23 марта 2023 года вышел очередной релиз Apache Flink. Разбираемся с главными новинками выпуска 1.17.0: полезные фичи, исправленные ошибки и улучшения для дата-инженера и разработчика распределенных приложений.
Новинки пакетной обработки
В Apache Flink 1.17 внесено множество изменений в области пакетной и потоковой обработки. В частности, добавлен новый пакетный Streaming Warehouse API для удаления и обновления данных на уровне строк во внешних системах хранения, таких как Flink Table Store, с помощью SQL. Синтаксис ALTER TABLE улучшен за счет включения возможности добавлять, изменять и удалять столбцы, первичные ключи и водяные знаки, упрощая пользователям поддержку схемы таблицы.
Также улучшено производительность и стабильность выполнения пакетных рабочих нагрузок за счет оптимизации стратегии и операторов, таких как новое переупорядочение соединений и адаптивная локальная агрегация хэшей, улучшения агрегатных функций Hive и режима гибридного перемешивания. Теперь Speculative Execution поддерживает все операторы, а Adaptive Batch Scheduler более устойчив к перекосу данных.
Спекулятивное выполнение для приемников данных теперь тоже поддерживается, позволяя им знать о количестве попыток выполнения одной и той же задачи, чтобы изолировать данные. Некоторые встроенные приемники позволяют выполнять спекулятивное выполнение, включая DiscardingSink, PrintSinkFunction, PrintSink, FileSink, FileSystemOutputFormat и HiveTableSink. Раньше приемник таблиц Hive поддерживал автоматическое сжатие файлов только в потоковом режиме, но не в пакетном. В Flink 1.17 приемник таблиц Hive может автоматически сжимать вновь записанные файлы в пакетном режиме, чтобы уменьшить количество небольших файлов. Кроме того, для использования встроенных функций Hive через HiveModule Flink представляет несколько встроенных агрегатных функций этого SQL-on-Hadoop инструмента, включая SUM, COUNT, AVG, MIN и MAX. Эти функции могут быть выполнены с использованием оператора агрегации на основе хэша, что повышает производительность.
Кроме того, спекулятивное выполнение задач во Flink 1.17 учитывает не только время их выполнения, но и объем входных данных. Задачи, которые имеют более длительное время выполнения, но потребляют больше данных, не считаются медленными. Это улучшение помогает устранить негативное влияние перекоса данных на обнаружение медленных задач.
Потоковая обработка данных с помощью Apache Flink
Код курса
FLINK
Ближайшая дата курса
21 июля, 2025
Продолжительность
16 ак.часов
Стоимость обучения
48 000
Планировщик пакетных заданий по умолчанию сам настраивает их конфигурации и включает поддержку спекулятивного выполнения, совместимую с гибридным режимом случайного воспроизведения. Гибридный режим случайного воспроизведения теперь поддерживает адаптивный пакетный планировщик и спекулятивное выполнение, а также повторное использование промежуточных данных, что значительно повышает производительность.
Планировщик AdaptiveBatchScheduler теперь используется для пакетных заданий по умолчанию. Этот планировщик может автоматически определять правильный параллелизм каждой вершины задания на основе того, сколько данных обрабатывает вершина. Кроме того, это единственный планировщик, поддерживающий спекулятивное выполнение.
Также улучшено использование AdaptiveBatchScheduler: теперь для глобального параллелизма пользователям не нужно явно устанавливать по умолчанию значение -1. Вместо этого глобальный параллелизм по умолчанию, если он установлен, будет использоваться как верхняя граница при определении параллелизма. AdaptiveBatchScheduler поддерживает равномерное распределение данных между подчиненными задачами на основе детализированной информации о распределении данных. Ограничение, заключающееся в том, что установленный параллелизм вершин может быть только степенью двойки, больше не требуется, и поэтому удалено.
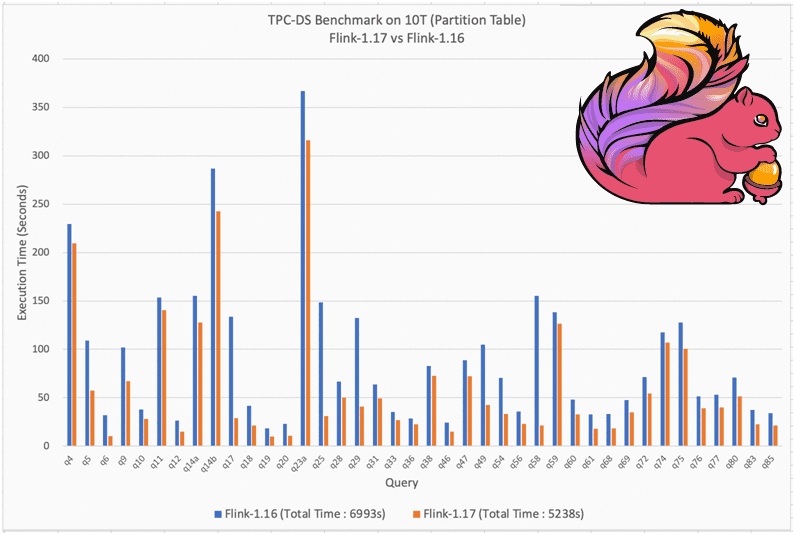
Планировщик может автоматически выбирать подходящий алгоритм соединения-переупорядочивания на основе количества соединений в запросе. Это поведение пока отключено по умолчанию, однако, его включение демонстрирует его эффективность. Бенчмаркинговый тест показал, что производительность Flink версии 1.17 на 26% выше 1.16 для партиционированных таблиц. Чем адаптивный пакетный планировщик отличается от потокового, читайте в нашей новой статье.
