 448
448 
Сегодня разберемся, когда для Data Science-проектов вместо Apache Spark, самого популярного вычислительного движка аналитики больших данных, стоить выбрать Dask – легковесную Python-библиотеку для параллельных вычислений. И, наоборот, в каких случаях инженер данных и Data Scientist получают преимущества, выбирая Spark.
Что такое Dask и зачем он нужен Data Scientist’у
Прежде чем погрузиться в тонкости сравнения Spark и Dask, напомним, когда возникают эти трудности выбора. Обычно Data Scientist задается таким вопросом, когда данных действительно много и привычные Python-библиотеки типа Pandas или Numpy не справляются с этим объемом вычислений. Ускорить обработку данных, распараллелив вычисления, помогут соответствующие технологии Big Data, к которым относятся такие фреймворки как Apache Spark и Flink. Они предоставляют Python API и поддерживают как пакетную, так и потоковую обработку датафреймов. Однако, написать полноценное PySpark- или PyFlink-приложение сложнее, чем Python-скрипт: разработчику нужно знать хотя бы основы работы этих феймворков, которые состоят из множества взаимосвязанных компонентов. Поэтому Data Scientist может выбрать более привычное Python-решение в виде легковесного модуля Dask, который предназначен для работы с большими данными и позволяет масштабировать библиотеки Pandas и NumPy. Как и Spark, Dask поддерживает параллельное выполнение и обрабатывает массивы данных и датафреймы, не занимающие память. В отличие от Spark и Flink, написанных на Scala, языком разработки Dask является Python, с которым работает каждый Data Scientist. Тем не менее, хотя Dask написан на Python и действительно поддерживает только этот процедурный язык программирования, фреймворк хорошо взаимодействует с C/C++/Fortran/LLVM или другими языками, скомпилированными в собственном коде Python-программы.
Dask имеет много общего со Spark. Как и Spark, Dask поддерживает отложенные вычисления (lazy evaluation), когда при запуске команды фактическое действие не выполняется, а добавляется в направленный граф выполнения (DAG, Directed Acyclic Graph). А при вызове команды выполнения Dask оптимизирует этот DAG. Управлять графом выполнения Dask можно с помощью методов .compute() и .persist().
Другое сходство — возможность масштабирования за счет развертывания кластеров. Как и Spark, планировщик Dask можно развернуть на кластере машин с использованием различных технологий. При этом можно работать со множестовом worker’ов Dask, а их ресурсами будет управлять планировщик. Но, в отличие от Spark, Dask может работать без планировщика – достаточно просто импортировать dask.dataframe.
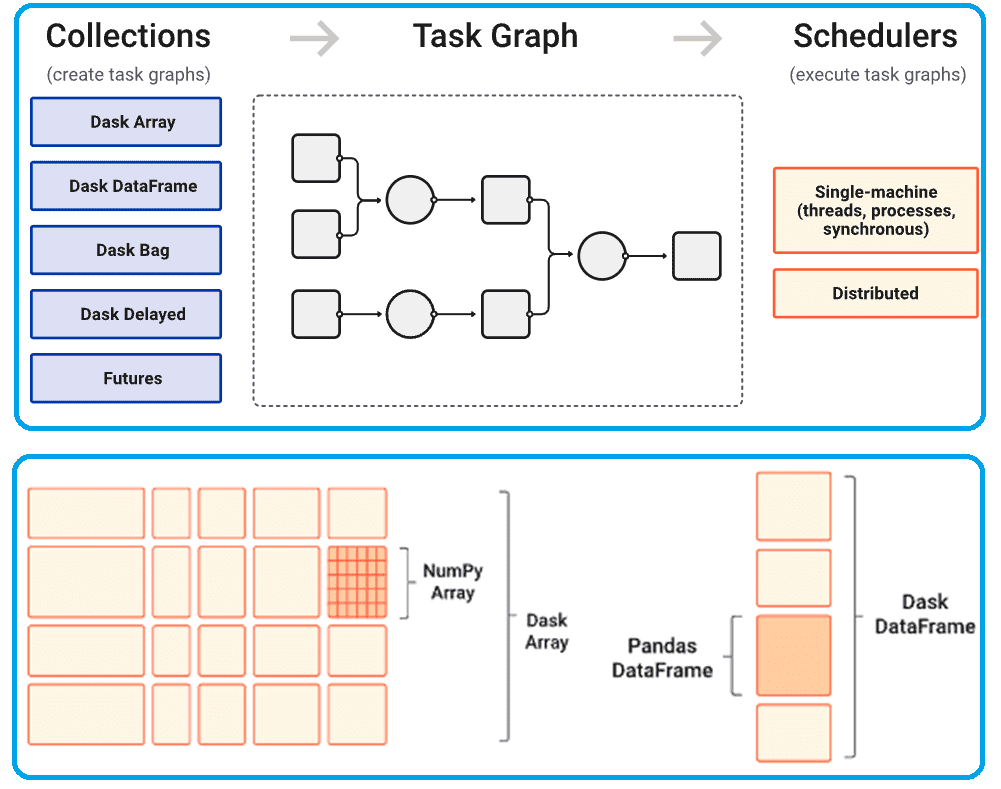
Хотя датафреймы Pandas являются основной структурой данных Dask, не стоит рассматривать Dask как масштабируемый Pandas. В отличие от Pandas, объекты Dask неизменяемы и не поддерживают inplace-операции. Поэтому в Dask нельзя присваивать новые значения с помощью метода loc(). Однако, Dask предлагает метод map_partitions(), который поддерживает операции Pandas для каждого раздела. Это упрощает разработку и отладку DS-проекта: Data Scientist по-прежнему может использовать привычный Pandas API, отлаживать свои Python-скрипты с помощью простого планировщика и развертывать в распределенном режиме.
Кроме того, Dask тесно интегрирован с другой популярной DS-библиотекой — SciKit-Learn и наследует ее API. Это можно рассматривать как преимущество перед Spark, поскольку MLLib использует совершенно другой, более сложный API. Также Dask предлагает некоторые собственные алгоритмы предварительной обработки и машинного обучения, начиная от линейных моделей и наивного Байеса и заканчивая кластеризацией, декомпозицией и XG-Boost. При этом Dask поддерживает распараллеливание большинства моделей SKLearn в качестве серверной части для библиотеки JobLib. Наконец, когда нужно обучить ML-модель на небольшом наборе данных, но использовать на большом, Dask предлагает оболочку ParallelPostFit для моделей SciKit-Learn. Эта оболочка позволяет любой модели SKLearn поддерживать датафреймы и массивы Dask в их методе predict().
Тем не менее, Apache Spark способен справляться с гораздо большими нагрузками, чем Dask. В частности, Spark отлично справляется терабайтными объемами и даже больше. Кроме того, Spark позволяет манипулировать данными с помощью SQL-запросов, а Dask – нет, что является недостатком феймворка с точки зрения аналитика данных. Наконец, Spark является более зрелым проектом и частью Big Data экосистемы Apache, включая тесную интеграцию с NoSQL-хранилищами и инструментами стека SQL-on-Hadoop типа Hive и Iceberg. О других отличиях Spark и Dask поговорим далее.
Spark vs Dask: 10 главных отличий
Сравним 2 вычислительных фреймворка по следующим критериям:
- экосистема;
- зрелость;
- сфера практического применения;
- архитектурный дизайн;
- масштабирование;
- API;
- Работа с массивами;
- Потоковая обработка данных;
- Машинное обучение;
- Графы.
С точки зрения экосистемы, Spark является комплексным фреймворком, который отлично интегрируется со многими другими проектами Apache: Hive, Kafka, Iceberg, HDFS и пр. Dask ;t является компонентом более крупной экосистемы Python, сочетается с библиотеками NumPy, Pandas и Scikit-Learn, расширяя и дополняя их.
Spark может похвастаться более длительной историей существования (с 2010 года), что также повлияло на популярность этого вычислительного движка в мире Big Data. Dask моложе всего на 4 года, однако, распространен намного меньше своего конкурента. Возможно, на это также повлияла сфера применения: Spark считается универсальным инструментом и хорошо подходит для корпоративного использования, предоставляя API Java, востребованный в enterprise-сегменте. Dask же поддерживает только язык DS-проектов, Python, более распространенный в научных и исследовательских сценариях.
Архитектура и внутренняя модель Spark является более абстрактной, обеспечивая хорошую высокоуровневую оптимизацию для единообразно применяемых вычислений. Обратной стороной этого достоинства является недостаточная гибкость для более сложных ML-алгоритмов, которые не укладываются в Spark-расширение парадигмы Map-Shuffle-Reduce.
Внутренняя модель Dask имеет более низкий уровень абстракции, поэтому в ней отсутствуют высокоуровневые оптимизации, но она способна реализовывать более сложные алгоритмы и создавать более сложные индивидуальные системы. Dask основан на общем планировании задач.
