 1167
1167 
Содержание
В этой статье рассмотрим несколько примеров по аналитике больших данных в Elasticsearch (ES), а также разберем возможности алгоритмов машинного обучения в ELK Stack. Читайте, как использовать NoSQL-СУБД ES в качестве озера данных для проверки различных бизнес-гипотез с помощью Machine Learning, показывая результаты моделирования в интерфейсе Kibana: практическая аналитика Big Data.
Как анализировать Big Data в Elasticsearch: 4 реальных кейса
Прежде всего, перечислим несколько бизнес-задач, для решения которых могут использоваться компоненты ELK-стека [1]:
- анализ поведения пользователей в разных интернет – магазинах – мониторинг и поиск взаимосвязей между различными событиями (клики, покупки, просмотры, лайки, сообщения в чатах и пр.);
- поиск пользователей с похожими потребностями, например, найти всех клиентов в радиусе 3 км, которые продают детские санки, чтобы сообщить об этом тем, кто искал данный товар;
- определять цепочки пользователей со схожими интересами, которые интересуются одними и теми же товарами или товарными категориями. К примеру, тем, кто искал детские санки, показывать еще объявления о колясках или лыжах;
- выявлять тренды по спросу на отдельные категории вещей с учетом временного периода, например, в какой день недели покупают больше всего товаров для дома и пр.
Аналитика больших данных для руководителей
Код курса
BDAM
Ближайшая дата курса
6 июля, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
Elasticsearch как NoSQL-СУБД, заточенная под полнотекстовый поиск, отлично подходит для подобных задач. Наличие геопоиска позволяют решать вопросы, связанный с локациями, а различные фильтры, такие как MLT (More Like This), делают возможным гибко задавать условия отбора. Скорость функционирования зависит от структуры индекса и аппаратных ресурсов. В частности, SSD на порядок быстрее HDD [1].
Однако, предметно-ориентированный язык запросов Query DSL (Domain Specific Language), основанный на JSON, — это еще не все возможности Elasticsearch для аналитики Big Data. Отдельно стоит сказать про функции машинного обучения, доступные в коммерческом пакете X-Pack. Подробнее о схеме лицензирования компонентов ELK Stack мы писали здесь. Что представляет собой Machine Learning в ES, рассмотрим далее.
Как устроен Machine Learning в ELK Stack: возможности и ограничения
Отметим, что стоимость подписки на X-Pack зависит не от объёма данных, а от количества узлов в кластере. При корректной настройке индексов в СУБД и использовании подходящего hardware это позволяет эффективно утилизировать ресурсы и сэкономить бюджет. Модуль Machine Learning в Elasticsearch написан на С++ и работает за пределами JVM, где работает сам ES. Поэтому ML-процесс активно потребляет память, оставшуюся от JVM. С учетом этого рекомендуется выделять отдельные узлы в ES-кластере для машинного обучения [2].
ELK Stack поддерживает алгоритмы обучения без учителя, когда система сама решает поставленные задачи без помощи экспериментатора и предъявления обучающих примеров. Это подходит для случаев, где по известной входной выборке требуется обнаружить внутренние взаимосвязи, зависимости и закономерности между объектами. Сюда относятся задачи кластеризации, обобщения, поиска правил ассоциации, сокращения размерности и визуализации данных, широко распространенные в социологических и маркетинговых исследованиях, включая аналитику потребительского поведения и рыночных корзин [3].
Для анализа алгоритмы Machine Learning используют данные из индексов Elasticsearch. Создавать задания для анализа (Job) можно из графического веб-интерфейса Kibana или через API. Возможен анализ одной метрики (Single Metric) или сразу нескольких (Multi Metric). Однако, каждая метрика анализируется в изолированной среде, без учета поведения параллельно анализируемых метрик. Чтобы включить в расчёты корреляцию различных метрик, используется Population-анализ. Специальная настройка алгоритмов для определённых задач через задание дополнительных опций проводится в разделе Advanced [2].
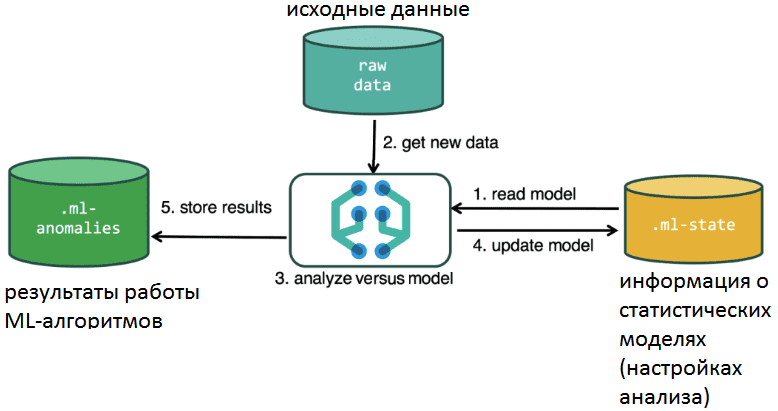
Основными кейсами машинного обучения в Elasticsearch являются следующие [2]:
- поиск аномалий, в т.ч. в режиме онлайн с отправкой уведомлений;
- прогнозирование (максимум на 8 недель вперед).
На практике эти задачи встречаются достаточно часто. Например, выявление попыток взлома или кражи данных при обеспечение информационной безопасности, когда непрерывный анализ логов с рабочих станций компании показывает аномальную активность отдельного пользователя, который вдруг начал слишком часто входить на разные компьютеры. Сюда же относится анализ метрик рабочей производительности, когда на один конкретный узел чрезвычайно возросло количество пользователей или температура в серверной растет слишком быстро [2].
Для подключения собственных ML-алгоритмов к Elasticsearch можно использовать специальный плагин Learning to Rank (LTR), который позволяет ранжировать релевантность поиска. Это особенно полезно для задач регрессии или классификации. Например, предсказать значение переменной, такой как цена акций, в зависимости от известной информации: количество сотрудников, доход компании и пр. LTR поможет не только вывести приблизительную цену акций по известным данным, но и классифицировать компанию, отнеся ее к определенной категории (стартап, новичок фондового рынка, зрелое предприятие и пр.). Важно, что это ранжирование не делает прямого предсказания, но позволяет максимально приблизиться к пользовательскому пониманию документов, от которых зависит результат [4].
Вывод результатов ML-моделирования осуществляется в веб-интерфейсе Kibana, включая наглядные графики и численные показатели.
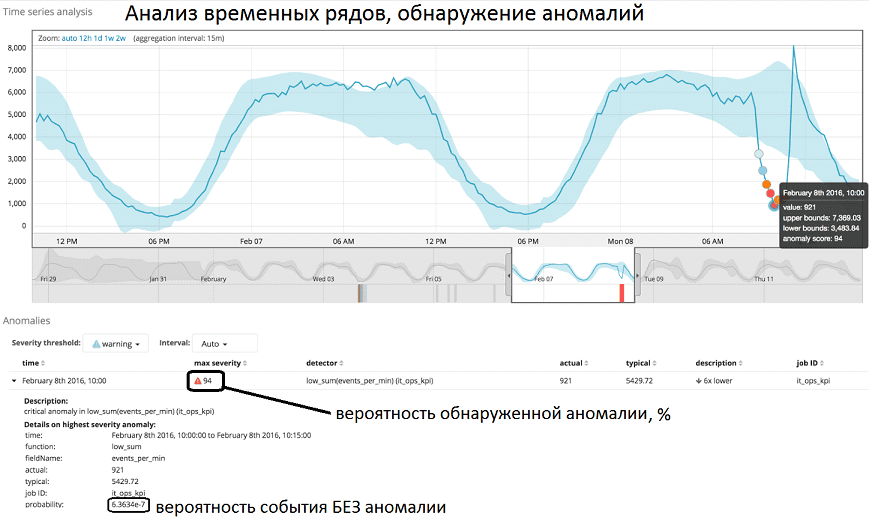
Таким образом, возможности аналитики больших данных в ELK Stack, включая как фильтры с помощью DSL-запросов, так и алгоритмы Machine Learning, позволяют использовать Elasticsearch в качестве озера данных (Data Lake) для проверки различных бизнес-гипотез. А наглядный веб-интерфейс Kibana позволяет эффективно работать с неструктурированными данными не только Data Scientist’ам, но и аналитикам Big Data. О том, как эти функциональные возможности Elasticseacrh и Kibana адаптированы к корпоративным потребностям в новом продукте российского бренда Arenadata, читайте здесь.
Далее мы рассмотрим, как построить комплексную аналитическую Big Data платформу на базе ELK Stack, подключив его к экосистеме Hadoop (Hive, HDFS, Spark, Storm) и Apache Kafka. Читайте в следующей статье про интеграцию Elasticseacrh с Кафка с помощью Apache Kafka Connect. Больше подробностей про аналитику больших данных, Data Lake и обеспечение информационной безопасности Elasticsearch и Apache Hadoop, вы узнаете на практических курсах по администрированию и эксплуатации Big Data систем в нашем лицензированном учебном центре повышения квалификации и обучения руководителей и ИТ-специалистов (разработчиков, архитекторов, инженеров и аналитиков) в Москве:
Источники

