 1162
1162 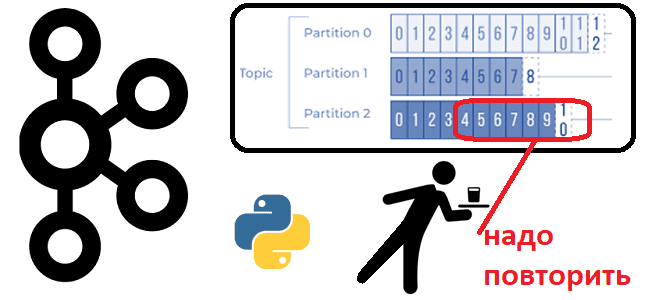
Иногда возникает потребность в повторном чтении данных из Apache Kafka с определенного момента времени. Сегодня рассмотрим, как это сделать, написав простенький Python-скрипт потребления из раздела топика.
Публикация данных в Kafka
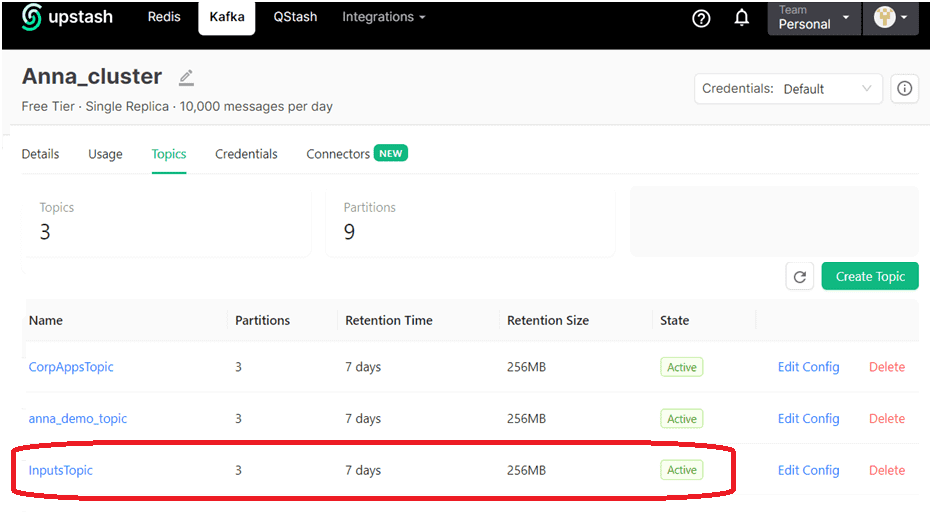
В качестве примера возьмем ранее рассмотренный в этой статье кейс приема потока обращений в интернет-магазин. Обращения могут представлять собой заявки от частных лиц и корпоративных клиентов на покупку товаров, а также вопросы по работе магазина, доставке или оплате. Все входящие обращения будут публиковаться в топик, который состоит из 3-х разделов. В раздел с номером 0 будут попадать все вопросы, в раздел с номером 1 – все корпоративные заявки, а в раздел 2- частные. Как обычно, я создала топик Kafka на инстансе, развернутом в облачной serverless-платформе Upstash. Топик называется InputsTopic и имеет 3 раздела.
Код продюсера, отправляющего клиентские обращения, написан на Python с использованием библиотеки kafka-python. В этом коде с использованием библиотеки Faker случайно формируются сообщения от частных или корпоративных клиентов и публикуются в топик каждые 3 секунды. Разделение сообщений по разделам реализуется с помощью явного указания раздела в методе продюсера send(). В этом случае ключ партиционирования игнорируется.
Сперва установим библиотеки и импортируем необходимые для работы модули:
####################################ячейка в Google Colab №1 - установка и импорт библиотек########################################### #установка библиотек !pip install kafka-python !pip install faker #импорт модулей import json import random from datetime import datetime import time from time import sleep from kafka import KafkaProducer # Импорт модуля faker from faker import Faker
Затем напишем сам скрипт формирования и публикации заявок:
####################################ячейка в Google Colab №2 - публикация сообщений в Kafka###########################################
# объявление продюсера Kafka
producer = KafkaProducer(
bootstrap_servers=[kafka_url],
sasl_mechanism='SCRAM-SHA-256',
security_protocol='SASL_SSL',
sasl_plain_username=username,
sasl_plain_password=password,
value_serializer=lambda v: json.dumps(v).encode('utf-8'),
)
# Создание объекта Faker с использованием провайдера адресов для России
fake = Faker()
#списки полей в заявке
products = ['bred', 'garlic', 'oil', 'apples', 'water', 'soup', 'dress', 'tea', 'cacao', 'coffee', 'bananas', 'butter', 'eggs', 'oatmeal']
questions = ['payment', 'delivery', 'discount', 'vip', 'staff']
#бесконечный цикл публикации данных
while True:
#подготовка данных для публикации в JSON-формате
now=datetime.now()
id=now.strftime("%m/%d/%Y %H:%M:%S")
content = ''
theme = ''
corp = 0
part = 0
#подготовка списка возможных ключей маршрутизации (routing keys)
corp = random.choice([1,0])
if corp==1 :
#name = random.choice(names_corp)
name=fake.company()
routing_keys = ['app' + '.company.' + name, 'question']
else:
#name = random.choice(names_fiz)
name=fake.name()
routing_keys = ['app', 'question']
#случайный выбор одного из ключей маршрутизации (из routing keys)
subject=random.choice(routing_keys)
#добавление дополнительных данных для заголовка и тела сообщения в зависимости от темы заявки
if subject=='question':
theme = random.choice(questions)
content = 'Hello, I have a question about ' + theme
part=0 #все вопросы записывать в раздел 0
else :
theme ='app'
content = random.choice(products) + ' ' + str(random.randint(0,100))
if corp==1 :
part=1 #все корпоративные заявки записывать в раздел 1
else:
part=2 #заявки от частных лиц записывать в раздел 2
