 1050
1050 
Содержание
Недавно мы рассказывали про систему онлайн-аналитики Big Data на базе Apache Kafka, Spark Streaming и Druid для площадки рекламных ссылок Outbrain, а затем на этом же кейсе рассматривали, зачем нужен Graceful shutdown в потоковой обработке больших данных. Сегодня в рамках этого примера разберем, как снизить нагрузку при потоковой передаче множества данных с помощью семплирования RDD в Spark Streaming, а также когда и почему стоит выбрать Union, а не Join-оператор в SQL-запросах Apache Druid.
Постановка задачи или что не так с JOIN в Apache Druid
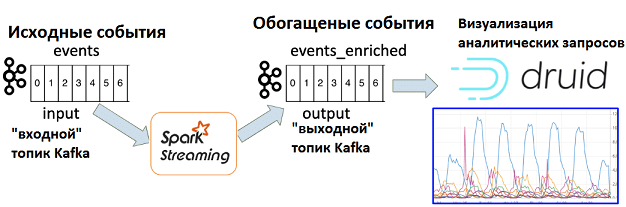
Для оценки эффективности своих ретаргетинговых кампаний, биржа рекламных ссылок Outbrain построила собственную систему аналитики больших данных на основе Apache Kafka, Spark Streaming и Druid. Принцип ее работы можно описать следующим образом [1]:
- «cырые» данные о пользовательском поведении в виде потока исходных событий попадают во входной топик Apache Kafka;
- приложение Spark Streaming добавляет к этим исходным данным дополнительную информацию, обогащая их сведениями из других источников;
- обогащенные события записываются в выходной топик Kafka;
- аналитика и визуализация результатов в реальном времени выполняется в Apache Druid.
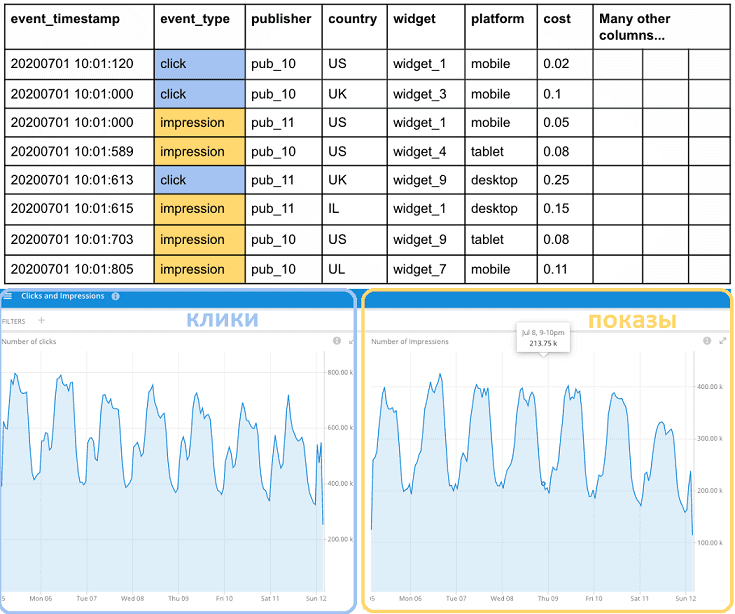
Такое решение позволило Data Analyst’ам получить широкий спектр аналитических данных в реальном времени, но было недостаточным в ряде некоторых случаев. В частности, поскольку каждый тип событий представлен в отдельном потоке, из-за специфических ограничений Druid было невозможно автоматически рассчитать показатели, основанные на нескольких потоках одновременно. Например, это нужно для определения CTR (Click Through Rate) – одного из важнейших показателей интернет-рекламы, равного отношению количества кликов за временной интервал к количеству показов. В обычной реляционной СУБД такое реализуется с помощью операции JOIN через один SQL-запрос, который выбирает и объединяет данные из двух или более таблиц [2].
Но осенью 2020 года поддержка JOIN в Apache Druid еще не совсем полноценная, к примеру, не поддерживается передача предикатов (условия и фильтра) после соединения. Это и другие дополнения ожидаются в следующих версиях данной аналитической СУБД [3]. Поэтому дата-инженеры компании Outbrain стали искать другой способ расчета показателей на основе различных типов событий, без использования JOIN. Для этого было решено применить оператор UNION. Но для этого сначала нужно было пометить разные типы событий, чтобы различать их во время запроса.
Таким образом, в один топик Kafka, а затем в Druid передавалось сразу несколько разных типов событий, каждое из которых обрабатывалось соответствующим заданием (job) потоковой передачи Apache Spark. Spark Streaming job считывает данные уровня событий из исходного топика Kafka, обогащает ее дополнительными полями и записывает в выходной топик. Согласно заранее определенной бизнес-логике, задание Spark Streaming добавляет поле «event_type» к каждому событию в дополнение к другим полям. Например, задание, которое обрабатывает клики, может проверять его статус и устанавливать для параметра is_valid_click значение 0 или 1. Это позволяет эффективно обрабатывать эти поля в Druid через типовой механизм SQL-запросов.
