1288
1288 
Содержание
Несмотря на почти 20-летнюю историю термина «DevOps», даже в ИТ-среде до сих пор есть мнение, что все рабочие задачи этого девопс-инженера может выполнить рядовой системный администратор. Почему это не так и как обстоят дела с администрированием Big Data систем, читайте в нашей сегодняшней статье.
Критерии и источники данных для сравнения
Проанализировав описание вакансий на популярных рекрутинговых площадках (HeadHunter, Мой круг), мы составили список наиболее востребованных технологий для сисадмина, администратора Big Data и DevOps-инженера и отобрали следующие критерии сравнения этих специалистов:
- Главная цель и основные рабочие задачи;
- Время ключевые факторы возникновения профессии;
- Объекты работы;
- Необходимые компетенции (средства, инструменты и техники);
- Взаимодействие с другими участниками процессов разработки и эксплуатации ИТ;
- Заработная плата.
По результатам этого сравнения сделаны выводы о наиболее часто встречающейся прикладной направленности данных специальностей и возможности их взаимной замены.
Сравнительный анализ работы сисадмина, администратора Big Data и DevOps-инженера
Исторически эти 3 специализации возникли в разное время и по различным причинам:
- профессия системного администратора появилась в 80-90 гг. XX века, когда крупные фирмы стали устанавливать у себя компьютерную технику, требовавшую постоянного обслуживания;
- потребность в DevOps-инженерах сформировалась в начале XXI века (2000-е годы), когда в ИТ-мире больших корпораций возникла проблема рассогласования рабочих процессов;
- администраторы Big Data стали востребованы во 2-ой декаде XXI века (после 2010-го года), когда технологии Big Data стали стремительно развиваться и использоваться на практике.
Таким образом, прикладные сферы ответственности и объекты работы этих специалистов немного отличаются друг от друга:
- системный администратор работает с программным и аппаратным обеспечением персональных компьютеров конечных пользователей, сетевыми и периферийными устройствами;
- администратор Big Data взаимодействует с кластерами Apache Hadoop, облачными сервисами и виртуальные серверами;
- DevOps-инженер занимается конфигурированием рабочих, тестовых и production- серверов.
В рамках своей работы специалисты взаимодействуют с разными категориями участников ИТ-процессов:
- системный администратор, в основном, работает с конечными пользователями и руководством, например, для приобретения нового программного или аппаратного обеспечения;
- администратор Big Data относится к группе Data Professional’ов, сотрудничая с аналитиками и инженерами больших данных, Data Scientist’ами, а также разработчиками ПО;
- DevOps-инженер имеет дело с разработчиками и тестировщиками ПО, а иногда сам выполняет часть их рабочих задач.

Цели и задачи специалистов
Главная цель работы системного администратора – это обеспечение штатной работы компьютерной сети, аппаратного и программного обеспечения, а также информационной безопасности в организации. Целью администратора Big Data является обеспечение бесперебойной работы ИТ-инфраструктуры для Big Data систем, в т.ч. с точки зрения безопасности. А DevOps-инженер нацелен на обеспечение адаптивной и бесшовной интеграции процессов разработки, тестирования, развертывания и сопровождения приложений и сервисов.
К основным задачам сисадмина относятся:
- настройка и сопровождение локальной сети предприятия;
- установка, мониторинг и конфигурирование аппаратного и программного обеспечения, операционных систем и приложений, а также их обновлений;
- создание и поддержание в актуальном состоянии пользовательских учётных записей;
- резервирование данных, их периодическая проверка и уничтожение;
- обеспечение информационной безопасности в компании;
- администрирование корпоративных серверов (почтового, веб-сервера);
- ремонт аппаратной части компьютеров и периферийных устройств;
- техническая поддержка пользователей.