#задаем ключ сообщения для Kafka
mes_key = str.encode(subject+name)
#создаем полезную нагрузку в JSON
data = {'id': id, 'name': name, 'subject': subject, 'content': content}
#публикуем данные в Kafka
future = producer.send('InputsTopic', value=data, partition=part, key=mes_key)
record_metadata = future.get(timeout=60)
print(f' [x] Sent {record_metadata}')
print(f' [x] Corp = {corp}')
print(f' [x] Payload {data}')
# сериализуем данные в формат JSON и вычисляем размер сообщения
message_size = len(json.dumps(data).encode('utf-8'))
# выводим размер сообщения на консоль
print(f"Message size: {message_size} bytes")
#повтор через 3 секунды
time.sleep(3)
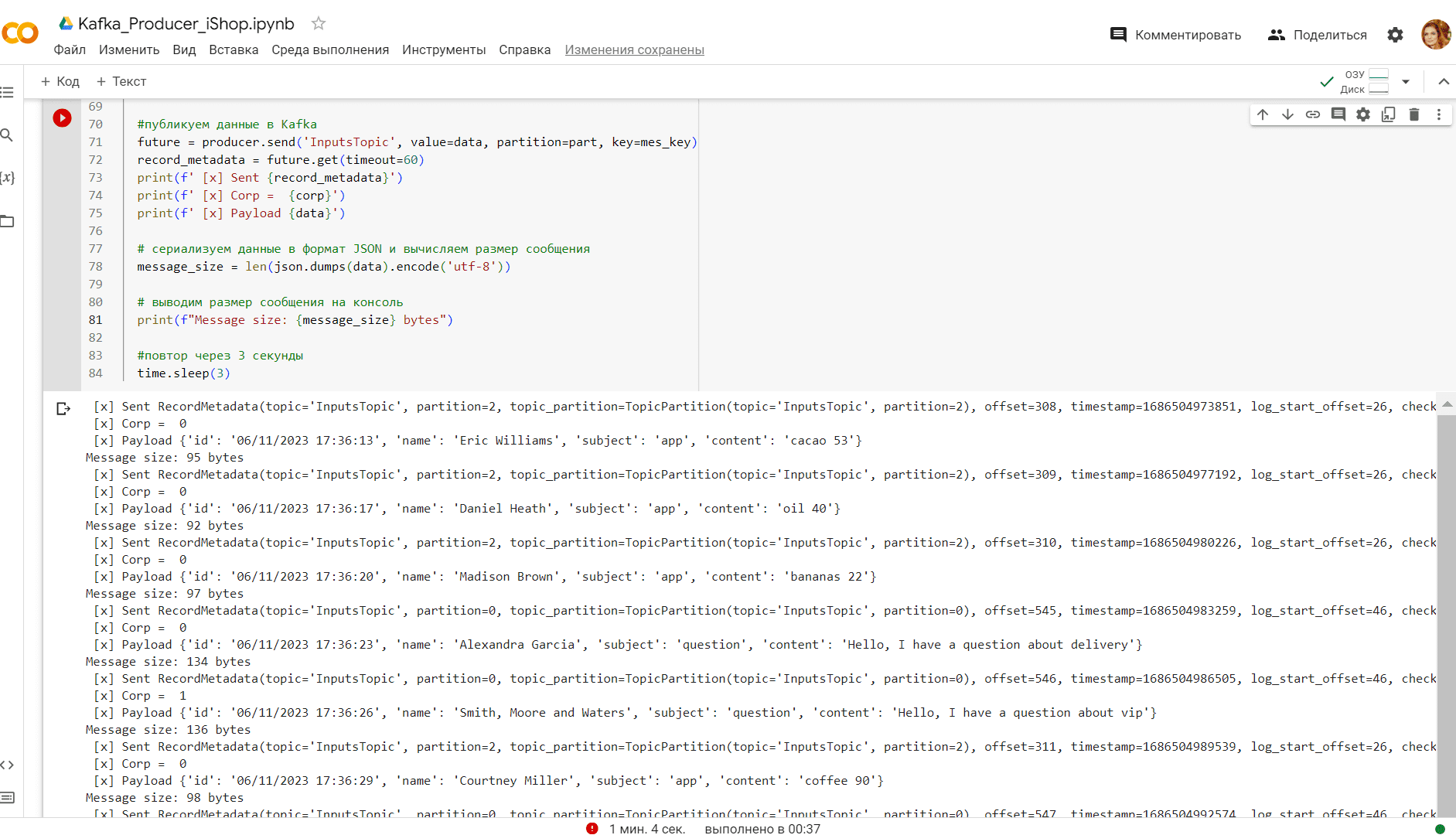
Запустив этот скрипт в Google Colab, получаем сообщения, опубликованные в Kafka согласно ранее заданной логике распределения по разделам:
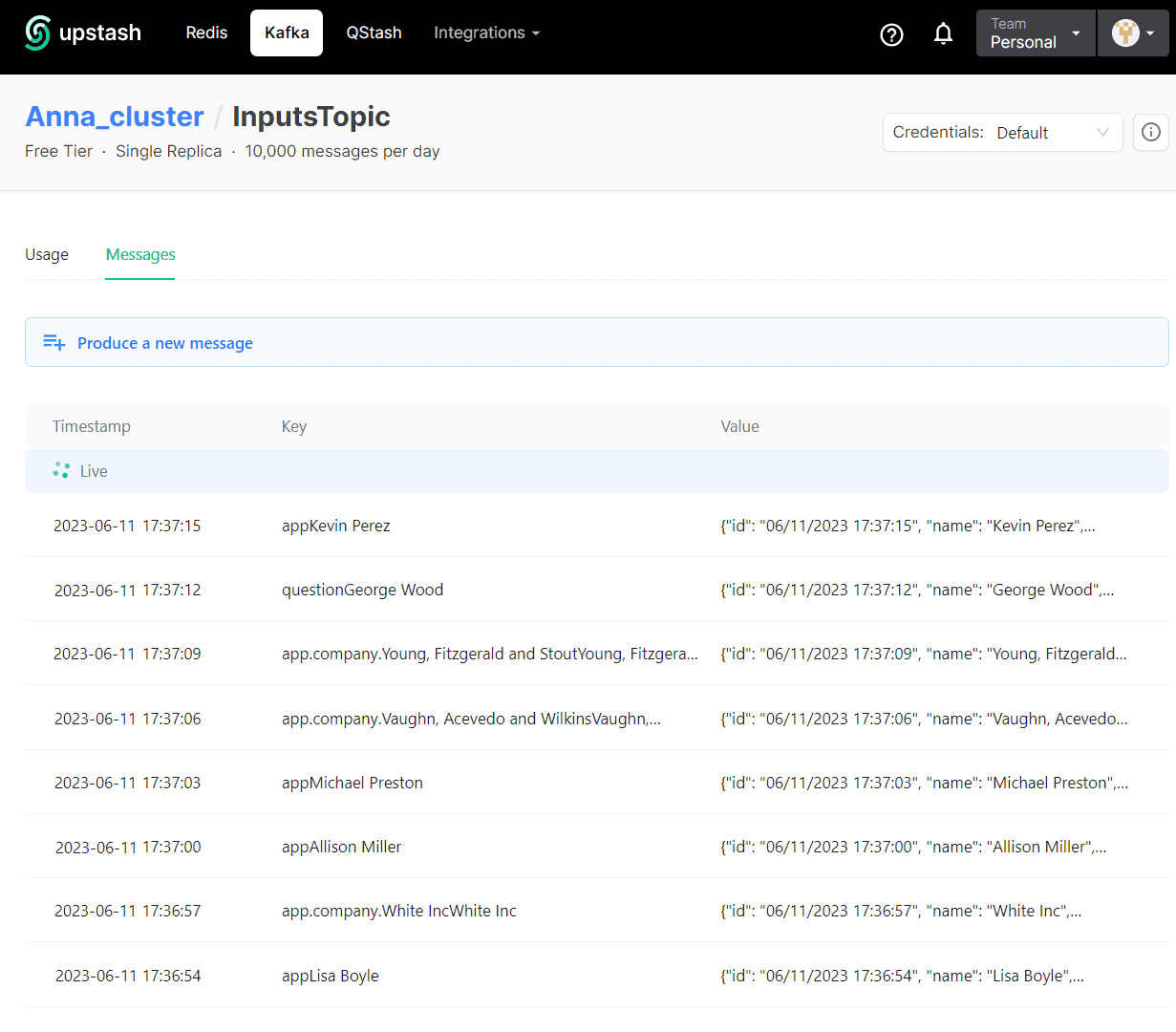
Проверить, что сообщения опубликованы, можно в GUI-интерфейсе платформы Upstash:
Предположим, в приложении-потребителе, которое обрабатывает заявки от частных лиц, случился сбой и ему необходимо повторно считать данные с момента 17:30. Как это сделать, рассмотрим далее.
