Зачем Trino статистика таблиц, как MPP-движок создает план выполнения SQL-запросов к разным источникам данных, применяя CBO-оптимизацию, а также полную или частичную передачу обработки предикатов в базовое хранилище. Внутренние оптимизации Trino В отличие от MapReduce с материализацией промежуточных результатов на диске, в массово-параллельной архитектуре Trino промежуточные результаты передаются между рабочими узлами...
Что не так с Apache Zookeeper и почему разработчики ClickHouse решили заменить его на встроенный сервис синхронизации метаданных на базе RAFT-протокола с линеаризацией записи и чтения. Как работает ClickHouse Keeper и где его настроить. Что не так с Apache Zookeeper Многие распределенные системы, которые состоят из нескольких узлов, для обеспечения...
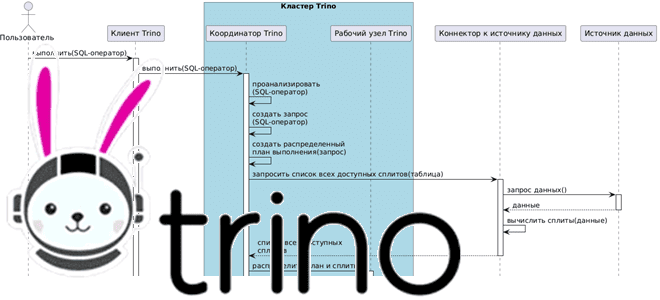
Как взаимодействуют рабочие узлы Trino между собой и с координатором кластера, а также с клиентскими приложениями и драйверами при выполнении SQL-запросов к данным из внешних источников без их фактического копирования. Последовательность выполнения запросов в кластере Trino Продолжая разбираться с Trino, сегодня рассмотрим, как этот аналитический движок с массово-параллельной архитектурой (MPP,...
Как без копирования анализировать данные из разных источников в реальном времени с помощью SQL-запросов: каталоги и коннекторы Trino. Коннекторы Trino: как они работают и что настроить в каталоге Вчера мы разобрали, как устроен кластер Trino – аналитического движка с массово-параллельной архитектурой (MPP, Massively Parallel Processing), который обрабатывает данные на нескольких...
Как с помощью SQL-запросов анализировать огромные объемы данных из множества источников в реальном времени без их фактического копирования. Архитектура и принципы работы MPP-движка Trino. Что такое Trino и зачем он нужен Массово-параллельная архитектура (MPP, Massively Parallel Processing) с разделяемой памятью, когда система состоит из отдельных узлов, которые вместе выполняют одну...
Сегодня я на практическом примере покажу тонкости настройки конфигураций JDBC-коннектора источника, передающий новые записи из таблицы PostgreSQL в топик Apache Kafka. Настройка JDBC-коннектора и отправка в Kafka Connect Как я упоминала вчера, помимо CDC-коннектор Debezium, передать данные из реляционной базы данных PostgreSQL в Apache Kafka, также есть JDBC-коннектор от Confluent:...

Что общего между Kafka Connect JDBC Source и PostgreSQL CDC Source V2 (Debezium), чем отличаются эти коннекторы и как добавить JDBC-драйвер для передачи данных из PostgreSQL в Apache Kafka на Docker. Коннекторы Kafka к реляционным БД от Confluent О том, что CDC-коннектор Debezium позволяет организовать интеграцию Apache Kafka с реляционной...
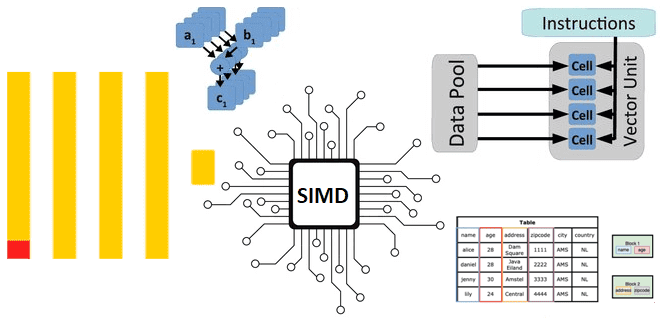
Как ClickHouse реализует параллельные векторные вычисления над большим объемом данных на любых аппаратных платформах: диспетчеризация ЦП для выполнения SIMD-инструкций в сложных функциях. Реализация векторных вычислений в ЦП Как мы уже отмечали здесь, ClickHouse имеет встроенную поддержку векторных вычислений, когда при выполнении одной инструкции процессора производится не одна операция, а одновременно...

Что такое Observability и чем ClickHouse хорош для обеспечения наблюдаемости, как хранить журналы и трассировки в этой колоночной базе данных и для чего реализована интеграция с OpenTelemetry. Что такое Observability и чем ClickHouse хорош для обеспечения наблюдаемости Будучи колоночной базой данных, ClickHouse отлично подходит для мониторинга и анализа системных метрик,...
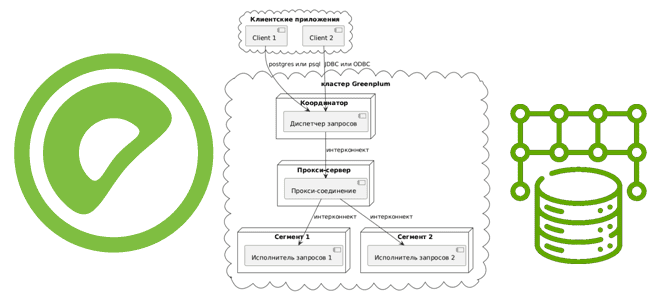
Как сегменты Greenplum взаимодействуют друг с другом для выполнения распределенных SQL-запросов, чем UDPIFC-режим интерконнекта лучше TCP-протокола, зачем проксировать межсетевые соединения и какими командами это сделать. Что такое интерконнекты в Greenplum Greenplum представляет собой массив отдельных баз данных PostgreSQL 12, работающих вместе для представления единого образа базы данных. Точкой входа в...

4 октября 2024 года вышел очередной релиз ClickHouse. Знакомимся с его самыми интересными особенностями: добавление строк в обновляемые материализованные представления, агрегатные функции для типов данных JSON и Dynamic, поддержка заголовков HTTP-ответов, автозамена строк с overlay-командами и другие новинки выпуска 24.9. Обновляемые материализованные представления Начнем с наиболее значимой новой функции ClickHouse...
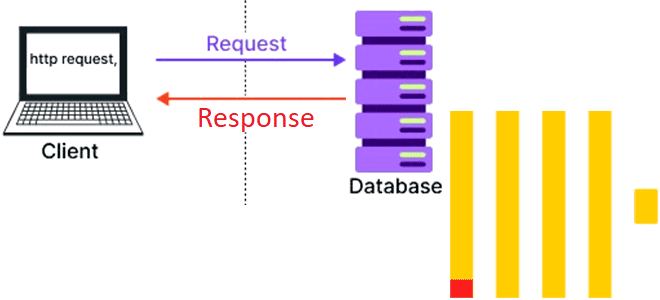
Как реализовать систему с двухзвенной архитектурой на ClickHouse и браузере. Возможности колоночной СУБД для создания одностраничных веб-приложений. Возможности ClickHouse для одностраничных веб-приложений Хотя трехзвенная архитектура (клиент -> бэк-> база данных) уже давно стала стандартом де-факто в разработке веб-приложений, двухзвенная архитектура, когда бизнес-логика переносится в базу данных, до сих пор встречается....
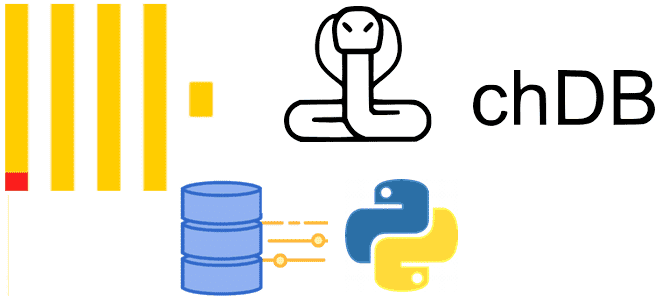
Что такое Chdb, зачем нужна эта библиотека и как ее использовать в коде Python-приложения для анализа больших данных в ClickHouse без разворачивания полноценного сервера этой колоночной СУБД. Как и зачем работать с ClickHouse без сервера СУБД ClickHouse является мощным инструментом аналитики больших данных, который требует соответствующей инфраструктуры. Однако, иногда нужно...
Что такое волатильные функции, зачем они нужны и чем опасны: разбираем на примере Greenplum и PostgreSQL. К чему приведет некорректное использование атрибутов изменчивости в SQL-запросе или UDF-функции распределенной MPP-СУБД. Что такое волатильность функции и почему это важно для Greenplum Волатильной или изменчивой считается функция, значение которой может изменяться даже в...
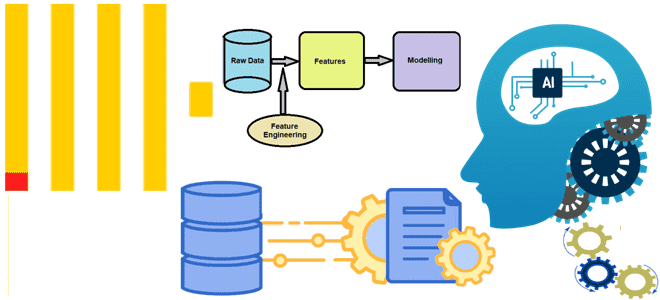
Что такое хранилище признаков, зачем это нужно в машинном обучении, каковы его главные компоненты и как использовать ClickHouse в качестве Feature Store для ML-задач. Хранилище признаков для машинного обучения: архитектура и принципы работы Feature Store Будучи колоночной базой данных, ClickHouse отлично подходит на роль хранилища фичей (Feature Store) для задач...
Аналитика данных из топиков Kafka с помощью SQL-запросов: обращение к ksqlDB в Docker через CLI-интерфейс и REST API в Postman с SSH-тунелированием сервера потоковой базы данных. Практическое руководство с примерами и иллюстрациями. CLI-интерфейс ksqldb Docker-образ Confluent Kafka включает дополнительные компоненты этой платформы: ksqlDB, Kafka Connect, REST Proxy, Schema Registry). Сегодня...
Зачем нужна автоматическая очистка таблиц системного каталога Greenplum, почему команда AUTOVACUUM выполняется локально на каждом сегменте и как ее настроить для максимальной эффективности старых кортежей в распределенной базе данных с массовой-параллельной обработкой. Параметры автоматической очистки в Greenplum О том, зачем нужна команда автоочистки в Greenplum и как она работает, мы...

Как решать задачи машинного обучения в Greenplum с агентом gpMLBot и расширением PostgresML: возможности, ограничения и примеры. Что такое gpMLBot: Greenplum Automated Machine Learning Agent Чтобы использовать Greenplum как хранилище данных в задачах машинного обучения, в этой БД поддерживаются соответствующие механизмы. Одним из них является библиотека Apache MADlib, о которой...
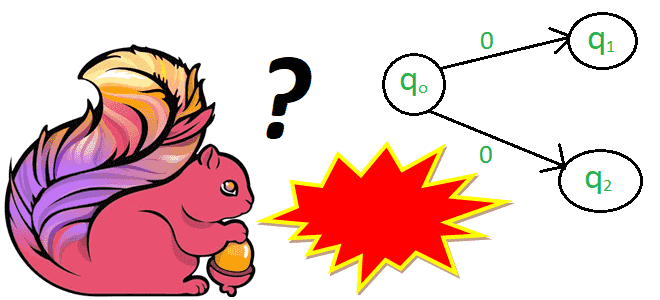
Что такое проблема недетерминированного поведения, почему она так важна в потоковой обработке данных и как Apache Flink борется с ней: недетерминированные и динамические функции, а также changelog stateful-операторов. Недетерминированные функции в Apache Flink В потоковой обработке данных, на которую ориентирован Apache Flink, все завязано на отметку времени события (timestamp). Однако,...

Разработчики ClickHouse с завидной регулярностью радуют новыми релизами. Не прошло и месяца, как опубликован очередной выпуск этой колоночной СУБД, версия 24.8 LTS от 20 августа 2024. О ее главных новинках читайте далее. Несовместимые изменения Начнем с самых важных и несовместимых изменений. В релизе ClickHouse 24.8 LTS для clickhouse-client и clickhouse-local...