Администратор Big Data выполняет:
- создание и сопровождение ИТ-инфраструктуры для Big Data систем;
- конфигурирование локальных и облачных кластеров Hadoop;
- настройка облачных сервисов, платформ и инфраструктурных решений для Big Data;
- администрирование БД для Big Data;
- развертывание ETL-систем и корпоративных хранилищ данных;
- разработка и реализации политики управления пользователями Big Data систем;
- обеспечение информационной безопасности кластеров;
- мониторинг производительности и балансировка нагрузки на серверы;
- обеспечение информационной безопасности кластеров и систем;
- резервное копирование и восстановление данных при сбоях.
DevOps-инженер отвечает за:
- развертывание поставленного разработчиками релиза;
- установка, конфигурирование и обеспечение корректной работы веб-серверов и серверов инфраструктуры разработки;
- стандартизация окружения разработки;
- подготовка продуктивной среды к частым внесениям изменений;
- автоматизация процессов тестирования и развертывания;
- создание системы непрерывной интеграции проекта (CI);
- обеспечение бесперебойной работы и высокой доступности приложений;
- масштабирование приложений;
- резервное копирование и мониторинг сервисов и серверов.

Наиболее востребованные технологии
В таблице показаны наиболее популярные и востребованные технологии. Цветом отмечены те методы и средства, которые частично или полностью пересекаются у различных специалистов.
|
Системный администратор |
Администратор Big Data |
DevOps-инженер |
|
Специфические технологии |
||
|
серверное и сетевое оборудование (Cisco, HP, Dell, IBM) |
Hadoop и другие продукты Apache Software Foundation для Big Data (HBase, Kafka, Spark, Flume, и т.д.); |
Управление инфраструктурой, конфигурациями и тестированием (Terraform, Vault, Consul, Packer, Jenkins, Elasticsearch) |
|
скрипты (bash, MS Power Shell, VMWare vSphere, MS Hyper-v, MS SCCM, MS SCOM) |
ETL-системы и корпоративные хранилища данных |
|
|
стек протоколов TCP/IP и сопутствующие технологии |
||
|
nginx, nfs, NAT, FTP, dns, iptables, bash |
nginx, bash |
nginx, bash |
|
Специфические технологии |
стек Continuous Integration и Continuous Delivery (CI/CD) – непрерывная интеграция и поставка ПО |
|
|
OC (Windows, Unix, Linux, BSD, MacOS, CentOS) |
Puppet, Chef, Ansible, Docker, Kubernetes |
Puppet, Chef, Ansible, Docker, OpenShift, Kubernetes |
|
управление пользователями (DAP, Active Directory) |
облачные сервисы и платформы |
|
|
|
OpenStack, Cloudwatch, AWS |
OpenStack, Cloudwatch, AWS |
|
Системы мониторинга |
||
|
Zabbix, Prometheus |
Grafana, Zabbix, ELK, Prometheus |
Grafana, Zabbix, ELK, Prometheus |
|
Языки программирования |
||
|
Python, SQL, Shell |
Python, Shell, Go, HiveQL, SQL |
Python, Go |
|
СУБД |
||
|
MS SQL, MySQL |
кластерная СУБД HP Vertica, PostgreSQL и NoSQL (MongoDB, Aerospike, Cassandra и т.д.) |
PostgreSQL |
|
Управление проектами и инцидентами |
||
|
Управление заявками Service Desk, процессный подход ITIL |
Проектный подход Agile (Scrum, Kanban), система JIRA |
Проектный подход Agile (Scrum, Kanban), системы JIRA JIRA, GitLab |
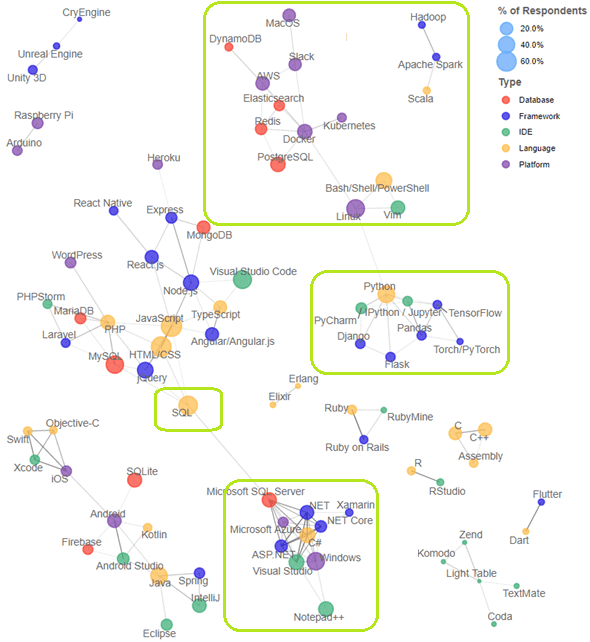
Связь некоторых технологий наглядно показывает ежегодный отчет Stack Overflow о разработке и разработчиках ПО. На рисунке из исследования 2019 года мы выделили стеки, наиболее востребованные в работе сисадмина, администратора Big Data и DevOps-инженера.
