
Apache Parquet - это бинарный, колоночно-ориентированный формат хранения больших данных, изначально созданный для экосистемы Hadoop, позволяющий использовать преимущества сжатого и эффективного колоночно-ориентированного представления информации. Паркет позволяет задавать схемы сжатия на уровне столбцов и добавлять новые кодировки по мере их появления [1]. Вместе с Apache Avro, Parquet является очень популярным форматом...

Polars - это высокопроизводительная библиотека для обработки и анализа данных, написанная на языке Rust, реализующая колоночную модель вычислений и поддерживающая ленивые (lazy) и eager-вычисления, ориентированная на эффективную работу с большими объёмами данных и предоставляющая интерфейс для Python. В отличие от традиционных инструментов, Polars изначально проектировался для параллельной обработки данных и...
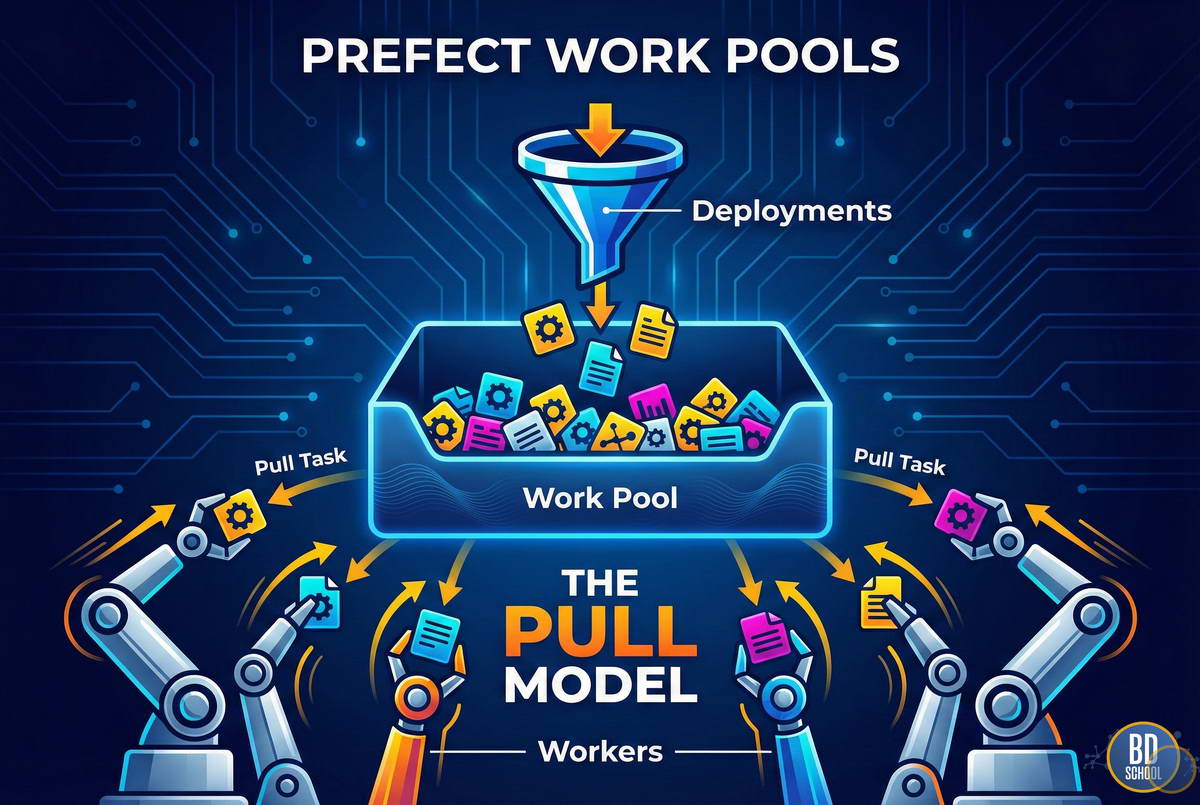
Prefect - это современная система оркестрации потоков данных (workflow orchestration), позволяющая превратить обычный Python-код в надежный, наблюдаемый и устойчивый к сбоям конвейер. Если классические инструменты вроде Apache Airflow требуют изучения сложного DSL (предметно-ориентированного языка), то Prefect исповедует философию "просто пиши на Python". Главная "фишка" Prefect - концепция Negative...

Prompt (промпт) — это текстовая инструкция или запрос, который человек вводит в систему искусственного интеллекта. Это делается, чтобы получить нужный ответ, изображение, код или другое действие. От качества и точности Prompt зависит, насколько полезным и релевантным будет результат. Можно рассматривать Prompt как техническое задание. Оно дается большой языковой модели...

Prompt engineering (инженерия запросов) - это процесс проектирования, формулирования и итеративной оптимизации текстовых инструкций (промптов), направленных к большим языковым моделям (LLM) для получения точных, релевантных и контролируемых ответов. Prompt Engineering (PE) включает в себя глубокое понимание того, как модель интерпретирует контекст, структурирует информацию и следует инструкциям. Как следствие,...
Apache Spark. PySpark может использоваться для распределенных вычислений на Python в рамках анализа и обработки больших данных (Big Data), а также машинного обучения (Machine Learning).

RAFT — это алгоритм распределённого консенсуса, обеспечивающий согласованную репликацию журнала операций между узлами кластера и выбор лидера для координации изменений состояния системы. Он решает фундаментальную проблему надежной синхронизации данных. Представьте группу полностью независимых серверов в сети. Они должны всегда работать как единый слаженный механизм. Если один сервер внезапно сломается,...

Ray — это распределённый фреймворк для параллельных и распределённых вычислений, предназначенный для масштабируемого выполнения задач и управления состоянием в кластере, широко используемый в задачах машинного обучения и обработки данных. Он имеет открытый исходный код. Инструмент создан специально для масштабирования приложений на Python. Код на этом языке часто работает довольно...

RBAC (Role-Based Access Control), или Управление доступом на основе ролей, - это фундаментальный отраслевой стандарт для управления правами доступа в IT-системах. Суть RBAC проста: вместо того чтобы назначать права доступа (например, "чтение таблицы X") напрямую каждому отдельному пользователю ("Ивану", "Петру", "Сервисному-Аккаунту-1"), вы сначала создаете Роль (например, "Аналитик"). Вы даете все...
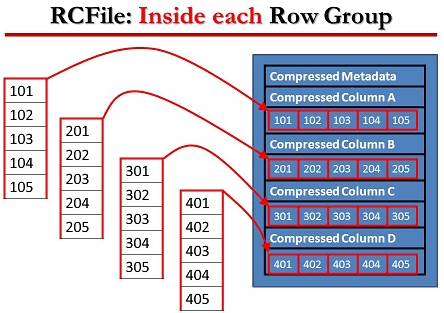
RCFile (Record Columnar File) – гибридный многоколонный формат записей, адаптированный для хранения реляционных таблиц на кластерах и предназначенный для систем Big Data, использующих MapReduce. Этот формат для записи больших данных появился в 2011 году на основании исследований и совместных усилий Facebook, Государственного университета Огайо и Института вычислительной техники Китайской академии...

Redis (Remote Dictionary Server) - это высокопроизводительное in-memory хранилище данных типа key-value, поддерживающее различные структуры данных и используемое для кэширования, очередей, сессий и real-time-сценариев благодаря низкой задержке и горизонтальному масштабированию. В мире больших данных и веб-разработки скорость отклика часто является критическим фактором успеха. Традиционные дисковые базы данных не...

Redis Persistence - это комплекс механизмов, отвечающих за сохранение данных из оперативной памяти на долговечный носитель (жесткий диск или SSD). Redis — это in-memory база данных. Это означает, что по умолчанию все данные живут исключительно в оперативной памяти. Это обеспечивает феноменальную скорость, но создает критический риск: при любом...

Requests - это мощная библиотека для выполнения синхронных HTTP-запросов. Инструмент позволяет программному коду обмениваться данными с удаленными серверами. Библиотека полностью скрывает сложную низкоуровневую реализацию сетевых протоколов. Разработчик получает максимально удобный высокоуровневый интерфейс для работы. Главная философия создателей проекта звучит как HTTP для людей. Это означает интуитивную понятность архитектуры даже для...
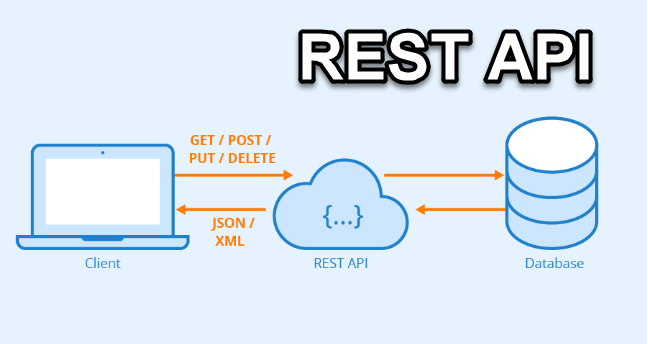
REST API — это интерфейс программирования приложений, который соответствует принципам архитектурного стиля REST (Representational State Transfer). Важно понимать, что REST не является протоколом или стандартом. Это набор архитектурных ограничений и принципов для построения распределенных систем. Когда веб-сервис разработан с соблюдением этих принципов, его называют RESTful. Главная цель REST...

RAG (Retrieval-Augmented Generation) — это архитектурный подход в области искусственного интеллекта, который объединяет мощь больших языковых моделей (LLM) с внешними, авторитетными базами знаний. Проще говоря, это технология, которая учит языковые модели не выдумывать ответы, а находить их в проверенных источниках и на их основе генерировать осмысленный текст. RAG был разработан...