Apache Flink 1.17 представляет шлюз для SQL-клиента, позволяющий пользователям отправлять на него SQL-запросы с операторами управления жизненными циклами заданий, включая отображение информации о них и остановку запущенных заданий. Режим шлюза для клиента SQL, позволяет подключаться к удаленному шлюзу и отправлять SQL-запросы, как во встроенном режиме. SQL Gateway поддерживает управление жизненными циклами заданий с помощью SQL-операторов. Пользователи могут использовать SQL-операторы для отображения всей информации о задании, хранящейся в JobManager, и остановить выполнение заданий, используя их уникальные идентификаторы. Благодаря этой новой функции SQL Client/Gateway имеет почти те же функции, что и CLI-интерфейс Flink.
Изменения потоковой обработки в Apache Flink 1.17
В потоковой обработке улучшена семантика потокового Flink SQL. Ранее недетерминированные операции могли привести к неверным результатам или исключениям. Исправлены неправильные планы оптимизации и функциональные проблемы, а также введена экспериментальная функция PLAN_ADVICE для информирования пользователей SQL-запросов об их потенциальных рисках и предложениях по оптимизации. Например, если с помощью команды EXPLAIN PLAN_ADVICE обнаружена проблема NDU (недетерминированные обновления), оптимизатор добавит совет в конец физического плана, затем пометит его идентификатор на реляционном узле связанных операций и порекомендует пользователям обновить конфигурации, чтобы повысить точность и надежность результатов SQL-запросов. Например, когда обнаружена операция GroupAggregate, которую можно оптимизировать для более эффективного локально-глобального агрегирования.
Еще добавлены улучшения контрольных точек, которые повышают скорость и стабильность процедуры их создания, сокращая количество небольших файлов, которые приводят к высокой нагрузке на Namenode в HDFS. Пользователи Flink 1.17 могут вручную активировать контрольные точки с самоопределяемыми типами во время выполнения задания с новым REST API. Теперь для задания, работающего с добавочной контрольной точкой, пользователи могут периодически или вручную активировать полную контрольную точку, чтобы разорвать цепочку добавочных контрольных точек и избежать обращения к файлам большой давности.
Улучшено выравнивание водяных знаков за счет передачи данных между разбиениями в операторе источника. Это устраняет проблемы перекоса данных в приложениях времени события, вызванного несбалансированными источниками и приводит к более эффективной координации хода выполнения водяных знаков в исходном коде, что уменьшает чрезмерную буферизацию нижестоящими операторами и повышает общую эффективность выполнения потоковых заданий.
Потоковая обработка данных с помощью Apache Flink
Код курса
FLINK
Ближайшая дата курса
21 июля, 2025
Продолжительность
16 ак.часов
Стоимость обучения
48 000
С версии 1.17 Apache Flink поддерживает 5 различных файловых систем: HDFS, S3, OSS, ABFS и Local. А внутреннее key-value хранилище FRocksDB обновлено до версии 6.20.3-ververica-2.0, которая содержит улучшения для RocksDBStateBackend, включая поддержку сборки FRocksDB Java на чипсетах Apple Silicon, таких как Mac M1 и M2. Расширена область совместного использования памяти между слотами для TaskManager, что может повысить эффективность использования памяти, если ее потребление неравномерно.
Для повышения производительности и эффективности Flink SQL обновлена инфраструктура управления динамическими SQL-запросами Apache Calcite, о которой мы писали здесь. Ранее Flink использовал Calcite 1.26.0, где были проблемы с упрощением RexNode, вызванные оператором SEARCH, что приводило к неверным данным оптимизации запросов. Это исправлено с обновлением Calcite до версии 1.29.0.
В заключение отметим, что обновления PyFlink включают поддержку Python 3.10 и возможности выполнения на чипсетах Apple Silicon, таких как компьютеры Mac M1 и M2. Также реализован ряд оптимизаций, которые повышают стабильность межпроцессного взаимодействия между процессами Java и Python. Это позволяет указывать типы данных UDF-функций Python с помощью строк и поддерживают доступ к параметрам задания.
Также дата-инженерам и разработчикам распределенных приложений пригодится улучшение Flame Graph – визуализации, которая отвечает о потреблении ресурсов ЦП методами задания. В Flink 1.17 эта визуализация детализирована до уровня задач, позволяя разработчику получить подробное представление об их производительности. Это полезно для повышения эффективности и отладки конвейеров обработки данных. Подробнее о том, что такое Flame-графики, читайте в нашей новой статье. А о новинках релиза 1.18 мы рассказываем здесь.
Узнайте больше про применение Apache Flink для потоковой обработки событий в распределенных приложениях аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники