 1312
1312 
Содержание
Продолжая тему SQL-on-Hadoop, сегодня мы рассмотрим вопросы обеспечения информационной безопасности в Apache Hive и Cloudera Impala. Читайте в нашем материале, что такое RBAC, в чем специфика cybersecurity больших данных в экосистеме Hadoop и какие средства помогут защитить Big Data при работе с Hive и Impala.
Что такое RBAC для SQL-on-Hadoop и зачем это нужно в Big Data
Исторически платформа Apache Hadoop развивалась из закрытых кластерных систем, которые обрабатывали большие объемы общедоступной информации в закрытых центрах обработки данных. Поэтому защита этой информации и результатов ее обработки не являлась первостепенной задачей. Однако, современный Hadoop используется, в том числе для обработки массивов личной информации, а также в рамках многопользовательских Big Data систем, когда каждый из клиентов может работать только с определенным кругом данных [1].
Сегодня для защиты конфиденциальной информации в экосистеме Apache Hadoop от утечек используется целый ряд различных технологий:
- организация защищенного периметра, например, с помощью Apache Knox;
- Apache Atlas для безопасной интеграции с корпоративными информационными системами;
- комплексные решения для мониторинга и управления cybersecurity типа Apache Ranger;
- защищенные протоколы передачи данных;
- средства шифрования и изоляции;
- гибкие политики доступа к данным на основе атрибутов или ролей.
С точки зрения избирательного доступа к данным, реализуемого с помощью Apache Hive и Cloudera Impala в рамках SQL-запросов к Hadoop (HDFS, HBase), наибольший интересов представляет именно многопользовательский режим работы, когда каждая категория клиентов или даже отдельный пользователь обладают своими уникальными правами на считывание или изменение определенной информацией. Для реализации подобной модели избирательной работы с данными сегодня используется политика управления доступом на основе ролей (RBAC, Role Based Access Control). С 2004 года Американский национальный институт стандартов и Международный комитет по стандартам информационных технологий (ANSI/INCITS) принял RBAC в качестве единого стандарта. Ролевое разграничение привилегий позволяет гибко и динамично управлять правами пользователя, по необходимости меняя правила доступа к данными для отдельной должности, конкретного человека или целой группы лиц [2].
Из наиболее важных функций RBAC для защиты корпоративной Big Data среды стоит отметить следующие [1]:
- защищенная авторизация, которая обеспечивает обязательное управление доступом к данным для аутентифицированных пользователей. Пользователям присваиваются роли, а затем предоставляются соответствующие полномочия по доступу к данным. Это позволяет при помощи шаблонов масштабировать модель, разделяя пользователей на категории в соответствии с их ролями. Так защищенная авторизация избавляет от рутинного выделения детализированных полномочий каждому пользователю и упрощает управление разрешениями, снижая нагрузку на системных администраторов. Кроме того, это сокращает вероятность возникновения ошибочного и непреднамеренного предоставления доступа.
- гибкое администрирование пользовательских полномочий путем распределения задач на уровне схемы или базы данных. Например, одна конкретная роль может разрешать пользователю применение к определенным данным операции выбора (select), а другая – операции записи (insert). В частности, для менее строгих уровней безопасности роли могут быть определены так, чтобы ограничивать видимость определенной информации.
Подчеркнем, что RBAC предназначена для гибкой настройки авторизаций (прав) к отдельным таблицам, столбцам, файлам, папкам и прочим абстракциям данных. За первичную аутентификацию пользователей отвечает защищенный протокол Kerberos, который предотвращает несанкционированный доступ к среде Apache Hadoop. Он основан на взаимной аутентификации клиента и сервера перед установлением связи между ними, с учетом того, что начальный обмен информацией между клиентом и сервером происходит в незащищенной среде, а передаваемые пакеты могут быть перехвачены и модифицированы [3]. На практике Kerberos-аутентификация активно используется с Apache Hive и Cloudera Impala, предоставляя санкционированный доступ к данным, хранящимся в экосистеме Hadoop.
В рамках RBAC-модели проверка полномочий пользователя на доступ к определенным данным в среде Hadoop при выполнении SQL-запроса с помощью Hive или Impala осуществляется после его парсинга и построения дерева, до формирования плана выполнения запроса и его генерации в исполнительный код.
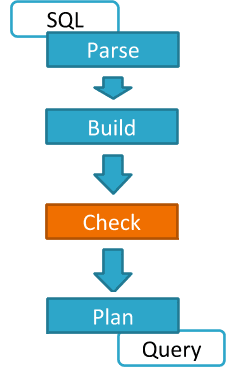
Apache Sentry, Ranger и Cloudera RecordService: что обеспечивает RBAC в Hive и Impala
За реализацию RBAC-модели в Hive и Impala отвечают внешние модули. Сперва защищенную авторизацию на основе ролей в этих SQL-средах для Hadoop обеспечивала система Sentry, с 2016 года ставшая в фонде Apache Software Foundation проектом верхнего уровня. Sentry реализует высокодетализированную авторизацию с возможностью задания средств управления безопасностью для сервера, базы данных, таблицы и представления, включая специфицирование и преобразование селективных полномочий для представлений и таблиц. Каждая база и схема данных могут иметь раздельные политики авторизации. Кроме того, Sentry обеспечивает поддержку для архитектуры метахранилища Hive.
Каждое приложение Hive и Impala защищено индивидуальным набором связываний, которые взаимодействуют с механизмом политик безопасности для оценки и валидации заранее заданной политики. После санкционированного доступа эти наборы связываний абстрагируют политики безопасности для получения доступа к данным в HDFS [1].
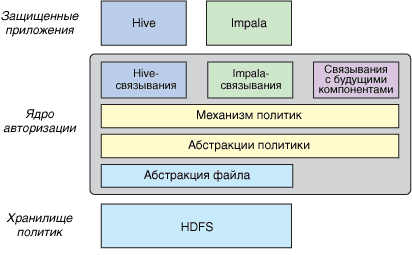
Для уточнения пользовательских привилегий (на уровне столбца и строчки) и унифицированного контроля доступа к хранению Big Data (HDFS, HBase) и организации вычислений (Spark, Hive и Impala) компания Cloudera дополняет Apache Sentry еще одним решением – RecordService. RecordService усиливает безопасность при считывании данных и уточняет разрешения, ранее выданные Sentry, а также обеспечивает динамическое маскирование данных в Hadoop. Это позволяет маскировать конфиденциальные элементы данных, защищая их при доступе в режиме реального времени [4]. Однако, начиная с дистрибутива CDH 5.13 компания Cloudera прекратила поддержку RecordService, начав работу над новым аналогичным решением, которое даст преимущества оптимизированной архитектуры, решая те же проблемы по обеспечению динамических разрешений на уровне столбцов и строк, включая несколько методов доступа к данным, в т.ч. в Spark. Возможно, это будет расширение Sentry путем добавления новой функции для контроля доступа на основе атрибутов с использованием тегов Navigator Lineage для метаданных. Предполагаемая дата релиза этого решения пока неизвестна [5].
Также стоит отметить еще одну альтернативу Sentry — Apache Ranger, разработанную в компании Hortonworks, которую в 2018 году поглотила корпорация Cloudera. Это комплексная платформа обеспечивает мониторинг cybersecurity в среде Hadoop, включая центральное управление политиками для контроля доступа к файлам, папкам, базам данных, таблицам, столбцам на HDFS, Hive и Hbase, Knox, Solr, Kafka, и YARN. Ranger поддерживает многие методы авторизации, в т.ч. RBAC и доступ на основе атрибутов, обеспечивая централизованное администрирование безопасности, контроль доступа и детальный аудит доступа пользователей. В отличие от Sentry, Apache Ranger позволяет самостоятельно расширить его функциональность с помощью (UDF, User Defined Function), задав свою собственную политику безопасности, например, на основе геолокации. Также Ranger поддерживает основанные на времени правила [6]. Отметим, что сначала RBAC-авторизация с помощью Ranger работала только с Apache Hive, но с 2019 года это доступно и в Impala [7].
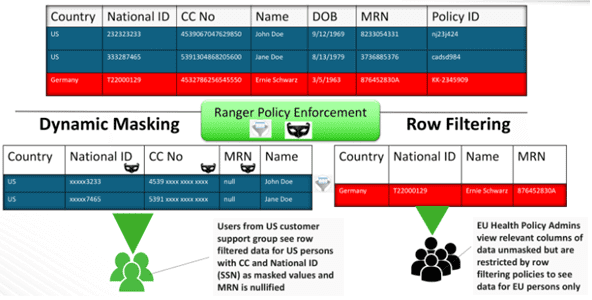
Резюмируя описанию инструментов cybersecurity для SQL-on-Hadoop, отметим, что на практике в большинстве случаев используется сочетание Kerberos-аутентификации с RBAC-авторизацией в рамках Apache Sentry или Ranger. Причем последние продукты пока считаются взаимозаменяемыми. В следующей статье мы подведем итог сравнению Hive и Impala, рассмотрев аргументы в пользу того или иного SQL-решения для Apache Hadoop.
Обеспечьте надежную защиту своих больших данных в Apache Hive и Cloudera Impala, освоив эти технологии на наших практических курсах в лицензированном учебном центре обучения и повышения квалификации ИТ-специалистов (менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data) в Москве:
Источники
- https://www.ibm.com/developerworks/ru/library/se-hadoop/index/
- https://ru.wikipedia.org/wiki/Управление_доступом_на_основе_ролей
- https://ru.wikipedia.org/wiki/Kerberos
- https://www.cloudera.com/about/news-and-blogs/press-releases/2015-09-28-cloudera-introduces-recordservice-for-the-apache-hadoop-ecosystem/
- https://community.cloudera.com/t5/Support-Questions/Cloudera-RecordService-dead/td-p/84604
- https://community.cloudera.com/t5/Support-Questions/difference-between-Ranger-and-sentry/td-p/238281
- https://docs.cloudera.com/runtime/7.0.1/impala-manage/topics/impala-authorization/

