Продолжая разбирать, как работает аналитика больших данных на практических примерах, сегодня мы рассмотрим, что такое Graceful shutdown в Apache Spark Streaming. Читайте далее, как устроен этот механизм «плавного» завершения Спарк-заданий и чем он полезен при потоковой обработке больших данных в рамках непрерывных конвейеров на базе Apache Kafka и других технологий Big Data.
Зачем нужно «плавное» завершение Spark-заданий при потоковой обработке данных
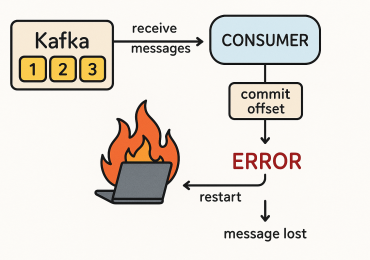
Как мы разбирали во вчерашнем примере, при построении конвейера потоковой обработки больших данных на основе Apache Kafka и Spark Streaming предполагается, что Spark-задания выполняются непрерывно. Приложение Spark Streaming постоянно считывает события из входного топика Kafka, обрабатывает их и записывает результаты в выходной топик. Но на практике в кластере Спарк может возникнуть сбой. А, поскольку, Apache Spark – это отказоустойчивая технология Big Data, незавершенное задание будет перезапущено автоматически. При этом возникнет потеря части данных, которые должны быть обработаны, т.к. за время перезапуска Spark-задания, продолжается запись событий в топик Apache Kafka. Наиболее изящный и простой способ решения этой проблемы получил название механизм «плавного» отключения (Graceful shutdown).
Примечательно, что это «безопасное» решение, которое работает в любом масштабе и не зависит от конкретной версии фреймворка Спарк или операционной системы. Дополнительным плюсом этого механизма является то возможность его использования при намеренной остановке потоковой обработки данных, например, при развертывании новой версии [1]. Как это работает, мы рассмотрим далее.
Потоковая обработка в Apache Spark
Код курса
SPOT
Ближайшая дата курса
25 августа, 2025
Продолжительность
16 ак.часов
Стоимость обучения
48 000
Как работает Graceful Shutdown в Apache Spark Streaming
Чтобы включить Graceful Shutdown, необходимо создать контекст Spark с параметрами spark.streaming.stopGracefullyOnShutdown = true. Это указывает Spark на необходимость корректно завершить работу StreamingContext при завершении работы JVM, а не просто немедленно «отключиться». Рассмотрим пример использования этого механизма при проверке наличия файла в распределенной файловой системе Apache Hadoop (HDFS). Когда файл появится в HDFS, контекст потоковой передачи остановится со следующими параметрами: ssc.stop (stopSparkContext = true, stopGracefully = true). Важно, что в этом случае Spark-приложение завершается «плавно», т.е. корректно останавливается только после завершения обработки всех полученных данных [1].
Таким образом, использовать плавное завершение работы в приложениях Спарк довольно просто: следует только установить логический флаг, переданный методу org.apache.spark.streaming.StreamingContext # stop (stopSparkContext: Boolean, stopGracefully: Boolean). Его также можно активировать с помощью свойства конфигурации spark.streaming.stopGracefullyOnShutdown. Graceful Shutdown гарантирует (при соблюдении определенных условий), что все полученные данные будут обработаны до уничтожения контекста Spark. При этом вся логика завершения работы обрабатывается JobScheduler, который останавливает обработку, выполняя следующие действия [2]:
- прекращение приема данных, ожидая, что все отправленные данные будут физически получены получателями;
- остановка распределения исполнителей (если включено динамическое распределение, dynamic allocation);
- остановка генерация новых заданий (job generation) с возможностью создавать задания для текущего временного интервала. Это означает, что все полученные блоки данных должны быть распределены и обработаны за этот период. Но Graceful Shutdown не гарантирует выполнение всех запланированных заданий, а фактически ограничивает их таймаутом. Поэтому постепенное завершение генерации задания должно завершиться до времени, указанного в streaming.gracefulStopTimeout. По умолчанию этот параметр равен 10-кратному интервалу между пакетами. По истечении этого времени создание задания прекращается, даже если его некоторые шаги не были до конца завершены.
- остановка выполнения текущих заданий дает некоторое время (1 час) для физического выполнения уже запланированных заданий;
- остановка подписчиков (listeners) на события задания.
Таким образом, Graceful Shutdown нельзя назвать полной и абсолютной гарантией выполнения всех запланированных Spark-заданий, однако, этот механизм может повысить надежность приложения, реализуя выполнение ожидающих задач. Это снижает потери данных, которые могут быть вызваны немедленной остановкой Спарк-контекста. Плавное завершение работы корректно обрабатывает оставшиеся данные, но оно возможно не во всех случаях. Например, Graceful Shutdown сложнее использовать в заданиях Spark, управляемых YARN [2].
Core Spark - основы для разработчиков
Код курса
CORS
Ближайшая дата курса
22 сентября, 2025
Продолжительность
16 ак.часов
Стоимость обучения
48 000
Смещения топиков Kafka и корректная обработка RDD
Возвращаясь к рассматриваемому примеру потоковой обработки данных в конвейере на базе Apache Kafka, Spark Streaming и Druid в системе онлайн-аналитики рекламной биржи Outbrain, отметим, что этот механизм обеспечивает стабильный поток данных без потери событий или их дублирования во время перезапуска заданий Spark. В дополнение инженеры Big Data компании Outbrain фиксируют смещения топиков Kafka при каждой обработке RDD с помощью Kafka commitAsync API. При этом было учтено, что метод Kafka commitAsync()помещает смещение offsetRanges в очередь, которая фактически обрабатывается только в следующем цикле foreachRDD. Поэтому, даже если задание Spark будет корректно остановлено и завершит обработку всех своих RDD, смещения последнего RDD фактически не будут зафиксированы. Для решения этой проблемы был написан код, который сохраняет смещения Kafka синхронно, не полагаясь на метод commitAsync(). Затем зафиксированные смещения для каждого RDD сохранялись в файле HDFS. Когда Спарк-задание снова запускается, оно загружает файл смещений из HDFS и с учетом этого offset’а далее обрабатывает события топика Kafka.
Apache Kafka для инженеров данных
Код курса
DEVKI
Ближайшая дата курса
8 сентября, 2025
Продолжительность
24 ак.часов
Стоимость обучения
72 000
Таким образом, Graceful Shutdown в сочетании с синхронным хранением смещений Kafka позволила дата-инженерам рекламной биржи Outbrain получить желаемый результат без потерь и дублирования данных при перезапусках Spark-заданий [1]. О том, как подобная функция плавного завершения реализована для узлов Kubernetes в новом релизе 3.1.1, читайте здесь. А про плавное завершение потоковых заданий в приложениях-продюсерах Kafka мы рассказываем в этой статье.
Узнайте больше об администрировании, разработке и эксплуатации Apache Spark с Kafka для потоковой аналитики больших данных в проектах цифровизации своего бизнеса, а также государственных и муниципальных предприятий, на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Основы Apache Spark для разработчиков
- Потоковая обработка в Apache Spark
- Анализ данных с Apache Spark
- Apache Kafka для разработчиков
- Администрирование кластера Kafka
Источники