 1582
1582 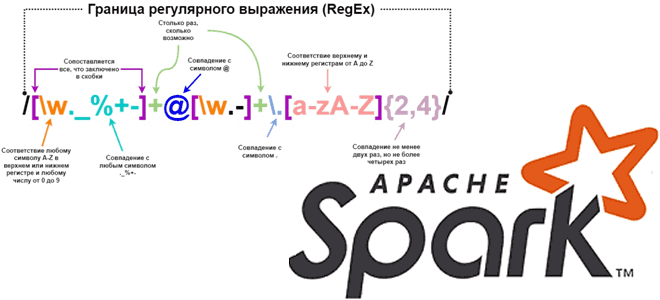
Каждый дата-инженер и аналитик данных активно использует регулярные выражения для поиска значений в тексте по заданному шаблону. Сегодня рассмотрим, как это сделать с функциями regexp_replace(), rlike() и regexp_extract в Apache Spark на примере небольшого PySpark-приложения.
Как работает функция regexp_replace()
Регулярным выражением называется последовательность символов, задающая шаблон соответствия в тексте. Например, регулярные выражения часто используются с SQL-оператором LIKE и поддерживаются почти во всех реляционных СУБД. Apache Spark тоже имеет подобную функцию. В Python-интерфейсе Apache Spark, PySpark есть несколько функций, которые выполняют сопоставление регулярных выражений: regexp_replace(), rlike() и regexp_extract. Начиная с версии 3.4.0, о которой мы писали здесь, эти функции поддерживается в Spark Connect. Расcмотрим подробнее, чем они отличаются и как используются.
Начнем с regexp_replace(). Как следует из названия, эта функция заменяется все подстроки, если в строке будет найдено совпадение с регулярным выражением. Функция находится в пакете pyspark.sql.functions и имеет следующий синтаксис:
regexp_replace(string: ColumnOrName, pattern: Union[str, Column], replacement: Union[str, Column])
Эта функция заменяет все подстроки указанного строкового значения, соответствующие регулярному выражению, другой подстрокой. Так можно заменить строковое значение столбца другой строкой. Функция regexp_replace() возвращает столбец. Если соответствий заданному регулярному выражению не найдено, функция возвращает пустую строку. Чтобы продемонстрировать, как это работает, напишем небольшое PySpark приложение, которое генерирует фейковые данные о 10 клиентах и заменяет сокращения обозначений населенных пунктов в адресе полным наименованием, например, «п.» на «поселок», а «г.» на «город».
!pip install pyspark
!apt-get install openjdk-8-jdk-headless -qq > /dev/null
!pip install faker
#импорт модулей
from pyspark.sql import SparkSession
import pyspark
import sys
import os
import random
os.environ["JAVA_HOME"] = "/usr/lib/jvm/java-8-openjdk-amd64"
# Импорт модуля faker
from faker import Faker
from faker.providers.address.ru_RU import Provider
from pyspark.sql.functions import regexp_replace
# Создаем объект SparkSession и устанавливаем имя приложения
spark = SparkSession.builder.appName("MySparkApp").getOrCreate()
# Import and configure random data generator Faker
fake = Faker('ru_RU')
fake.add_provider(Provider)
# Create empty list to store generated data
data1 = []
# Generate data and add to list
for i in range(10):
k= random.randint(0, 1)
name = fake.name()
address=fake.city()
data1.append((i, name, random.randint(18, 100), address))
#Create dataframe from data list
df = spark.createDataFrame(data1, schema=['id', 'client', 'age', 'address'])
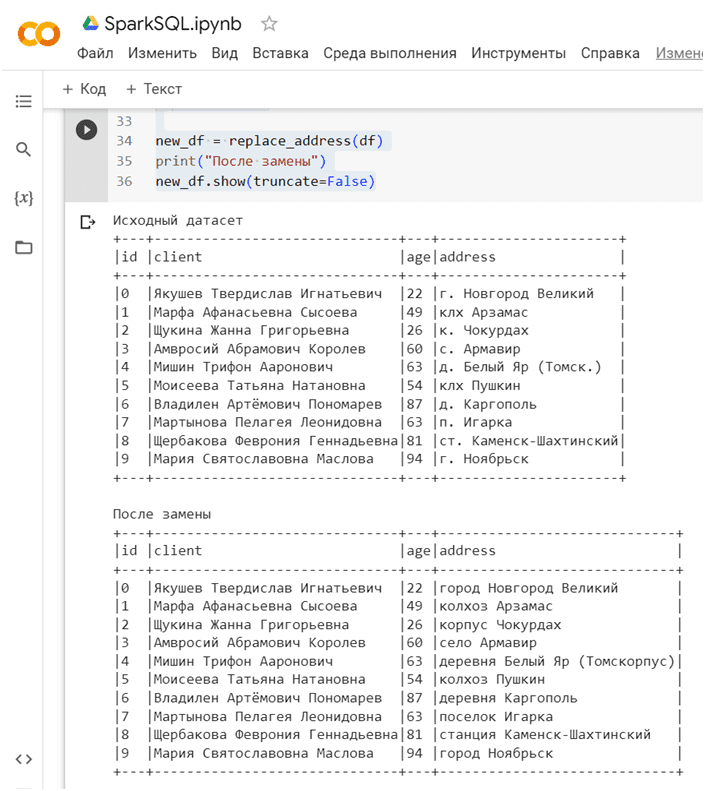
print("Исходный датасет")
df.show(truncate=False)
def replace_address(df):
df = df.select('id', 'client', 'age', regexp_replace('address', 'г\.', 'город').alias('address'))
df = df.select('id', 'client', 'age', regexp_replace('address', 'д\.', 'деревня').alias('address'))
df = df.select('id', 'client', 'age', regexp_replace('address', 'с\.', 'село').alias('address'))
df = df.select('id', 'client', 'age', regexp_replace('address', 'п\.', 'поселок').alias('address'))
df = df.select('id', 'client', 'age', regexp_replace('address', 'ст\.', 'станция').alias('address'))
df = df.select('id', 'client', 'age', regexp_replace('address', 'клх', 'колхоз').alias('address'))
return df
new_df = replace_address(df)
print("После замены")
new_df.show(truncate=False)
Результаты вывода и замены с помощью regexp_replace():
Функции rlike() и regexp_extract() в Spark SQL
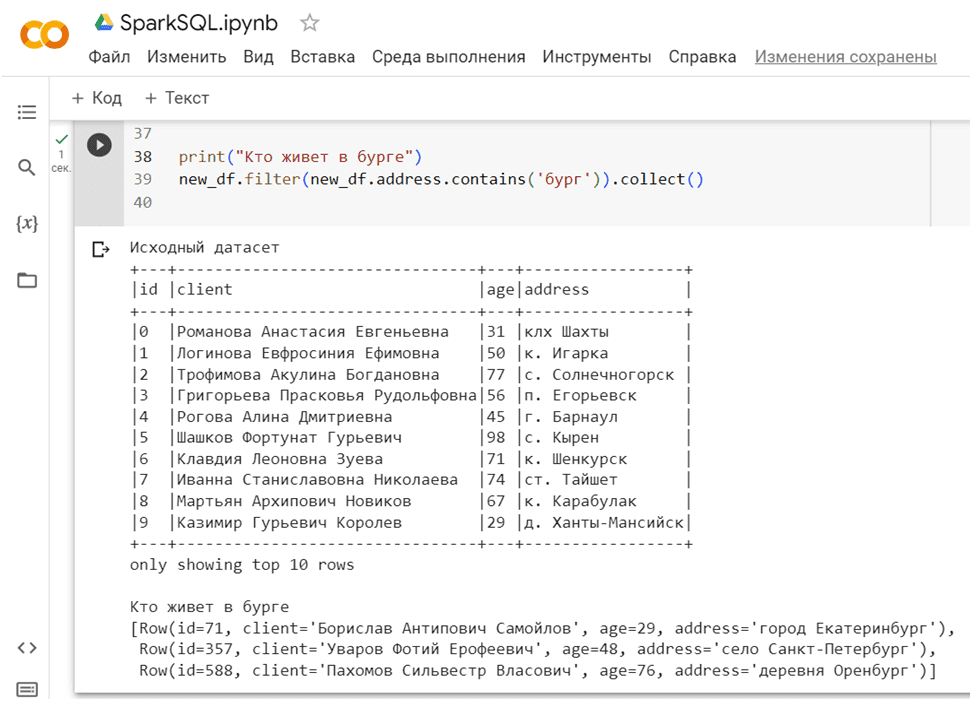
Функция rlike() возвращает Возвращает логическое значение Column на основе совпадения с регулярным выражением. логический столбец на основе совпадения строки с заданным регулярным выражением. Это функция класса org.apache.spark.sql.Column. С ее помощью можно найти записи, содержищие указанную подстроку. Например, найти всех клиентов, проживающих в населенных пунктах, названия которых содержат строку ‘бург’: Санкт-Петербург, Оренбург, Екатеринбург и пр. Для этого следует написать такой участок кода:
print("Кто живет в бурге")
new_df.filter(new_df.address.contains('бург')).collect()
Наконец, рассмотрим еще одну функцию, которая позволяет работать с регулярными выражениями в Apache Spark — regexp_extract(). — извлечение определенной группы, соответствующей регулярному выражению Java, из указанного столбца строки. Если регулярное выражение не совпало или указанная группа не совпала, возвращается пустая строка. Функция находится в модуле pyspark.sql.functions и имеет следующий синтаксис:
regexp_extract(str: ColumnOrName, pattern: str, idx: int). Функция принимает 3 аргумента:
- str — столбец, по которому надо найти записи, соответствующие заданному выражению;
- pattern — шаблон регулярного выражения для извлечения подстроки из указанного столбца;
- idx — часть совпадения, которую нужно извлечь из группы совпадений, от 0 до 9.
Чтобы продемонстрировать, как она работает, немного изменим код генерации случайных адресов. Код PySpark-приложения теперь будет следующим:
from pyspark.sql.functions import regexp_extract
import re
# Создаем объект SparkSession и устанавливаем имя приложения
spark = SparkSession.builder.appName("MySparkApp").getOrCreate()
# Import and configure random data generator Faker
fake = Faker('ru_RU')
fake.add_provider(Provider)
# Create empty list to store generated data
data1 = []
# Generate data and add to list
for i in range(1000):
k= random.randint(0, 1)
name = fake.name()
address=fake.address()
data1.append((i, name, random.randint(18, 100), address))
#Create dataframe from data list
df = spark.createDataFrame(data1, schema=['id', 'client', 'age', 'address'])
print("Исходный датасет")
df.show(10, truncate=False)
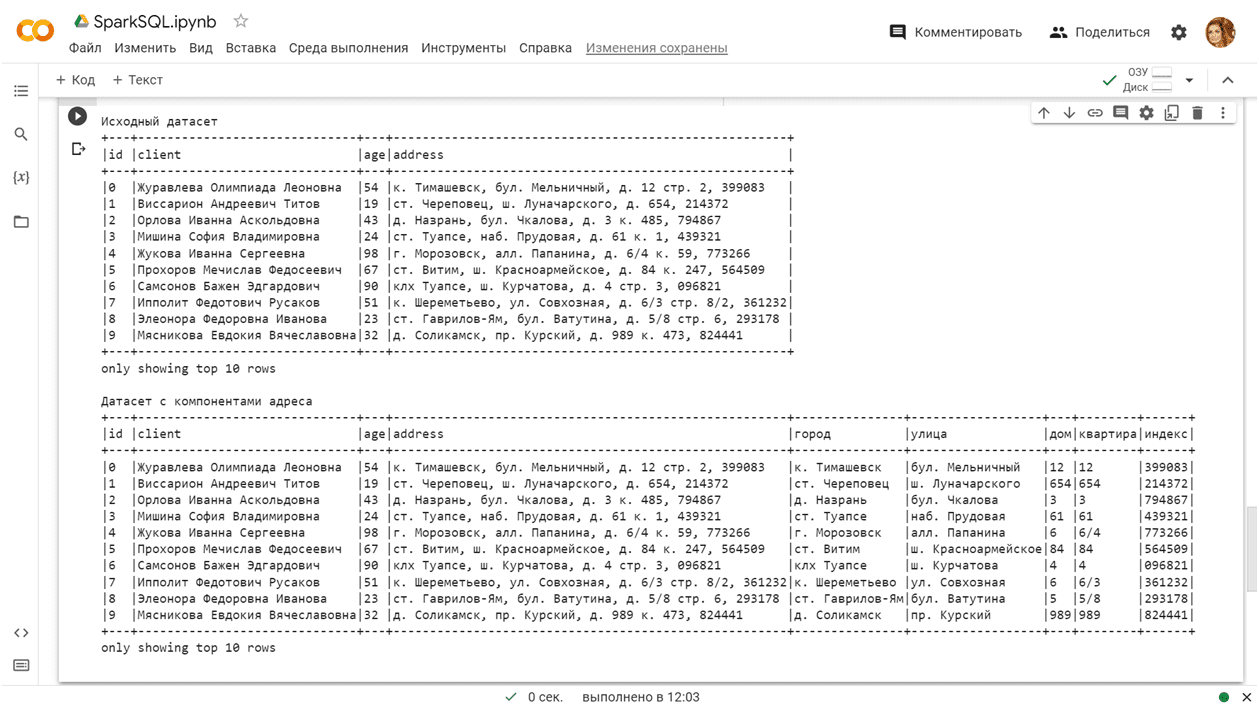
Теперь воспользуемся функцией regexp_extract() для извлечения каждого компонента адреса в отдельный столбец:
# Извлечение города
df = df.withColumn("город", regexp_extract(df["address"], r"([^,]+)", 1))
# Извлечение улицы или переулка
df = df.withColumn("улица", regexp_extract(df.address, r", (.+), д.", 1))
# Извлечение номера дома
df = df.withColumn("дом", regexp_extract('address', r'д\. (\d+)', 1))
# Извлечение номера квартиры
df = df.withColumn("квартира", regexp_extract("address", r"\d+(?:/\d+)?", 0))
# Извлечение индекса
df = df.withColumn("индекс", regexp_extract(df.address, r'\d+$', 0))
# Show updated dataframe
print("Датасет с компонентами адреса")
df.show(10, truncate=False)
