaS-провайдеров).
В некоторых компаниях к администратору больших данных также выдвигаются требования к знанию инструментов непрерывной интеграции и поставки ПО (CI/CD, Continuous Integration/ Continuous Delivery) – Jenkins, Puppet, Chef, Ansible, Docker, OpenShift, Kubernetes, а также средств для управления конфигурациями и тестированием (Terraform, Vault, Consul, Packer, Elasticsearch и пр.). Однако, такие задачи относятся к области ответственности DevOps-инженера, а Big Data Administrator занимается, прежде всего, настройкой кластерной инфраструктуры. Подробнее об отличиях DevOps-инженера от сисадмина и администратора больших данных мы рассказывали здесь. А про использование Docker, Kubernetes и другие технологии контейнеризации читайте в нашем новом материале.
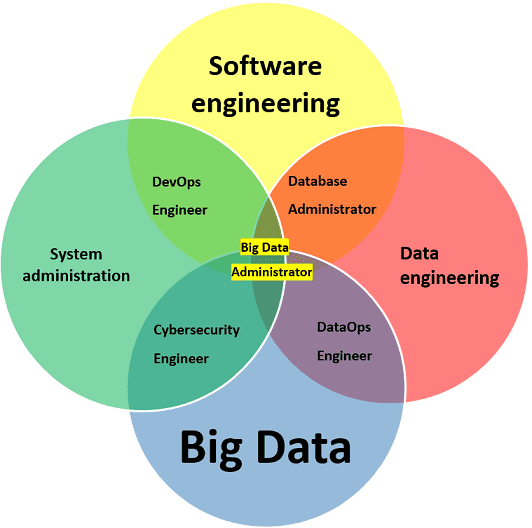
Чем отличаются друг от друга Data Engineer и администратор больших данных
Как и Data Engineer, администратор больших данных является частью инженерии Big Data, которая готовит инфраструктуру для анализа информации, чем занимаются Data Analyst и Data Scientist. Тем не менее, области профессиональной деятельности инженера и администратора больших данных существенно отличаются друг от друга:
- Data Engineer работает на более высоком уровне абстракции, концентрируясь на автоматизации сбора и распределения информационных потоков, а также взаимодействуя с корпоративными хранилищами информации (SQL и NoSQL базы данных, Data Lake, Data Warehouse);
- администратор Big Data настраивает и обслуживает инфраструктуру для хранения данных, создавая кластера и конфигурируя облачные платформы, а также заботится об информационной безопасности больших данных.
Отметим, что уровень зарплат этих ИТ-специалистов тоже отличается: обзор вакансий с популярной рекрутинговой площадки HeadHunter показал, что работа Data Engineer’а оценивается в 150-250 тысяч рублей в месяц, тогда как администратору больших данных предлагается месячный заработок 80-200 тысяч рублей. При этом, в связи с тотальной цифровизацией и цифровой трансформацией различных отраслей экономики, сохраняется тенденция нехватки опытных профессионалов. Впрочем, об этом мы уже упоминали в разговоре о профессиях в мире больших данных «для чайников», в статье «Big Data с чего начать».
Освойте искусство администрирования инфраструктуры больших данных на наших практических курсах обучения и повышения квалификации ИТ-специалистов в лицензированном учебном центре для руководителей, аналитиков, архитекторов, инженеров и исследователей Big Data в Москве:
- INTR: Основы Hadoop
- HADM: Администрирование кластера Hadoop
- DSEC: Безопасность озера данных Hadoop
- AIRF: Apache AirFlow
- NIFI: Кластер Apache NiFi
- KAFKA: Администрирование кластера Kafka
- HIVE: Hadoop SQL администратор Hive
- HBASE: Администрирование кластера HBase
- SPARK: Администратор кластера Apache Spark