RFID (от английского Radio Frequency IDentification, радиочастотная идентификация) — способ автоматической идентификации объектов, когда радиосигналы считывают или записывают данные, хранящиеся в RFID-метках (транспондерах) [1]. Как появилась технология RFID: немного истории Предшественники современных RFID-меток появились в середине XX века в рамках разработки технологий передачи и распознавания сигналов в военной сфере [1]:...
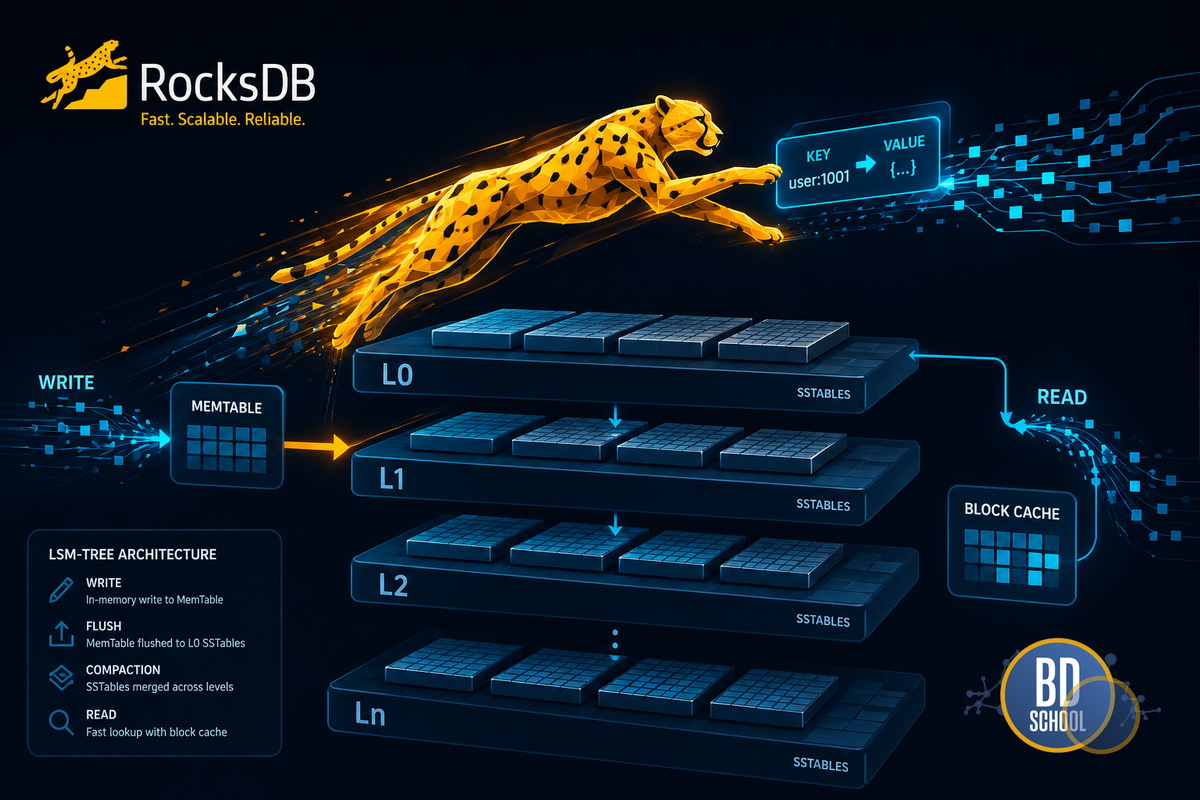
RocksDB (в поисковых запросах часто фигурирует как RockDB) - это встраиваемая высокопроизводительная key-value база данных, основанная на LSM-деревьях, оптимизированная для работы с SSD и предназначенная для хранения и обработки больших объёмов данных с высокой нагрузкой на запись. Данная СУБД была разработана инженерами компании Meta на основе открытого исходного кода проекта...

S3 (Simple Storage Service) - это объектное хранилище данных с доступом по HTTP(S), предназначенное для масштабируемого, отказоустойчивого и долговременного хранения неструктурированных данных с моделью доступа через ключи и бакеты. Изначально технология была разработана компанией Amazon. Сегодня S3 стал глобальным протоколом обмена информацией. Любой современный разработчик сталкивается с ним каждый день....

Apache Samza (Самза) – это асинхронная вычислительная Big Data среда с открытым исходным кодом для распределенных потоковых вычислений практически в реальном времени, разработанная в 2013 году в соцсети LinkedIn на языках Scala и Java. Проектом верхнего уровня Apache Software Foundation Самза стала в 2014 году [1]. Samza vs Apache Kafka...

Scikit-learn (sklearn) - это библиотека для языка Python, предназначенная для машинного обучения, предоставляющая единый интерфейс для алгоритмов классификации, регрессии, кластеризации, снижения размерности и оценки моделей на основе данных. Библиотека, которая превращает сложную математику машинного обучения в понятные Python-команды. Если NumPy и Pandas - это "кирпичи" и "цемент" для...