Повторное потребление с определенного момента
Несмотря на наличие поля отметки времени (timestamp), которое проставляется автоматически при публикации сообщения в Kafka, хронологический порядок потребления сообщения привязан не к этому параметру, а к смещению (offset). Поэтому в коде приложения-потребителя следует указать нужную позицию начала чтения сообщений из раздела, используя метод потребителя seek(), в параметрах которого указывается раздел и смещение. Например, считать с позиции смещения 300:
offset=300 # задание нужного смещения topic_partition = TopicPartition(topic, part) # указываем имя топика и номер раздела consumer.assign([topic_partition]) #назначаем потребителя на этот топик и раздел consumer.seek(topic_partition, offset)
Однако, на практике мы обычно знаем примерное время, но не точное смещение сообщений. Поэтому необходимо выполнить небольшое преобразование от момента, заданного в привычной людям форме, к смещению. Например, нужно считать данные по заявкам частных лиц, которые были опубликованы в Kafka после 17:30 МСК 11 июня 2023 года. За это отвечает следующий участок кода:
topic_partition = TopicPartition(topic, part) # указываем имя топика и номер раздела
consumer.assign([topic_partition]) #назначаем потребителя на этот топик и раздел
# определяем момент времени, с которого начнется чтение
timestamp = datetime(2023, 6, 11, 17, 30, 0).timestamp() * 1000 # переводим в миллисекунды
# определяем смещение для каждой партиции в топике
offsets = consumer.offsets_for_times({topic_partition: timestamp})
# устанавливаем позицию для каждой партиции в топике
if offsets[topic_partition] is not None:
consumer.seek(topic_partition, offsets[topic_partition].offset)
Весь код приложения-потребителя, который считывает данные по заявкам частных лиц и заносит в определенный лист Google-таблицы, выглядит так:
####################################ячейка в Google Colab №1 - установка и импорт библиотек###########################################