Spark масштабируется до множества кластеров на тысячи узлов, а для Dask 1000 узлов – это предел. Spark DataFrame имеет собственный API и модель памяти, поддерживая все операторы ANSI SQL, включая высокоуровневый оптимизатор для сложных запросов.
Dask DataFrame использует API Pandas и модель памяти, не поддерживая SQL-запросы. Он может выполнять произвольный доступ к данным, эффективные операции с временными рядами и другие индексированные операции в стиле Pandas.
Для машинного обучения в Apache Spark есть соответствующая библиотека MLLib, которая представляет собой целый проект с поддержкой общих операций расширенной парадигмы Map-Shuffle-Reduce. Впрочем, некоторые другие библиотеки машинного обучения на основе JVM типа H2O, могут похвастаться более высокой производительностью по сравнению с MLLib. Dask опирается на ML-библиотеки Scikit-Learn и XGBoost, а также полностью поддерживает модель NumPy для масштабируемых многомерных массивов. Spark же изначально не включает поддержку многомерных массивов, хотя в MLLib можно работать с двумерными матрицами. Справедливости ради стоит отметить, что эти возможности лучше реализованы в проекте Thunder, который сочетает Apache Spark с массивами NumPy.
С точки зрения потоковой обработки событий, Spark Streaming и Structured Streaming отлично подходят для вычислений в режиме почти реального времени, обеспечивая высокую производительность при больших однородных потоковых операциях. Dask тоже real-time интерфейс, но он пока намного медленнее потоковой передачи Spark и еще не отличается зрелостью. Наконец, в отличие от Dask, Spark предоставляет библиотеки для обработки графов: GraphFrames и GraphX, что является конкурентным преимуществом фреймворка в задачах аналитики больших данных с помощью графовых алгоритмов.
С точки зрения параллелизма Spark предполагает, что пользователи будут составлять вычисления из высокоуровневых примитивов (сопоставление, сокращение, группировка, соединение и пр.). Также можно расширить Spark за счет создания подклассов RDD, хотя на практике это делается редко. Dask же позволяет указывать произвольные графы задач для более сложных и настраиваемых систем, не входящих в стандартный набор распределенных коллекций данных.
И Spark, и Dask представляют вычисления с ориентированными ациклическими графами. Однако эти DAG представляют вычисления с очень разной степенью детализации. Одна операция в Spark RDD может добавить к графу такие узлы, как Map и Filter. Это высокоуровневые операции, которые в конечном итоге будут превращены во множество небольших задач, выполняемые на отдельных worker’ах. Это состояние «много маленьких задач» доступно только внутри планировщика Spark. Dask-графы пропускают это высокоуровневое представление и переходят непосредственно к этапу множества маленьких задач. Поэтому одна операция Map в коллекции Dask немедленно сгенерирует и добавит, возможно, тысячи крошечных задач в DAG. Эта разница в масштабе базового графа влияет на виды анализа и оптимизации, которые можно выполнять, а также на универсальность, которую они предоставляют пользователям. Dask не может выполнить некоторые оптимизации, которые поддерживает Spark, потому что планировщики Dask не имеют нисходящей картины вычислений, что им нужно выполнить. Однако, Dask может легко представлять гораздо более сложные алгоритмы и предоставлять возможность создания этих алгоритмов обычным пользователям.
Впрочем, несмотря на отмеченные отличия, Dask и Spark можно использовать вместе с одними и теми же данными и в одном кластере. Большинство кластеров предназначены для одновременной поддержки множества различных распределенных систем с использованием менеджеров ресурсов, таких как Kubernetes и YARN. Если есть кластер, где уже запускаются рабочие нагрузки Spark, там же можно запускать рабочие нагрузки Dask в текущей инфраструктуре и наоборот. Например, используя популярный в экосистеме Hadoop диспетчер ресурсов YARN, можно развернуть Dask с помощью соответствующего проекта, а также других аналогов, таких как JupyterHub на Hadoop. Оба фреймворка могут как читать, так и записывать общие форматы данных (CSV, JSON, ORC и Parquet), что упрощает передачу результатов между рабочими процессами.
В заключение отметим, что с точки зрения дата-инженерии Spark является зрелым и подходящим инструментом для типичных ETL-процессов и SQL-операций, а также поддержке Java/Scala. Dask же более легковесный фреймворк, который легче интегрировать в существующий код и инфраструктуру. Если в Data Science проекте нужно добавить гибкий параллелизм к существующим решениям, он будет отличным решением, особенно там, где уже используются Python и его библиотеки, такие как NumPy, Pandas и sklearn.
Освойте администрирование и использование Apache Spark для задач дата-инженерии, разработки распределенных приложений и аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники