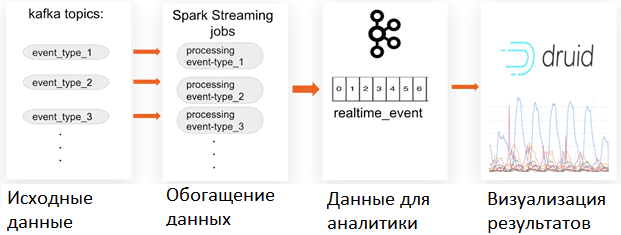
Практическое применение такой системы аналитики больших данных в реальном времени с помощью Apache Kafka, Spark Streaming и Druid требовало достаточно много ресурсов. Чтобы снизить нагрузку, было решено использовать принцип семплирования [2], когда для моделирования задействован не весь объем данных, а их только часть выборки (sample). Этот метод матстатистики считается эффективным приемом для логичного смыслового увязывания статистических свойств выборки и цели моделирования [4].
Для семплирования данных, чтобы выбрать события из топика Kafka, дата-инженеры Outbrain использовали API RDD.sample, задавая частоту дискретизации (Sample Rate) для каждого задания Spark Spark Streaming: rdd.sample(false, sampleRate, seed). Для разных заданий частота дискретизации может отличаться. Например, количество показов намного больше, чем количество кликов, поэтому можно выбрать 100% кликов, но только 1% процентов показов. Этот прием существенно снижает нагрузку на Spark, Kafka и Druid. Однако, таким образом в аналитической СУБД Druid окажется только часть всех событий, что не может гарантировать полноту всех данных и корректность результатов. Для решения этой проблемы инженеры Big Data предприняли ряд интересных модификаций, которые рассмотрены далее [2].
Прикладной feature engineering в потоковой аналитике Big Data для Apache Spark Streaming
Итак, при обработке 1% событий показов с помощью задания Spark Streaming в Druid попадает всего 1% данных. Тип записи «показ» (impression) маркирован полем is_impression = 1. Без семплирования для получения количества показов в Druid достаточно следующего запроса: SELECT SUM(is_impression) from realtime_event. Выполняя этот запрос на выборочных данных, результат следует умножить на 100. А если частота дискретизации будет не 1%, а 10%, то – на 10. Такой ручной подход применим в случае нескольких запросов, но не масштабируется для целой системы из множества заданий Spark Streaming, каждое из которых имеет свою частоту дискретизации. Кроме того, семплирование должно быть прозрачным и понятным для нескольких пользователей из разных команд. Чтобы обеспечить эти требования, к каждому событию было добавлено поле «sampleFactor», рассчитываемый по следующей формуле: sampleFactor = 1 / sampleRate. К примеру, для частоты дискретизации 1% sampleFactor равен 100, это означает, что результаты аналитики в Apache Druid будут умножены на 100.
При развертывании такой системы в производственной среде (production) нужно было учесть, что трафик должен быть полностью дискретизирован для отдельных сценариев, таких как конкретные веб-мастера. Это было реализовано с помощью потоковых заданий Spark. Сперва определялось, принадлежит ли событие, которое попадает в выборку, конкретному издателю. Если да, то rdd.sample() не применялся для этого события, но к нему добавлялся маркер sampleFactor = 1. Такой подход обеспечивал корректность итоговых результатов в Druid.
Интересно, что дата инженеры Outbrain предпочли разработать собственный механизм сэмплирования данных, а не использовать встроенную в Druid функцию накопления пакетов (rollup). Причина такого решения в том, что источник данных realtime_event представляет собой объединение нескольких типов событий и содержит объединение различных измерений, число которых весьма велико (>100) и может расти в дальнейшем. Использование типовой функции Druid для такого количества неэффективно, поскольку эта аналитическая СУБД добавляет внутренние счетчики и суммы для источников данных объединения, повышая накладные расходы на вычисления. SQL-оператор UNION позволяет обойти эту проблему, облегчая агрегацию различных измерений, которые традиционно рассчитывались через JOIN-соединение таблиц. Таким образом, семплирование и оригинальный подход к SQL-операциям в рассмотренной системе аналитики больших данных на базе Apache Kafka, Spark Streaming и Druid решили проблемы масштабирования и эффективного использования ресурсов. Также это обеспечило прозрачность и управляемость датасетов в соответствии с принципами DataOps [2]. Другой кейс совместного использования Apache Kafka с Druid для аналитики больших данных мы рассмотрим завтра на примере компании Netflix. А разговор про Apache Spark продолжим здесь, разобрав библиотеку Cleanframes для очистки данных.
Еще больше практических примеров по администрированию, разработке и эксплуатацию Apache Spark с Kafka для потоковой аналитики больших данных в проектах цифровизации своего бизнеса, а также государственных и муниципальных предприятий, вы узнаете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники
- https://medium.com/outbrain-engineering/understanding-spark-streaming-with-kafka-and-druid-25b69e28dcb7
- https://towardsdatascience.com/one-event-to-rule-them-all-e9adf04667a3
- https://druid.apache.org/docs/latest/querying/datasource/
- https://ru.wikipedia.org/wiki/Семплирование_(математическая_статистика)