Различные области ответственности и сложности технологий у 3-х профессий обусловливают существенную разницу в уровне зарплат. Точные цифры зависят от региона и специфики компании, однако наиболее часто в России встречаются следующие оклады:
- системный администратор получает от 40 до 90 тысяч рублей;
- администратор Big Data зарабатывает 80-200 тысяч рублей;
- DevOps-инженер оценивается в 50 – 220 тысяч рублей.
Подведем итоги
Итак, все специалисты имеют дело с программным обеспечением, однако сисадмин также работает с аппаратной частью и сетевыми устройствами. DevOps-инженер находится ближе к разработке, чем к эксплуатации, а администратор Big Data отвечает за работоспособную инфраструктуру систем обработки и хранения больших данных. При этом администратор Big Data является более узким специалистом, чем сисадмин и DevOps-инженер.
С точки зрения организации работы, DevOps-инженер функционирует в условиях проекта, т.е. его рабочее окружение зависит от текущей задачи и может меняться в случае разных продуктов. А, поскольку подход девопс основан на принципах Agile, логично, что DevOps-инженеру необходимы знания методов Scrum, Kanban, системы отслеживания ошибок JIRA JIRA и управления репозиториями кода GitLab. Работа системного администратора более стабильна и соответствует процессному подходу, что отлично описывает библиотека лучших практик ИТ-управления ITIL и служба поддержки пользователей Service Desk. Администратор Big Data работает как в рамках временных проектов, так и в качестве лица, сопровождающего инфраструктуру больших данных на постоянной основе.
Различные цели, задачи и прикладные объекты деятельности DevOps-инженера, сисадмина и администратора Big Data обусловливает разные компетенции этих специалистов. Даже при том, что некоторые обязанности и используемые технологии частично пересекаются, не стоит говорить, что грамотный сисадмин всегда заменит любого DevOps-инженера и администратора Big Data. В крупных data driven компаниях, как правило, присутствует каждый из этих профессионалов. В стартапах и мелком бизнесе системный администратор часто совмещает все роли. А средние предприятия, в зависимости от своей специфики, наделяют администратора база данных обязанностями конфигурирования и поддержки Big Data систем.
В целом, услуги DevOps-инженер пока обходятся дороже, чем работа администратора Big Data и сисадмина. Этот факт обусловлен повышенным спросом на данную молодую профессию и вовсе не умаляет ценности других специалистов. А что ждет девопс-инженеров в будущем, читайте в нашей новой статье.

Прокачайте знания в DevOps, администрировании кластера Hadoop и других компонентах ИТ-инфраструктуры для больших данных, чтобы повысить свою стоимость на рынке труда, на наших практических курсах обучения в учебном центре для руководителей, аналитиков, архитекторов, инженеров и исследователей Big Data в Москве.