 1355
1355 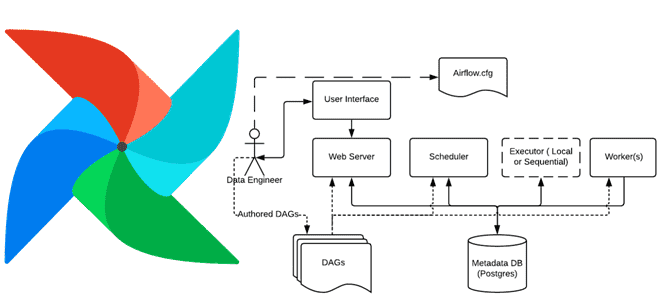
Содержание
Сегодня рассмотрим, как в Apache AirFlow реализуется обмен данными между задачами с использованием технологии XCom. Чем хорош XCom и почему его не стоит использовать для передачи больших объемов данных: практика организации ETL-конвейеров для дата-инженера.
Что такое XCom и зачем это в Apache AirFlow
Apache AirFlow не зря является одним из самых востребованных инструментов современной инженерии данных. Этот надежный фреймворк позволяет управлять пакетными конвейерами обработки больших данных, помогая создавать, планировать и контролировать ETL-процессы с помощью удобного API. Рассмотрим пример обновления переменной в базе данных, чтобы использовать ее в следующих задачах одного и того же workflow-процесса. Предположим, первая задача этого сценария в AirFlow — это перечислить имена файлов по заданному пути, а вторая – загрузить перечисленные файлы. Чтобы реализовать этот сценарий в AirFlow, есть два следующих способа:
- использовать внешний инструмент, такой как базы данных, для передачи данных из первой задачи и их извлечения из базы данных во второй задаче. Здесь нужно настроить подключение к внешнему инструменту и гарантировать его доступность для обмена данными между задачами.
- обойтись без внешнего инструмента, обмениваясь данными между двумя задачами в AirFlow посредством технологии XCOM (Cross Communication). XCOM позволяет обмениваться небольшим количеством данных между задачами в AirFlow, храня эти промежуточные данные в метаданных фреймворка.
XCom – это механизм, который позволяет задачам взаимодействовать друг с другом, которые изначально полностью изолированы и могут выполняться на совершенно разных машинах. в Airflow 2.0 операция XCom скрыта внутри Python-оператора и полностью абстрагируется от разработчика DAG. Кроме того, идея XCom-технологии легла в основу API TaskFlow – механизма, впервые выпущенного во 2-ой версии фреймворка, чтобы упростить нескольких создание DAG, абстрагируя уровень управления задачами и зависимостями от пользователей. Подробно об этом мы писали здесь и здесь.
XCom-объекты идентифицируется по ключу (фактически по имени), а также по идентификатору задачи (task_id) и DAG-графа (dag_id), из которых он был получен. XCom-объекты могут иметь любое (сериализуемое) значение, но предназначены только для небольших объемов данных. XCom явно проталкиваются в хранилище и извлекаются из него с помощью методов xcom_push() и xcom_pull() в экземплярах задач. Многие операторы автоматически отправляют свои результаты в ключ XCom с именем return_value, если для аргумента do_xcom_push установлено значение True (по умолчанию), и функции @task также делают это.
Метод xcom_pull() по умолчанию использует этот ключ. Если ключ не передан методу, можно написать такой код:
# Pulls the return_value XCOM from "pushing_task" value = task_instance.xcom_pull(task_ids='pushing_task')
Также можно использовать XComs в шаблонах:
SELECT * FROM {{ task_instance.xcom_pull(task_ids='foo', key='table_name') }}
В отличие от переменных, XCom предназначены для экземпляра задачи и связи в рамках запуска DAG, тогда как в то время как переменные являются глобальными и предназначены для общей конфигурации и совместного использования значений. Подробнее об отличии XCom-объектов и переменных мы писали здесь.
Если первый запуск задачи не увенчался успехом, то при каждой повторной попытке задачи XCom будут очищаться, чтобы задача выполнялась идемпотентно, т.е. результаты ее повторного выполнения были такими же, как при первичном запуске.
Под капотом технологии: особенности и ограничения
Система XCom имеет взаимозаменяемые серверные части, и дата-инженер может указать, какую из них использовать с помощью параметра конфигурации xcom_backend. Если нужно реализовать собственный бэкэнд, следует создать подкласс BaseXCom и переопределить методы serialize_value() и deserialize_value().
Есть также метод orm_deserialize_value(), который вызывается всякий раз, когда объекты XCom визуализируются для пользовательского интерфейса или отчетов. В случае больших или дорогостоящих для извлечения значений в XCom-объектах, надо переопределить этот метод, чтобы избежать его вызова. При этом рекомендуется возвращать более легковесное, но неполное представление, чтобы сохранить отзывчивость пользовательского интерфейса.
Можно также переопределить метод очистки и использовать его при очистке результатов для заданных DAG’ов и задач. Это позволяет пользовательскому бэкенду XCom упростить обработку жизненного цикла данных.
В зависимости от того, где развернут AirFlow (локально, Docker, Kubernetes и т.д.), полезно убедиться, что пользовательский бэкэнд XCom действительно инициализируется. Например, сложность среды контейнера может затруднить определение того, правильно ли загружается серверная часть во время развертывания контейнера. Для этого, прежде всего следует запустить терминал в контейнере,
from airflow.models.xcom import XCom print(XCom.__name__)
который выведет фактически используемый класс.
Также можно изучить конфигурацию Airflow:
from airflow.settings import conf
conf.get("core", "xcom_backend")
Запуск пользовательских бэкендов XCom в Kubernetes сделает развертывание Airflow еще более сложным. Например, при определении пользовательского бэкэнда XCom в Helm-диаграмме values.yaml через конфигурацию xcom_backend, AirFlow может столкнуться с невозможностью загрузки класса. В итоге все развертывание Helm-диаграммы завершится ошибкой, и каждый контейнер пода будет пытаться перезапуститься снова и снова. Поэтому при развертывании в Kubernetes пользовательский бэкэнд XCom должен находиться в каталоге конфигурации, иначе его нельзя будет найти во время развертывания Chart.
Причина этой проблемы в том, что очень сложно получить журналы из контейнера, поскольку существует очень небольшое окно доступности, в течение которого можно получить трассировку. Единственный способ определить основную причину — запросить и получить журналы контейнера в нужное время, что не всегда удается на практике и препятствует успешному развертыванию всей диаграммы Helm.
После отправки данных в метаданные AirFlow необходимо получить те же данные, используя метод экземпляра задачи xcom_pull(). Аналогично xcom_push(), он требует два входных параметра:
- идентификатор задачи (task_id), чтобы извлечь из XCom только нужные задачи;
- ключ, чтобы возвратить XCom-объекты с соответствующим ключом.
Можно указать несколько идентификаторов задач, чтобы одновременно извлекать XCom из нескольких задач.
В заключение еще раз отметим ограничения XCom: поскольку AirFlow не является платформой обработки данных, не следует передавать между задачами большие датафреймы, т.к. это чревато проблемами с памятью. Предельный размер XCom в Apache AirFlow зависит от базы данных, которая используется для хранения метаданных. В частности, для встроенной SQLite лимит равен 2 ГБ, для PostgreSQL 1 ГБ и 64 КБ для MySQL.
Про лучшие практики работы с XCom-объектами читайте в нашей новой статье.
Больше полезных приемов администрирования и эксплуатации Apache AirFlow для дата-инженерии и аналитики больших данных вы узнаете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники

