 840
840 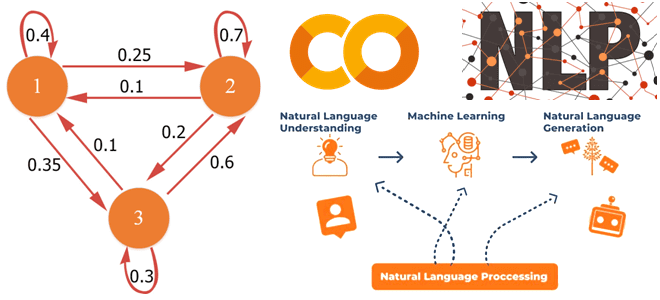
Содержание
В этой статье для обучения аналитиков данных и специалистов по Data Science рассмотрим, что такое цепь Маркова, где это используется в практических приложениях и с помощью каких инструментов можно реализовать этот граф состояний. В качестве примера рассмотрим генерацию фраз из небольшого текста с помощью методов библиотеки markovify в интерактивном блокноте Google Colab.
Что такое цепь Маркова и где это используется на практике
Начнем с определения: цепь Маркова — это последовательность случайных событий с конечным числом исходов, причем вероятность наступления каждого события зависит только от предыдущего состояния. Можно сказать, что в марковских цепях при фиксированном настоящем будущее состояние независимо от прошлого. Визуально цепь Маркова представляет собой направленный взвешенный граф, вершинами которого являются события (состояния), а ребрами – переходы между ними, которые могут случиться с определенной вероятностью. С математической точки зрения марковская цепь – это вероятностный автомат, распределение вероятностей переходов между вершинами этого направленного графа можно представить в виде матрицы.
Таким образом, цепи Маркова отлично подходят для моделирования случайных событий, а потому активно используются во многих доменах. Сегодня на практике чаще всего распространено применение марковских цепей в компьютерной лингвистике, обработке естественного языка (NLP, Natural Language Processing), финансовом моделировании и других процессах, где необходимо проанализировать серию последовательных событий во времени. Не связанные напрямую события в марковских цепях с точки зрения вероятности независимы друг от друга. Иначе говоря, цепи Маркова представляют собой стохастические модели данных, где они поддерживаются шаблоном случайного распределения вероятностей. Модель может быть проанализирована статистически, но не может быть точно предсказана.
Цепь Маркова отлично подходит для изучения вероятностного моделирования и Data Science. Например, для типовой NLP-задачи генерации текста можно разработать алгоритм на основе марковских сетей, который проанализирует связи между словами, чтобы потом на основе этих знаний сгенерировать новый текст. Для этого отлично подойдет уже готовая Python-библиотека под названием markovify, работу которой мы рассмотрим далее.
NLP и графы с Python-библиотекой Markovify
Python-библиотека markovify представляет собой простой расширяемый генератор цепей Маркова, предназначенный для построения марковских моделей больших корпусов текстов и создание из них случайных предложений. Однако этот инструмент также можно применять и для других целей. Основными достоинствами библиотеки markovify являются следующие:
- Простота эксплуатации – ключевые методы легко переопределить;
- Переносимость — модели можно сохранить в формате JSON, чтобы кэшировать результаты и повторно использовать их;
- Расширяемость — методы синтаксического анализа текста и генерации предложений расширяемы, поэтому Data Scientist может устанавливать свои собственные правила;
- Основана на Python, который считается основным языком программирования в Data Science.