#установка библиотек
!pip install kafka-python
#импорт модулей
from google.colab import auth
auth.authenticate_user()
import gspread
from google.auth import default
creds, _ = default()
import json
import random
from datetime import datetime
from kafka import KafkaConsumer
from json import loads
from kafka.structs import TopicPartition
####################################ячейка в Google Colab №2 - потребление из Kafka###########################################
#объявление потребителя Kafka
consumer = KafkaConsumer(
bootstrap_servers=[kafka_url],
sasl_mechanism='SCRAM-SHA-256',
security_protocol='SASL_SSL',
sasl_plain_username=username,
sasl_plain_password=password,
group_id='gr1',
auto_offset_reset='earliest',
enable_auto_commit=True
)
topic='InputsTopic'
#Google Sheets Autentificate
gc = gspread.authorize(creds)
# подписка потребителя на определенный раздел topic partition
#все вопросы лежат в разделе 0
#все корпоративные заявки лежат в разделе 1
#заявки от частных лиц лежат в разделе 2
part=2 #задание раздела
topic_partition = TopicPartition(topic, part) # указываем имя топика и номер раздела
consumer.assign([topic_partition]) #назначаем потребителя на этот топик и раздел
# определяем момент времени, с которого начнется чтение
timestamp = datetime(2023, 6, 11, 17, 30, 0).timestamp() * 1000 # переводим в миллисекунды
# определяем смещение для каждой партиции в топике
offsets = consumer.offsets_for_times({topic_partition: timestamp})
# устанавливаем позицию для каждой партиции в топике
if offsets[topic_partition] is not None:
consumer.seek(topic_partition, offsets[topic_partition].offset)
#Открытие заранее созданного файла Гугл-таблицы по идентификатору (взять из его URL, например, у меня это https://docs.google.com/spreadsheets/d/1ZQuotMVhaOuOtnZ56mvd1zX-5JOhsXc1WTG6GTBjzzM)
sh = gc.open_by_key('1ZQuotMVhaOuOtnZ56mvd1zX-5JOhsXc1WTG6GTBjzzM')
wks = sh.worksheet("Partition_"+ str(part)) #в какой лист гугл-таблиц будем записывать
