 788
788 
Содержание
Мы уже рассказывали про функции перераспределения данных по разделам coalesce() и repartition(). Сегодня сравним их работу с еще одним методом управления разделами в Apache Spark и разберем, как все они могут помочь дата-инженеру и разработчику распределенных приложений повысить эффективность этого популярного фреймворка аналитики больших данных.
Отобрать и поделить: лучшие практики партиционирования данных в Apache Spark
Одним из главных преимуществ Apache Spark является оперирование данными в памяти, в отличие от классического MapReduce в Hadoop. Но, чтобы в полной мере воспользоваться этим, следует понимать тонкости разбиения данных на разделы в Spark. Это позволит оперировать данными так, чтобы оставаться в памяти, не переходя к дисковому пространству, т.е. избегая shuffle-операций. Напомним, основная идея партиционирования или разделения данных в том, чтобы оптимизировать производительность задания, обеспечив равномерное распределение каждой рабочей нагрузки между каждым исполнителем Spark.
Для этого нужно организовать вычисления так, чтобы ни один исполнитель не остался без работы, и не стал узким местом из-за несбалансированных заданий. В частности, рекомендуется избегать больших файлов, поскольку каждый исполнитель может обрабатывать один раздел за раз. Если разделов меньше, чем исполнителей, оставшиеся исполнители будут простаивать, и ресурсы Spark-кластера не будут утилизироваться эффективно.
Также следует избегать большого количества маленьких файлов, т.к. для доступа к каждому из них, находящемуся в озере данных на AWS S3, Google Cloud Storage, Apache Hadoop HDFS и пр., потребуется активное сетевое взаимодействие, а для вычислений – перетасовка большого количества данных на диске. С другой стороны, производительность заданий также сильно зависит от потребностей в вычислениях, поскольку Spark ориентирован на работу в памяти. Но если вычислительные потребности требуют доступа к другим разделам, вычисления выполняются на диске. Поэтому дата-инженерам и разработчикам распределенных приложений нужно учитывать потребности в вычислениях и разделять данные, чтобы уменьшить перетасовку, т.е. число shuffle-операций. Одной из лучших практик считается сохранять размер файла каждого раздела от 256 МБ до 1 ГБ.
Не стоит разделять данные по столбцам с высокой кардинальностью, т.е. тем, которые содержат много полностью уникальных значений, без повторов. Наоборот, лучше разделить по столбцам, которые в основном используются во время операций фильтрации данных: filter и groupBy. Core Spark - основы для разработчиков
Код курса
CORS
Ближайшая дата курса
Продолжительность
16 ак.часов
Стоимость обучения
48 000
Таким образом, партиционирование является способом разделить данные на несколько разделов, чтобы ускорить вычисления, выполняя преобразования в нескольких разделах параллельно. Можно также записывать разделенные данные в файловую систему, создавая несколько подкаталогов для более быстрого чтения нижестоящими системами.
По умолчанию Spark создает разделы, равные количеству ядер ЦП на компьютере – узле кластера. Данные каждого раздела находятся на одном узле. Spark создает задачу для каждого раздела. А shuffle-операции перемещают данные из одного раздела в другой. Поэтому партиционирование является дорогостоящей операцией, так как создает перетасовку данных, которые могут перемещаться между узлами. По умолчанию операции перемешивания DataFrame создают 200 разделов. Фреймворк поддерживает разбиение на разделы в памяти (RDD/DataFrame) и на диске (файловая система). В кластере это дает быстрый доступ к данным и возможность выполнять операцию с меньшим набором данных. А при работе на локальном узле в автономном режиме, фреймворк разделяет данные на количество ядер ЦП или значение, указанное при создании объекта сеанса SparkSession, о котором мы писали здесь. Какие методы разделения данных по столбцам есть Apache Spark и как они работают, мы рассмотрим далее.
3 метода партиционирования данных: Coalesce vs Repartition vs PartitionBy
Рассмотрим методы разделения данных на примере функций PySpark, Python-интерфейса Apache Spark. К ним относятся следующие:
- repartition(numsPartition, cols) – разделение датафрейма в памяти. Аргумент numsPartition позволяет указать количество файлов разделов, а аргумент cols обеспечивает создание только одного раздела для комбинации значений столбцов.
- coelesce(numPartitions) – разделение датафрейма в памяти, оптимизированное для уменьшения количества разделов без перетасовки данных. Оно не обеспечивает точно равномерного распределения. Поэтому когда необходимо уменьшить номер раздела, следует использовать coalesce. Подробнее о том, как работают coalesce() и repartition(), мы разбирали в этом материале.
- partitionBy(cols) является методом класса pyspark.sql.DataFrameWriter и обеспечивает разделение данных на диске, позволяя определять структуру папок данных без четкого контроля над точным количеством созданных разделов.
Чтобы наглядно показать, как работают эти 3 метода, рассмотрим датасет TLC Trip Record Data за период с 2019 по 2020 год, которые загружаются во датафрейм данных green_df.
Сперва разберем работу метода coalesce(), написав следующий код на PySpark:
df_coalesce = green_df.coalesce(8)
df_coalesce \
.write \
.mode("overwrite") \
.csv("data/partitions/coalesce_8.csv", header=True)
print(df_coalesce.rdd.getNumPartitions())
Этот фрагмент кода создает 8 разделов для датафрейма green_df и сохраняет их в CSV-файл partitions/coalesce_8.csv. Размеры файлов различаются между разделами, поскольку coalesce() не перемешивает данные между разделами в пользу быстрой обработки их в памяти.
А функция repartition() создает равное количество разделов, причем размеры файлов разделов очень близки друг к другу:
df_repartition8 = green_df.repartition(8)
print(df_repartition8.rdd.getNumPartitions())
df_repartition8 \
.write \
.mode("overwrite") \
.csv("data/partitions/repartition_8.csv", header=True)
Рассмотрим функцию repartition() для разделения по значениям столбцов. В нашем примере разделение происходит на основе столбца payment_type, и для каждого уникального типа payment_type будет создан один файл раздела. Такой подход гарантирует, что все данные, связанные с определенным типом платежа, находятся в одном файле раздела.
df_repartition_paymenttype = green_df.repartition("payment_type")
print(df_repartition_paymenttype.rdd.getNumPartitions())
df_repartition_paymenttype \
.write \
.mode("overwrite") \
.csv("data/partitions/repartition_col_v1.csv", header=True)
При применении repartition() по столбцам размер файлов разделов зависит от распределения данных на основе выбранных столбцов.

В отличие от функций coalesce() и repartition(), partitionBy() влияет на структуру папок и не оказывает прямого влияния ни на количество файлов разделов, которые будут созданы, ни на размеры разделов. Она просто гарантирует, что созданная структура папок и данные разделены соответственно на основе указанных комбинаций столбцов. Например, по годам и месяцам. А затем идут фактические файлы разделов.
Применим функцию partitionBy() к рассматриваемому датафрейму:
green_df \
.write \
.partitionBy("pickup_year", "pickup_month") \
.mode("overwrite") \
.csv("data/partitions/partitionBy.csv", header=True)
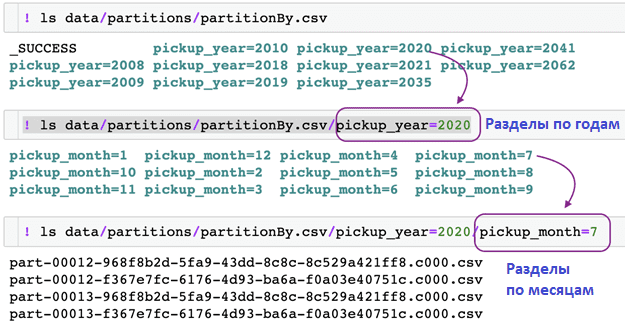
Таким образом, partitionBy() не контролирует количество создаваемых файлов разделов. Если нужно иметь один файл раздела для каждой комбинации столбцов, следует применить repartition() и partitionBy() на одних и тех же столбцах:
green_df \
.repartition("pickup_year") \
.write \
.partitionBy("pickup_year") \
.mode("overwrite")\
.csv("data/partitions/repartion_partionBy_col.csv", header=True)
Функция repartition() обеспечивает создание одного файла раздела для указанных комбинаций столбцов (на год), а partitionBy() обеспечивает структуру папок. Подробный пример, как это работает, мы разбираем здесь.
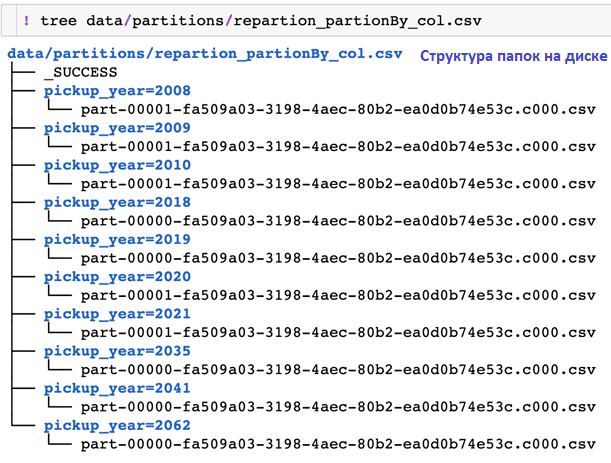
Если указать количество разделов с помощью repartition() и файловую структуру с помощью partitionBy(),перераспределение гарантирует, что каждая папка будет содержать максимум указанное количество разделов:
green_df \
.repartition(2) \
.write \
.partitionBy("pickup_year") \
.mode("overwrite")\
.csv("data/partitions/repartion_partionBy_num.csv", header=True)

Читайте в нашей новой статье про режимы вывода в структурированной потоковой передаче Spark.
Больше практических деталей по использованию Apache Spark для задач дата-инженерии, разработки распределенных приложений и аналитики больших данных вы узнаете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Основы Apache Spark для разработчиков
- Анализ данных с Apache Spark
- Потоковая обработка в Apache Spark
- Машинное обучение в Apache Spark
- Графовые алгоритмы в Apache Spark
[elementor-template id=»13619″]
Источники