Протестируем работу библиотеки в интерактивном блокноте Google Colab на следующем небольшом тексте из статьи нашего блога сайта курсов по бизнес-анализу https://babok-school.ru/:
Интеграцию информационных систем по API можно рассматривать как взаимодействие типа «запрос-ответ» к одной или нескольким конечным точкам (endpoint), которые реализуют возможности доступа к данным и манипулирование ими по заранее определенному шаблону запроса и ответа. Конечная точка – это адрес ресурса, который является пунктом доступа к системе извне. Endpoint представляет собой путь доступа к ресурсу и является его URL-адресом. В зависимости от стиля шлюза межсистемной интеграции, т.е. программного интерфейса приложения (API, Application Programming Interface) система предоставляет одну или несколько конечных точек, чтобы другие приложения могли получить доступ к ее данным или функциональным возможностям. В частности, популярный клиент-серверный стиль архитектуры REST (Representational State Transfer), предложенный Роем Филдингом, одним из авторов HTTP-протокола, в его докторской диссертации в 2000 году, предполагает множество конечных точек, каждая из которых предоставляет доступ к отдельному ресурсу. Клиенты отправляют HTTP-запросы серверу, обращаясь к конечным точкам, которые предоставляют ресурсы. REST может возвращать данные в любом формате (HTML, XML, JSON), но чаще всего это человеко-читаемый текстовый формат JSON (JavaScript Object Notation) на основе JavaScript. REST API является stateless, т.е. сервер не сохраняет состояние клиента, но клиент может кэшировать данные, полученные с сервера, чтобы сократить нагрузку на сеть и повысить производительность. Благодаря отсутствию состояния нет необходимость держать длительное соединение клиента с сервером, что снижает нагрузку на сеть и на сервер. Клиенты сообщают серверу состояние приложения через заголовок, тело и параметры в каждом HTTP-запросе к ресурсу по URL-адресу. Это соответствует REST-ограничению HATEOAS (Hypermedia as the Engine of Application State). Поскольку сервер не связан с интерфейсом пользователя или состоянием, серверная часть системы (backend) хорошо масштабируется, и может разрабатываться независимо от клиентской (frontend). Впрочем, клиенты могут обращаться к серверу не напрямую, а через посредника, который обеспечивает балансировку нагрузки или отвечает за безопасность. Хотя REST основан на ресурсах, они отделены от представлений, возвращаемых клиенту: в ответ на запрос сервер возвращает клиенту не базу данных, а HTML/XML или JSON-сообщения, представляющий отдельные записи в ней и результаты манипуляций над ними. Все сообщения являются самодокументируемыми, т.е. они содержат достаточно данных, чтобы его выполнить. Операции над ресурсами реализуются через представления, т.е. обладая правами на выполнение конкретных CRUD-операций над объектами базы данных, пользователь может манипулировать ресурсами на сервере.
Чтобы использовать библиотеку, ее нужно сперва установить через менеджер пакетов pip:
pip install markovify
Далее надо импортировать библиотеку, чтобы воспользоваться методами ее классов:
import markovify
Получить из файла rest_api.txt, который лежит в папке /content/ необработанный текст в виде строки поможет следующий код:
with open("/content/rest_api.txt") as f:
text = f.read()
Чтобы построить модель, используем метод NewlineText():
text_model = markovify.NewlineText(text)
Изначально markovify лучше всего работает с большими текстами с пунктуацией. Если текст не использует .s для разграничения предложений, рекомендуется поместить каждое предложение на новую строку и использовать класс markovify.NewlineText вместо класса markovify.Text.
Чтобы составить предложения из прочитанной модели, в markovify есть метод make_sentence(). По умолчанию он делает не более 10 попыток за один вызов, чтобы получить фразы, которые не слишком сильно перекрывается с исходным текстом, т.е. не просто повторяют фрагменты исходного текста. В случае успеха метод возвращает предложение в виде строки, иначе – None. Правило состоит в том, чтобы подавлять любые сгенерированные предложения, которые точно перекрывают исходный текст на 15 слов или 70% от количества слов в предложении. Чтобы увеличить количество попыток, следует задать нужное значение tries в параметрах функции make_sentence(), например, make_sentence(tries=100). Также можно изменить это правило, задав у метода make_sentence() параметры max_overlap_ratio и/или max_overlap_total. Кроме того, эту проверку можно отключить полностью, передав значение False в параметр test_output.
Например, выведем 3 случайно сгенерированных предложения из этой текстовой модели:
for i in range(3): print(text_model.make_sentence(tries=100, test_output=False));
В результате вывода из 3-х предложений 2 повторяют друг друга. Это получилось из-за того, что исходный текст был слишком малого объема.

В заключение еще раз отметим, что цепи Маркова используются не только для анализа текстов и других NLP-задач, но и для исследования пользовательского поведения. В частности, дата-аналитики онлайн-школы Skyeng строили карту пользовательского поведения (CJM, Customer Jorney Map), используя цепи Маркова. Цепь Маркова обучалась на логах активности студентов, а граф полученной матрицы строился с помощью библиотеки NetworkX, о которой мы писали здесь. Исходные данные были представлены в виде CSV-файла, содержащего данные об идентификаторе студента, наименовании события и его времени. Этого было достаточно, чтобы проследить движения клиента, построить CJM-карту и получить цепь Маркова, показывающую вероятность продвижения клиента от исходной точки в конечную. Это продуктовое исследование позволило сделать выводы о реальном пользовательском пути в приложении и улучшить его. Подобный пример оценки эффективности маркетинговых канал с помощью цепи Маркова рассмотрен в нашей новой статье. Другой пример решения NLP-задачи средствами Python в Google Colab смотрите в другом нашем материале.
Как использовать методы и средства анализа графов для решения NLP-задач и других приложений аналитики больших данных в реальных проектах, вы узнаете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
[elementor-template id=»13619″]
Источники