#начальный номер строки для записи данных
x=1
#считывание из топика Kafka
for message in consumer:
payload=message.value.decode("utf-8")
data=json.loads(payload)
print(f"Offset: {message.offset}, Value: {message.value}")
print(consumer.position(topic_partition)) # выводим текущее смещение
print(f"Timestamp: {message.timestamp}, Value: {message.value}")# выводим текущую метку времени
timestamp = message.timestamp / 1000.0 # переводим метку времени в секунды
datetime_object = datetime.fromtimestamp(timestamp) # преобразуем метку времени в объект datetime
formatted_timestamp = datetime_object.strftime('%Y-%m-%d %H:%M:%S.%f') # форматируем вывод метки времени
print(f"Timestamp: {formatted_timestamp}, Value: {message.value}")
#вывод исходных данных в консоль Goggle Colab
print(data)
#парсинг JSON-сообщения полезной нагрузки
id=data['id']
name=data['name']
subject = data['subject']
content = data['content']
#вывод распарсенных данных в консоль Google Colab
print('Заявка № ', id, ', клиент ', name, ', тема: ", subject, ', 'содержимое: ', content)
#обновление данных в в Гугл-таблице
global x
#переход на следующую строку в гугл-таблицах
x = x + 1
#запись данных в ячейки гугл-таблицы
wks.update_cell(x,1,id)
wks.update_cell(x,2,name)
wks.update_cell(x,3,content)
Запуск этого скрипта в Google Colab выводит результаты считывания на консоль:
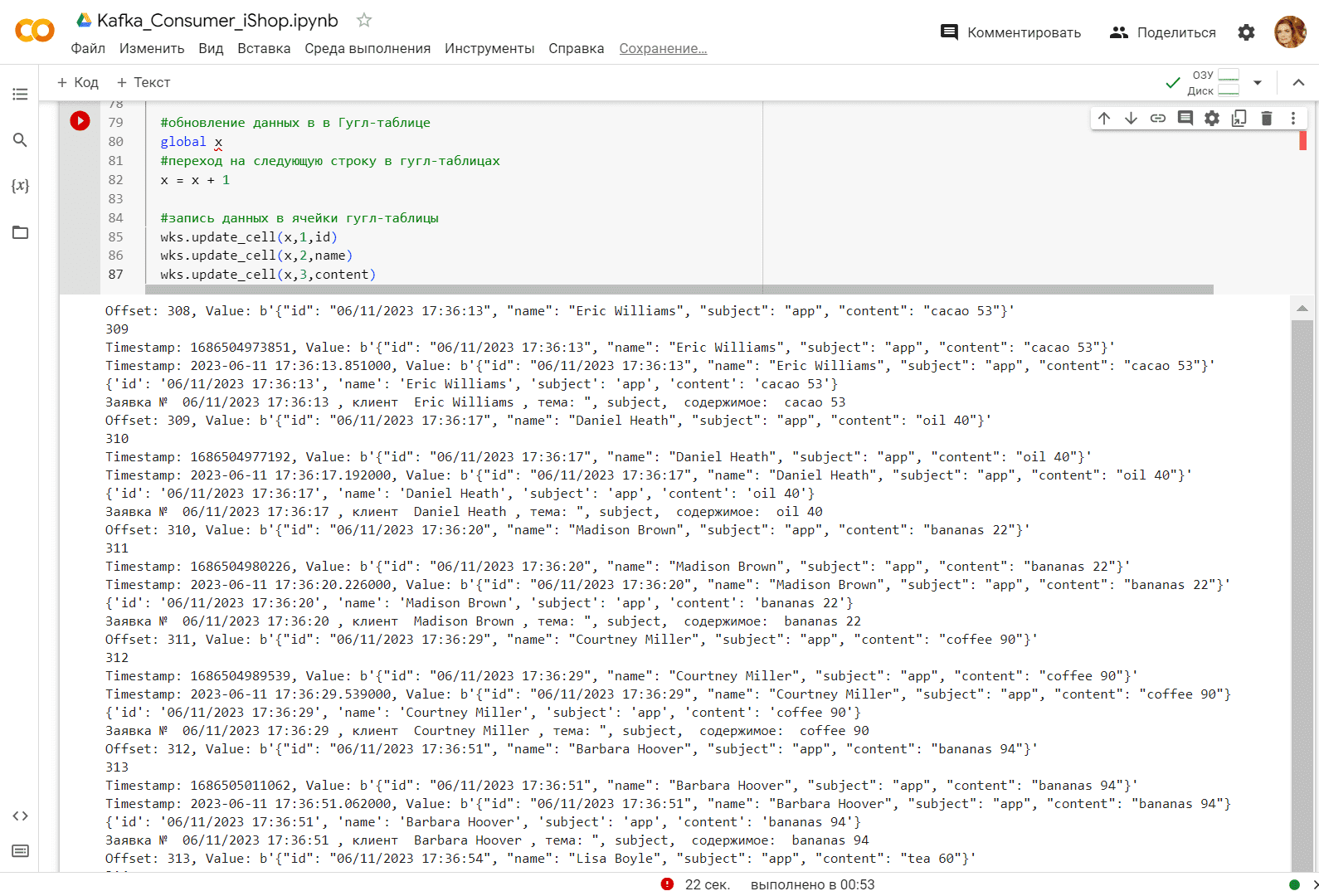
В гугл-таблице потребленные данные также отображаются:
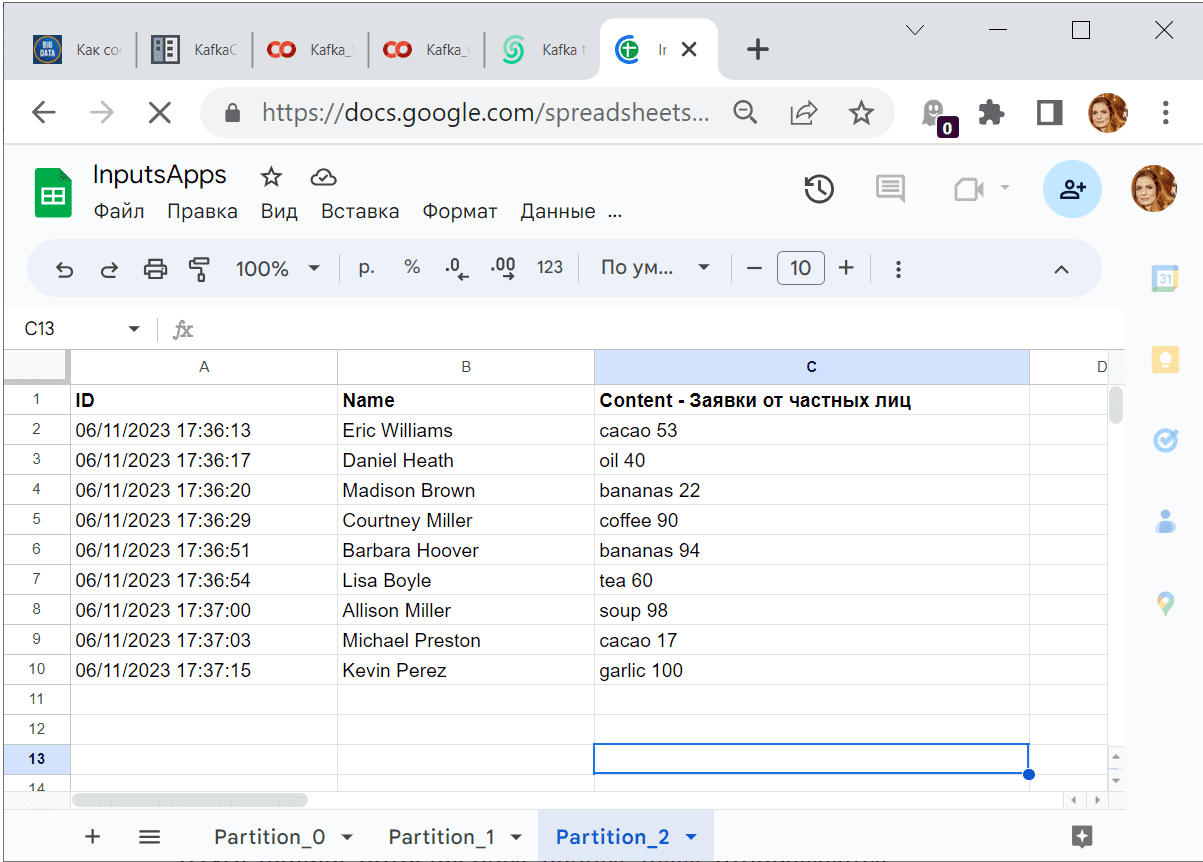
Таким образом, используя всего несколько дополнительных методов библиотеки kafka-python, можно считать данные из Kafka повторно с нужного смещения или даже заданного момента времени.
Еще больше полезных приемов администрирования и эксплуатации Apache Kafka для потоковой аналитики больших данных вы узнаете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Администрирование кластера Kafka
- Apache Kafka для инженеров данных
- Администрирование Arenadata Streaming Kafka
[elementor-template id=»13619″]