Результаты вывода:
Функция regexp_extract() для меня оказалась самой сложной, поскольку в ней очень много параметров:
- «r» перед строкой регулярного выражения указывает на то, что это сырая строка, и экранирование не требуется;
- «([^,]+)» означает любой символ, кроме запятой, повторяющийся один или несколько раз;
- «, (.+), д.» означает запятую, пробел, любой символ один или несколько раз, запятую, пробел, «д»;
- «д\. (\d+)» означает «д.» (с символом экранирования перед точкой), пробел, одну или несколько цифр;
- «\d+(?:/\d+)?» означает одну или несколько цифр, за которыми может следовать «/» и еще одна группа цифр (необязательно);
- «\d+$» означает одну или несколько цифр, которые являются последними символами строки – использовалось для поиска индекса.
Номер группы в regexp_extract() указывает на то, какую конкретную группу в регулярном выражении нужно извлечь. Группы в регулярном выражении определяются с помощью круглых скобок. Каждая группа может быть обозначена уникальным номером, начиная с 1. В регулярных выражениях группа — это подмножество символов, которое ограничено круглыми скобками (). Группы позволяют группировать символы вместе и применять к ним определенные операции или преобразования. С помощью групп можно извлекать подстроку из строки, группировать символы вместе и применять к ним операции, а также использовать обратные ссылки, которые представляют собой ссылки на предыдущие группы в регулярном выражении, чтобы сопоставлять повторяющиеся или симметричные паттерны в строке. В случае нашего примера группа с номером 1 означало первое совпадение с заданным в регулярном выражении шаблоне, а 0 – весь шаблон, что использовалось для числовых значений в индексе.
Узнайте про все возможности Apache Spark для разработки приложений аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Основы Apache Spark для разработчиков
- Анализ данных с Apache Spark
- Потоковая обработка в Apache Spark
- Машинное обучение в Apache Spark
- Графовые алгоритмы в Apache Spark
[elementor-template id=»13619″]
Источники
- https://blog.devgenius.io/regular-expression-regexp-in-pyspark-e5f9b5d9617a
- https://sparkbyexamples.com/spark/spark-rlike-regex-matching-examples/
- https://linuxhint.com/pyspark-regexp-extract/

