 1256
1256 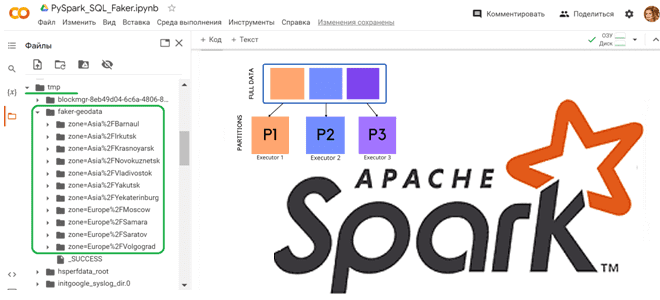
Как сгенерировать набор тестовых данных с Python-библиотекой Faker и разделить данные по разделам, используя функцию partitionBy() в PySpark. Работаем с Apache Spark в Google Colab.
Как работает partitionBy() в Apache Spark
Чтобы записать на диск один большой датафрейм, разделив его на несколько более мелких файлов, в Python API фреймворка Apache Spark используется функция partitionBy(). Это функция класса pyspark.sql.DataFrameWriter, которая разделяет большой датафрейм на основе одного или нескольких столбцов. Такое разделение данных в файловой системе позволяет повысить производительность запроса при работе с большим датафреймом в озере данных. Однако, при создании разделов не следует создавать их слишком много, т.к. это приводит к большому количеству каталогов в HDFS, повышая накладные расходы на NameNode в Hadoop из-за хранения всех метаданных в памяти. Как выбрать оптимальный ключ разделения, мы рассмотрим далее на практическом примере, а пока напомним, как работает функция partitionBy() в PySpark.
При создании датафрейма PySpark создает его с определенным количеством разделов в памяти. Это одно из основных преимуществ датафрейма PySpark по сравнению с датафреймом Pandas. Преобразования партиционированных данных выполняются быстрее, поскольку преобразования выполняются параллельно для каждого раздела. PySpark поддерживает разделение двумя способами: в памяти и на диске файловой системы.
Для разделения в памяти используется функция repartition() или coalesce(), разницу между которыми мы разбирали здесь. А для записи датафрейма PySpark на диск можно выбрать способ разделения данных на основе столбцов, используя partitionBy() из pyspark.sql.DataFrameWriter. Это похоже на схему разделов Apache Hive.
Использования разделов PySpark в памяти или на диске дает быстрый доступ к данным, позволяет выполнять операции с меньшим набором данных и в больших масштабах.
Чтобы понять, как это работает, рассмотрим небольшой пример. Сгенерируем набор данных с именем клиента и его геолокацией. Для этого воспользуемся Python-библиотекой Faker, которая позволяет получить датасет, не создавая собственный словарь случайных значений. Как обычно, я пишу и запускаю код в Google Colab.
Сперва установим необходимые библиотеки и импортируем модули:
# Установка необходимых библиотек !pip install pyspark !pip install faker # Импорт необходимых модулей из pyspark import pyspark from pyspark.sql import SparkSession # Импорт модуля faker from faker import Faker from faker.providers.address.ru_RU import Provider from pyspark.sql.functions import to_json
Затем напишем код создания датафрейма Apache Spark:
# Создаем сессию Spark
spark = SparkSession.builder.getOrCreate()
# Импортируем библиотеку для генерации фейковых данных
# Создание объекта Faker с использованием провайдера адресов для России
fake = Faker('ru_RU')
fake.add_provider(Provider)
# Генерируем данные
i = 20000
names = [fake.name() for _ in range(i)]
coordinates = [fake.local_latlng(country_code='RU') for _ in range(i)]
country=[]
city =[]
latitude =[]
longitude =[]
zone = []
for k in range(i):
latitude.append(coordinates[k][0])
longitude.append(coordinates[k][1])
city.append(coordinates[k][2])
country.append(coordinates[k][3])
zone.append(coordinates[k][4])
# Создаем Spark DataFrame
data = list(zip(names, country, city, latitude, longitude,zone))
sample_schema = ["Name", "country", "city", "latitude", "longitude", "zone"]
dataframe = spark.createDataFrame(data, schema=sample_schema)
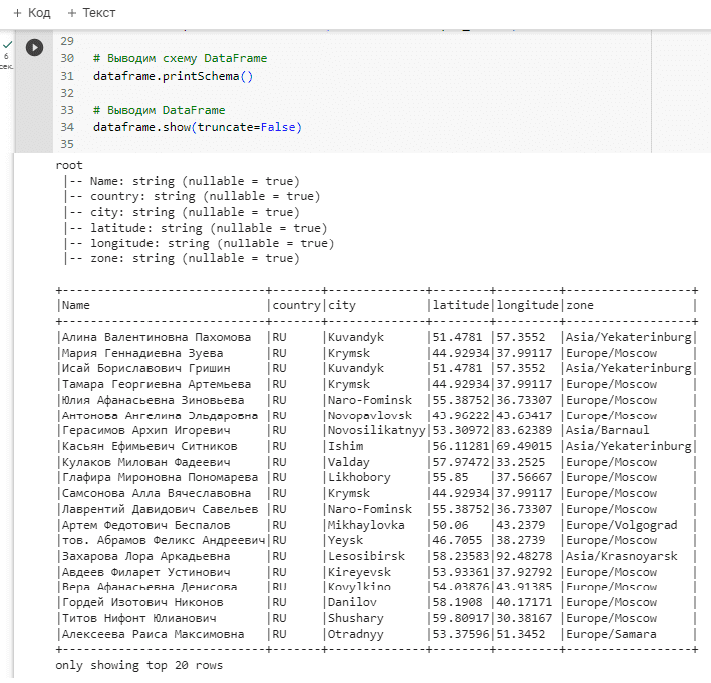
# Выводим схему DataFrame
dataframe.printSchema()
# Выводим DataFrame
dataframe.show(truncate=False)
Если необходимо преобразовать полученный датафрейм в JSON-формат, например, чтобы использовать в качестве тела POST-запроса для обращения к REST API другого веб-сервиса, можно воспользоваться функцией dataframe.toJSON(). Именно для этого был импортирован модуль to_json.
Чтобы понять, по какому ключу лучше всего разделить данные, посчитаем количество пользователей по городам и временным зонам. Для этого сгруппируем строки датафрейма по значениям столбцов city и zone:
# Группируем DataFrame по столбцу "zone"
groupedDF_zone = dataframe.groupBy("zone")
print('groupedDF_zone')
groupedDF_zone.count().show(truncate=False)
# Группируем DataFrame по столбцу "city"
groupedDF_city = dataframe.groupBy("city")
print('groupedDF_city')
groupedDF_city.count().show(truncate=False)
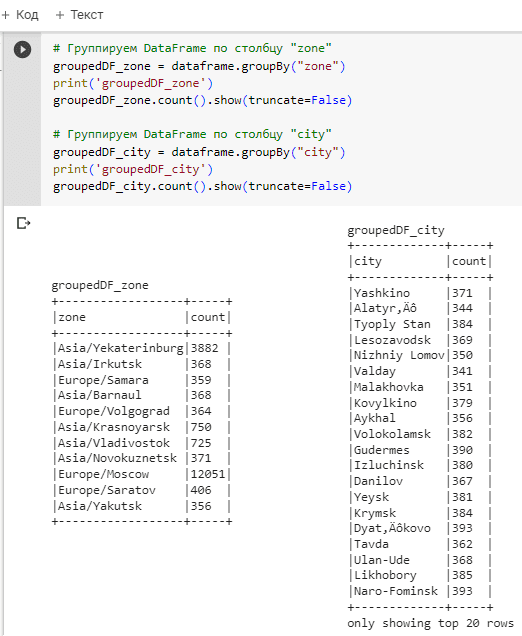
Разумеется, городов намного больше, чем временных зон. Поэтому именно столбец zone целесообразно выбрать в качестве ключа разделения для функции partitionBy(). Зададим этот ключ в качестве параметра partitionBy():
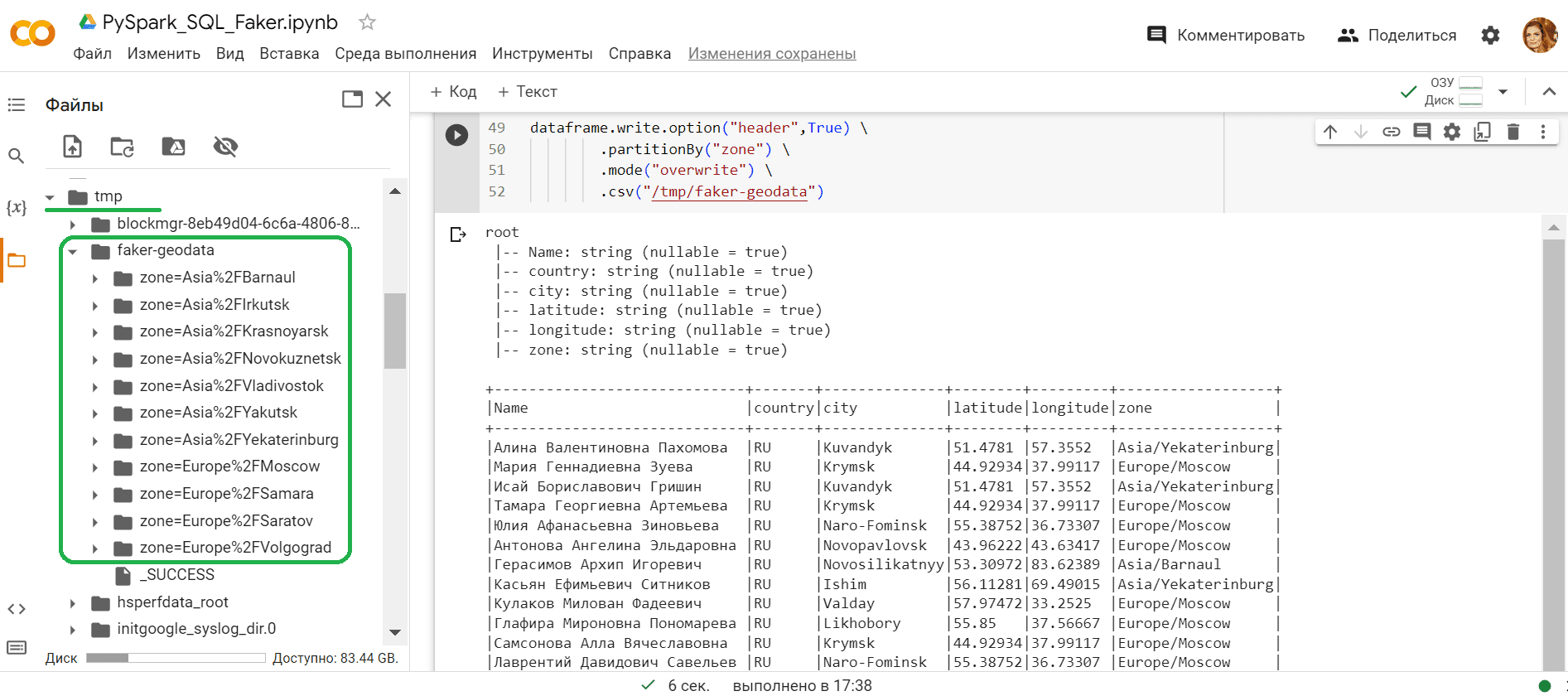
dataframe.write.option("header",True) \
.partitionBy("zone") \
.mode("overwrite") \
.csv("/tmp/faker-geodata")
Результат выполнения можно просмотреть в папке /tmp/faker-geodata: создалось ровно 11 каталогов – по числу уникальных значений в столбце zone, и в каждом созданном каталоге лежит 2 CSV-файла с данными датафрейма.
Освойте все возможности Apache Spark для разработки приложений аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Основы Apache Spark для разработчиков
- Потоковая обработка в Apache Spark
- Анализ данных с Apache Spark
- Машинное обучение в Apache Spark
- Графовые алгоритмы в Apache Spark
[elementor-template id=»13619″]
Источники

