Matplotlib - это фундаментальная библиотека для визуализации данных в языке программирования Python. Это мощный инструмент, позволяющий создавать статические, анимированные и интерактивные графики высокого качества. В мире Data Science она считается стандартом де-факто, на базе которого построены многие современные высокоуровневые инструменты. Если Pandas отвечает за обработку данных, а Scikit-learn...
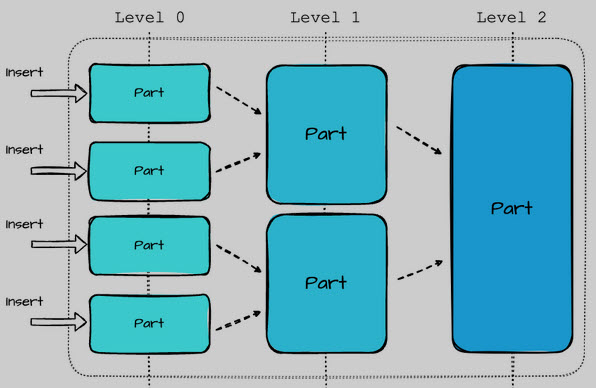
MergeTree – это семейство движков таблиц в ClickHouse, разработанное для хранения данных, отсортированных по первичному ключу. Эти движки обеспечивают высокую производительность для широкого спектра аналитических запросов, поддерживая быструю вставку данных и их последующую фоновую обработку (слияние кусков данных). Семейство MergeTree engine является основой для большинства высоконагруженных задач в ClickHouse. Основные...

Mirror Maker - это инструмент Apache Kafka, предназначенный для реализации зеркального копирования данных внутри брокера. Зеркальное копирование в Kafka подразумевает доступ к записям из разделов основного кластера с целью формирования локальной копии на дополнительном (целевом) кластере. Mirror Maker представляет собой набор потребителей, объединенных в одну группу, которые считывают данные из...

Mixture of Experts (MoE) — это архитектура нейросети, где несколько специализированных моделей-экспертов работают параллельно, но для каждого запроса активируется только часть из них. Это позволяет создавать огромные модели с относительно небольшими вычислительными затратами. Эта архитектура является одним из ключевых "чит-кодов" современного искусственного интеллекта. Она решает фундаментальный парадокс:...

MLOps (Machine Learning Operations) - это набор практик, методологий и философия, направленные на надежное, эффективное и масштабируемое развертывание и поддержку моделей машинного обучения (ML) в производственной среде. По своей сути, MLOps представляет собой применение принципов DevOps (таких как непрерывная интеграция, непрерывная доставка и автоматизация) к специфическим требованиям жизненного...

Model Context Protocol (MCP) — это открытый стандарт, предназначенный для унификации взаимодействия между AI-системами и внешними источниками данных или инструментами. Простыми словами, MCP действует как универсальный адаптер. Он позволяет большим языковым моделям (LLM) и AI-агентам подключаться к разнообразным сервисам единообразно. Это устраняет необходимость в создании уникальных интеграций для каждой...

Model Drift (Дрейф Модели) - это неизбежный процесс снижения производительности и точности модели машинного обучения с течением времени. Это происходит, когда статистические свойства данных, на которых модель работает в реальном мире, начинают отличаться от данных, на которых она изначально обучалась. Проще говоря, Model Drift - это "старение" модели. Мир...
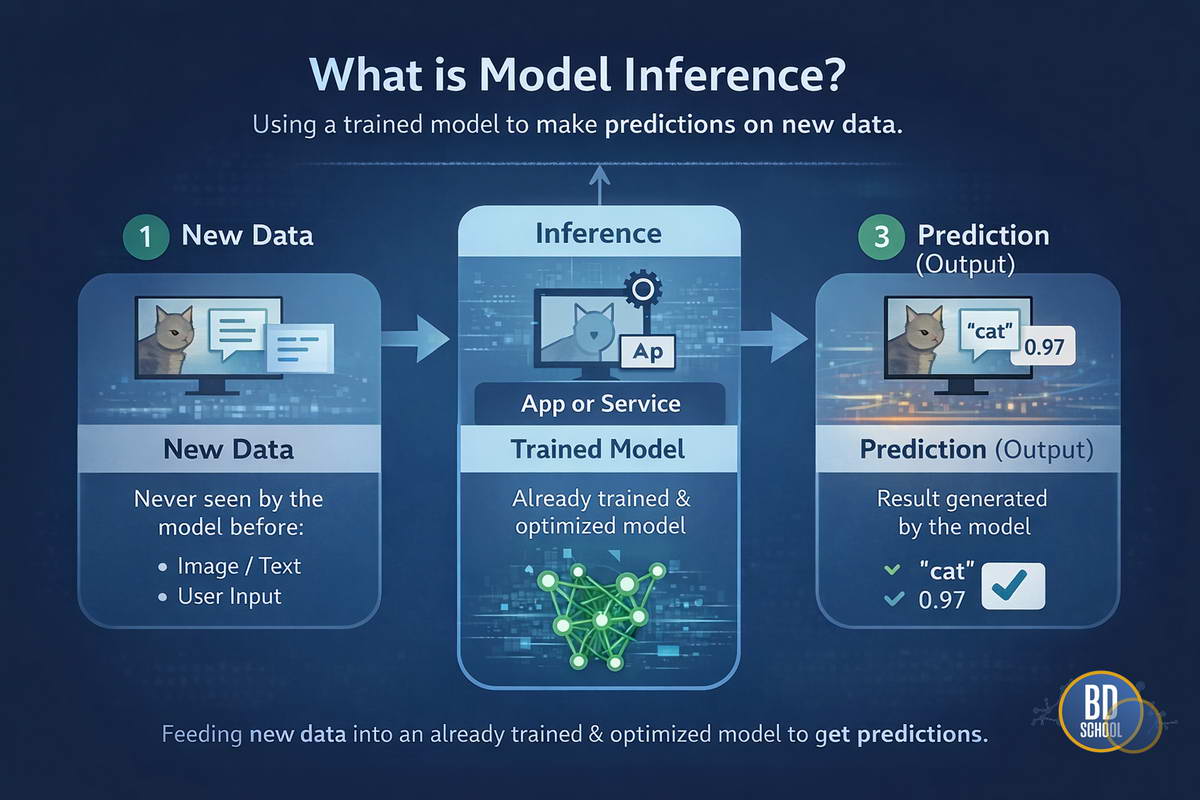
Model Inference (Инференс моделей или вывод моделей) - это процесс использования обученной нейронной сети или алгоритма машинного обучения для получения предсказаний на основе новых, ранее не известных данных. Это финальная стадия жизненного цикла ML-модели, когда абстрактная математическая структура начинает приносить реальную пользу бизнесу или пользователю. Без инференса любая, даже...

Model Serving (Сервинг моделей) - это процесс интеграции обученной модели машинного обучения в программную среду для обработки реальных запросов. Это тот самый мост, который соединяет экспериментальный код Data Scientist’а с продакшн-системой бизнеса. Без надежного сервингa даже самая точная нейросеть останется лишь теоретическим экспериментом. Главная сложность заключается в фундаментальном различии...

MongoDB - это документно-ориентированная (хранящая иерархические структуры данных в виде объектов, содержащих пары ключ/значение) система управления базами данных (СУБД), которая использует формат JSON (JavaScript Object Notation) для описания структуры хранящихся в ней объектов (документов).
n8n — это платформа для автоматизации рабочих процессов, построенная на концепции узлов (nodes). Она позволяет соединять различные веб-сервисы и приложения для выполнения задач без написания кода. Инструмент относится к категории low-code платформ. Это означает, что пользователи могут создавать сложные сценарии автоматизации через визуальный интерфейс. Однако при необходимости можно расширять...

Apache NiFi - это простая платформа обработки событий (сообщений), предоставляющая возможности управления потоками данных из разнообразных источников в режиме реального времени с использованием графического интерфейса. Программа Apache NiFi написана на Java и была разработана Агентством Национальной Безопасности (NSA) под кодовым названием «Niagara Files» для диспетчеризации данных, поддерживающих работу с разнообразными небольшими сетевыми...
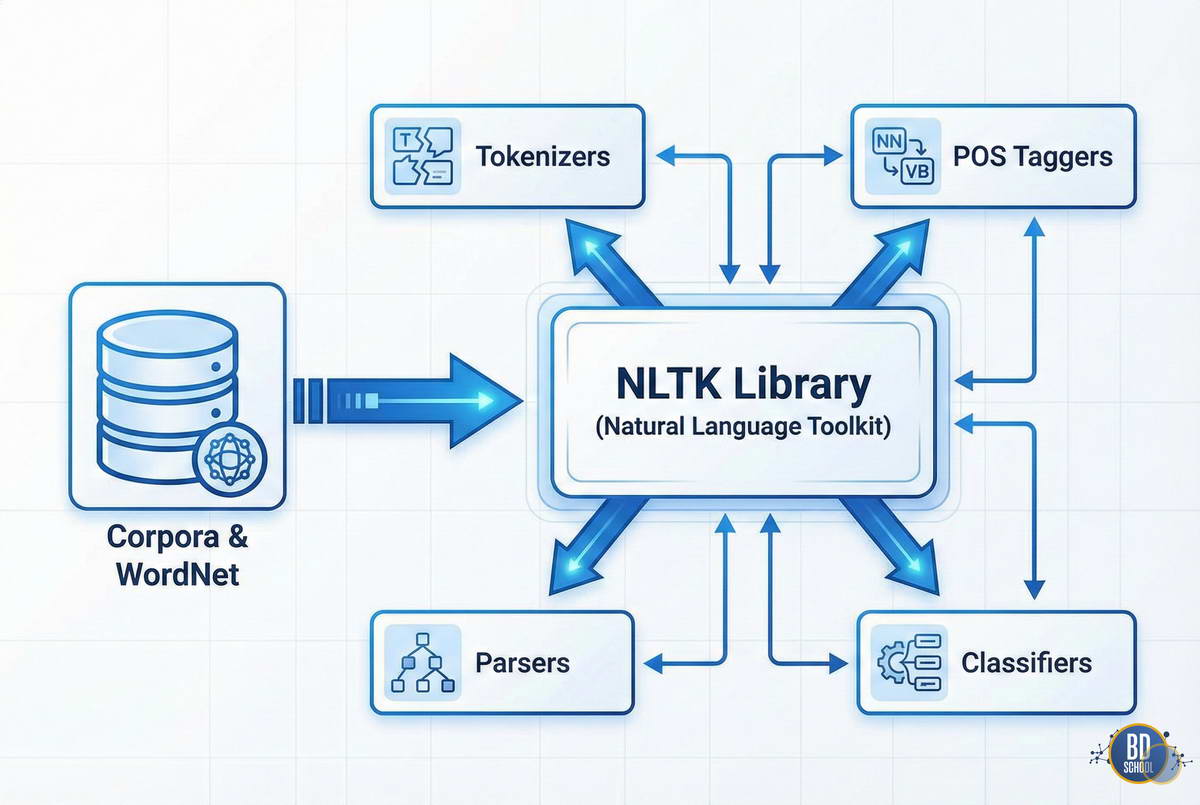
NLTK - это ведущая платформа для создания программ на языке Python для работы с данными на естественном языке. Она предоставляет простые интерфейсы для более чем 50 корпусов и лексических ресурсов. Библиотека включает набор инструментов для обработки текста, таких как токенизация, классификация и тегирование. NLTK часто называют «учебной лабораторией» для...

NoSQL (Нереляционные базы данных) - это базы данных, которые используют для хранения информации модели, отличающиеся от привычных нам плоских таблиц. Термин NoSQL ("Not Only SQL") означает, что эти решения не ограничиваются жесткими рамками реляционной логики. Они предлагают более гибкие способы организации данных. В отличие от классического подхода, где структура данных...

NumPy (Numerical Python) - это фундаментальная библиотека для языка Python, предназначенная для высокопроизводительных численных вычислений, обеспечивающая работу с многомерными массивами, векторизованными операциями и базовыми инструментами линейной алгебры, статистики и научных расчётов. Это база, на которой стоит вся экосистема Data Science. Без понимания NumPy невозможно эффективно работать с Pandas,...
Object detection – технология, связанная с компьютерным зрением (computer vision) и обработкой изображений, заключающаяся в обнаружении объектов определенных классов на цифровых изображениях и видео. Причем, обнаружение объектов заключается в определении границ объекта на цифровом изображении или видео. В качестве примера мы можем использовать открытую программную библиотеку для машинного обучения TensorFlow, разработанную...

ODS (Operational Data Store) — это интеграционный слой хранилища данных, предназначенный для консолидации и оперативного хранения очищенных и согласованных данных из нескольких транзакционных систем с целью поддержки оперативной аналитики и последующей загрузки в аналитические хранилища. Эта база располагается между источниками сырой информации и аналитическим хранилищем. Транзакционные системы (OLTP) отлично...
OpenRouter — это API-агрегатор для больших языковых моделей (LLM), который предоставляет единый интерфейс доступа к множеству нейросетей. Он выступает как унифицированный шлюз к моделям от разных провайдеров, включая OpenAI (GPT-4), Anthropic (Claude 3.5), Google (Gemini), Meta (Llama), Mistral и десятки других. Чтобы понять его ценность, проще всего использовать аналогию....

ORC (Optimized Row Columnar) – это колоночно-ориентированный (столбцовый) формат хранения Big Data в экосистеме Apache Hadoop. Он совместим с большинством сред обработки больших данных в среде Apache Hadoop и похож на другие колоночные форматы файлов: RCFile и Parquet. Формат ORC был разработан в феврале 2013 года корпорацией Hortonworks в сотрудничестве...
OSMNX - это пакет Python, который позволяет загружать пространственные геометрии и моделировать, проектировать, визуализировать и анализировать реальные уличные сети из API-интерфейсов OpenStreetMap.