 1141
1141 
Содержание
В этой статье поговорим про интеграцию ELK-стека с экосистемой Apache Hadoop: зачем это нужно и с помощью каких средств можно организовать обмен данными между HDFS и Elasticsearch, а также при чем здесь Apache Spark, Hive и Storm. Еще рассмотрим несколько практических примеров, где реализована такая интеграция Big Data систем для построения комплексной аналитической платформы.
Зачем нужна интеграция Elasticsearch с Apache Hadoop
Как обычно, начнем с описания бизнес-потребности, для чего вообще требуется обмен данными между компонентами Apache Hadoop и ELK Stack. Напомним, Hadoop отлично подходит для пакетной обработки Big Data, но не подходит для интерактивных вычислений из-за особенностей классического MapReduce, связанного с записью промежуточных вариантов на жесткий диск. Elasticsearch, напротив, работает в режиме near real-time, оперативно показывая результаты аналитической обработки неструктурированных данных в веб-интерфейсе Kibana.
Таким образом, интеграция Elasticsearch с Hadoop позволит быстро индексировать Хадуп-данные в ELK Stack, чтобы создавать динамические поисковые приложения. Также такая Big Data система делает возможной глубокую интерактивную аналитику JSON-данных с помощью полнотекстовых геопространственных запросов, разнообразных фильтров и сложных агрегатов. На практике интеграция Elasticsearch c Hadoop применяется достаточно широко: от рекомендательных систем до геномного секвенирования [1].
Интерактивная аналитика больших данных с помощью Teradata QueryGrid и не только
Рассмотрим кейс банка ВТБ, где нужно было обрабатывать любой запрос в режиме «единого окна», отображая информацию из разных источников в понятном виде и не перегружая системы хранения данных сложными алгоритмами. В качестве хранилища файлов общего назначения был выбран Apache Hadoop, который нужно было интегрировать с уже имеющимся корпоративным хранилищем данных (КХД). КХД розничного бизнеса ВТБ построено на платформе Teradata, которая отвечает за централизованную консолидацию данных и обеспечивает все остальные системы единой аналитикой.
Для интеграции Teradata с Hadoop была выбрана технология Teradata QueryGrid, которая позволяет бесшовно объединять инструменты аналитики с помощью так называемой фабрики данных. Благодаря этому различные аналитические инструменты могут выступать как в роли удаленного источника данных, так и в качестве инициатора запросов к любой системе или ко всем компонентам фабрики сразу. За централизованное администрирование и мониторинг Teradata QueryGrid отвечает специализированный модуль – QueryGrid Manager (QGM), обеспечивая установку и обновление всех компонентов фабрики, мониторинг и уведомление о возникающих проблемах. QGM позволяет управлять ключами защищенного доступа по сетям фабрики, контролирует метрики производительности запросов на серверной и клиентской стороне, а также всех логов, которые генерируются компонентами фабрики. Примечательно, что в основе QGM лежит NoSQL-СУБД Cassandra, а для анализа логов используется Elasticsearch (ES) и Kibana.
В качестве движка для обработки аналитических запросов к данным, хранящимся в Apache Hadoop, банк ВТБ выбрал массивно-параллельный механизм Presto, который отлично интегрируется с HDFS и СУБД Teradata за счет коннекторов. В результате была создана комплексная Big Data система, позволяющая аналитикам оперативно получать максимально подробные ответы на различные, в т.ч. очень сложные и глубокие, запросы в режиме «единого окна». Таким образом, этот в этом кейсе опосредовано организована интеграция Elasticsearch с Apache Hadoop [2].
Впрочем, данный пример не такой уж и новаторский: коннектор Hadoop к Elasticsearch существует еще с 2014 года. Он позволяет ES индексировать данные в Хадуп по мере их создания, оперативно делая их доступными для поиска и анализа. Далее с помощью Kibana можно визуализировать огромные объемы данных, создавая наглядные таблицы, диаграммы, гистограммы и прочие графики [3].
Сама компания Elastic, разработчик компонентов ELK Stack, позиционирует коннектор Elasticsearch для Apache Hadoop как автономную open-source библиотеку, которая позволяет заданиям Hadoop (MapReduce, Hive, Pig, Spark и Storm) взаимодействовать с ES. Этот коннектор дает возможность передавать данные в двух направлениях, так что использование Elasticsearch похоже на работу с ресурсами в кластере Hadoop с помощью API-интерфейсов [4].
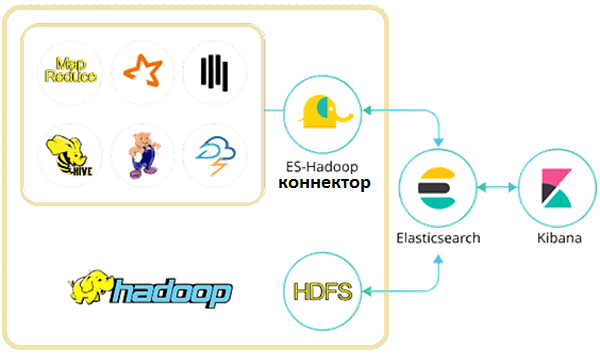
3 особенности коннектора ES-Хадуп: что нужно знать для успешной интеграции Big Data
Отметим несколько важных моментов, которые следует учитывать при практическом использовании коннектора Elasticsearch к Apache Hadoop [5]:
- при маппировании типа данных «дата» Elasticsearch к типу временной метки (timestamp) в Hive, коннектор может идентифицировать только строки символов даты в формат timestamp или стандартный формат XSD — язык описания структуры XML-документа или схема XML;
- если Elasticsearch и компоненты Apache Hadoop (MapReduce, Spark или Storm) находятся в разных кластерах, нужно создать отдельного пользователя Хадуп и ES соответственно;
- Apache Spark может взаимодействовать с Elasticsearch разными способами, включая RDD, Spark SQL и Spark Streaming, а также языков программирования Java и Scala. Подробнее о структурах данных Apache Spark (RDD, Dataset и Dataframe) мы рассказывали здесь.
Как на практике интегрировать Elasticsearch и другие Big Data системы с Apache Hadoop в рамках проектов цифровизации своего бизнеса, вы узнаете на практических курсах по Хадуп в нашем лицензированном учебном центре повышения квалификации и обучения руководителей и ИТ-специалистов (разработчиков, архитекторов, инженеров и аналитиков больших данных) в Москве:
- Основы Hadoop
- Администрирование кластера Hadoop
- Hadoop для инженеров данных
- Безопасность озера данных Hadoop
Источники
- https://www.elastic.co/what-is/elasticsearch-hadoop
- https://habr.com/ru/article/348534/
- https://www.cmswire.com/cms/big-data/big-data-bits-were-hookingup-but-thats-not-all-025631.php
- https://www.elastic.co/guide/en/elasticsearch/hadoop/current/reference/
- https://support.huawei.com/enterprise/en/doc/EDOC1100074552/25959d17/connecting-elasticsearch-to-hadoop

