 697
697 
Содержание
Сегодня мы продолжим разговор о событийно-процессной архитектуре Big Data систем на примере использования Apache Kafka в The New York Times. Читайте далее, как одно из самых известных американских СМИ с более чем 160-летней историей хранит в Apache Kafka все свои статьи и с помощью API Kafka Streams публикует контент в режиме реального времени в различные приложения, делая его мгновенно доступным для читателей.
Постановка задачи: технический взгляд и позиция бизнеса
Основной причиной создания новой системы публикации контента в The New York Times стала необходимость оперативного предоставления множеству внутренних и внешних приложений доступа к опубликованному контенту. При этом стоило учесть разные требования каждого из компонентов этой многосвязной системы [1]:
- сервису, который предоставляет содержимое для веб-сайта и собственных приложений необходимо делать ресурсы доступными сразу после их публикации, причем всегда нужна только последняя версия каждого ресурса.
- Разные сервисы предоставляют списки контента, часть из которых составляются вручную, а некоторые — на основе запросов. Вторые нужно автоматически обновлять при публикации контента, который соответствует запросу. А если опубликовано обновление, из-за которого материал не отвечает этому требованию, его следует удалить из списка. Также требуется поддерживать изменения в самом запросе и создание новых списков, что предполагает доступ к ранее опубликованному контенту для повторного создания списков.
- Для поиска по сайту используется кластер Elasticsearch, которому необходимо обеспечить легкий доступ к ранее опубликованному контенту, т.к. требуется переиндексировать все при изменении схемы или конвейера приема результатов поиска.
- Поскольку каждому из читателей предлагается персонализированный контент, его необходимо обрабатывать повторно при изменении алгоритмов персонализации.
Почему Apache Kafka или проблемы API-based архитектуры
До перехода на Apache Kafka архитектура системы предоставления всем потребителям доступа к опубликованному контенту базировалась на API (API-based). Производители контента предоставляли API для доступа к нему, а также каналы, на которые можно подписаться для получения уведомлений о новых публикациях. Сервисы-потребители контента вызывали эти API, чтобы получить необходимые данные. Однако, эта типовая API-архитектура провоцировала целый ряд проблем:
- поскольку разные API-интерфейсы разрабатывались в разное время разными командами, они работали совершенно по-разному – у них отличались фактически предоставляемые конечные точки, семантика и принимаемые параметры. Это усложняет работу с сервисами и требует усиленной координации между командами.
- Каждая система имеет свою собственную, иногда неявно определенную схему. В частности, имена полей в одной CMS отличаются от таких же полей в другой CMS, а одно и то же имя поля могло означать абсолютно разные вещи в разных системах. Поэтому каждая система, которой нужен доступ к контенту, должна знать все эти различные API-интерфейсы и их особенности, и выполнять нормализацию между различными схемами данных.
- Наконец, в рамках этой архитектуры не так-то просто получить доступ к ранее опубликованному контенту. Большинство систем не позволяли эффективно передавать архивы контента в потоковом режиме, а из СУБД не поддерживали его. Поэтому, даже при наличии списка всех публикаций, выполнение отдельного API-вызова для извлечения каждого отдельного материала занимает очень много времени и создает непредсказуемую нагрузку.
Для решения этих проблем Big Data специалисты в The New York Times приняли решение перейти от API-архитектуры к событийно-процессной или журнальной (log-based) на базе Apache Kafka, о которой мы расскажем далее.
Что такое log-based архитектура и чем она хороша
Идея журнальной архитектуры была впервые подробно описана исследователем кембриджского университета Мартином Клеппманном в статье «Turning the database inside-out with Apache Samza» (2015 год) [2] и позже раскрыта в его же книге «Designing Data-Intensive Applications» (2017 год) [3]. При этом журнал или лог выступает в качестве общей структуры данных. В случае Apache Kafka все опубликованное содержимое добавляется к топику в хронологическом порядке и сторонние сервисы получают к нему доступ, используя журнал. Таким образом, log-based архитектуры на основе журналов решают проблему единого источника истины, делая им журнал. Тогда как СУБД обычно хранит результат некоторого события, в журнале хранится оно само, поэтому лог становится упорядоченным представлением всех событий, произошедших в системе. Используя лог, можно создать любое количество пользовательских хранилищ данных, которые станут материализованными представлениями журнала, т.к. они содержат производное, а не исходное содержимое. Если нужно изменить схему в таком хранилище данных, можно просто создать новую и начать журнал заново.
Поскольку журнал является источником истины, отпадает необходимость в единой базе данных, которую должны использовать все системы. Вместо этого каждая система может работать со своим собственным материализованным представлением только необходимых данных в виде СУБД в той форме, которая необходима именно этому приложения. Это значительно упрощает роль базы данных в архитектуре, делая ее более приспособленной к потребностям каждого сервиса.
Кроме того, log-based архитектура упрощает доступ к потокам контента. В традиционном хранилище данных доступ к полному дампу (моментальному снимку) и «живым» данным в виде канала реализуются по-разному. В журнальной или event-streaming архитектуре это различие пропадает: нужно всего лишь считывать лог с определенного смещения (начало, конец или любая промежуточная точка). Наконец, log-based архитектура также предоставляет множество преимуществ при развертывании систем с отслеживанием состояния, т.к. хранилище данных может быть воссоздано из журнала. Примечательно, что в отличие от Google Pub/Sub, AWS SNS/SQS и AWS Kinesis, Apache Kafka не только позволяет нескольким потребителям подписываться на сообщения, опубликованные разными несколькими производителями и отслеживать обработку без потери данных. Поскольку Kafka является журналом, то она хранит все события вечно, позволяя в любой момент восстановить историческую причинно-следственную связь системы [1].
Какие плюсы получил The New York Times от Apache Kafka
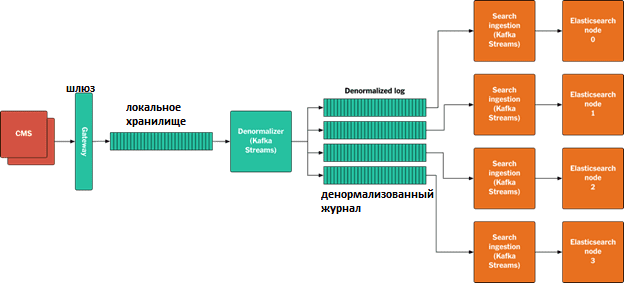
Возвращаясь к кейсу The New York Times, отметим, что, помимо log-based архитектуры, Apache Kafka также используется для создания целой системы data pipeline’ов. В частности, с помощью API Kafka Streams было разработано Java-приложение, которое поддерживает постоянно обновляемое локальное хранилище последней версии каждой публикации вместе со ссылками на нее. Когда новый материал публикуется, данное приложение собирает все зависимости из локального хранилища и записывает их в виде пакета в денормализованный журнал. Благодаря отсутствию нормализации, нет необходимости в полном упорядочивании, нужно только убедиться, что разные версии одного и того же материала поступают в корректном порядке. Таким образом, Kafka Streams позволяет использовать многораздельный журнал параллельно сразу для нескольких клиентов. Конвейер обработки данных при этом выглядит так [1]:
- публикуется новый материал или обновляется CMS;
- публикация записывается в шлюз как двоичный файл protobuf;
- Шлюз проверяет актив и записывает его в локальное хранилище;
- Приложение Kafka Streams потребляет публикацию актив из локального хранилища, собирая зависимости и записывая их вместе в денормализованный журнал.
- Разделитель Kafka назначает ресурсы разделам на основе URI ресурса верхнего уровня.
- Все узлы приема поиска запускают приложение, которое использует потоки Kafka для доступа к денормализованному журналу. Каждый узел считывает раздел, создает объекты JSON, которые будут проиндексированы в Elasticsearch, и записывает их в определенные узлы этой поисковой системы. Для ускорения индексации репликацию Elasticsearch можно отключить, включив ее потом снова до запуска нового индекса.
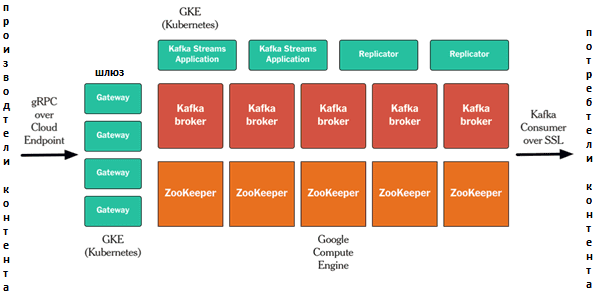
- конвейер реализован на Google Cloud Platform, где запущены Apache Kafka и ZooKeeper. Все остальные процессы (шлюз, репликаторы Kafka, приложение Kafka Streams API и пр.) выполняются в контейнерах Kubernetes. Для обеспечения безопасности Kafka используется взаимная аутентификация, авторизация SSL и удаленный вызов процедур gRPC/Cloud Endpoint для API.
При том, что данная архитектура еще только вводится в production, сотрудники The New York Times отметили для себя целый ряд преимуществ [1]:
- весь контент проходит через один и тот же конвейер, упрощая процессы разработки программного обеспечения как для интерфейсных приложений, так и для серверных систем;
- развертывания стали проще, в частности, можно делать полные повторы в новые индексы Elasticsearch при внесении изменений в анализаторы или схему, вместо того, чтобы делать это на месте для текущего индекса.
- Ведется непрерывный мониторинг того, как опубликованные ресурсы проходят через стек – каждой публикации, прошедшей через шлюз, назначается уникальный идентификатор, который возвращается издателю, а также передается Kafka и приложениям-потребителям. Это позволяет отслеживать и контролировать, где и когда каждое отдельное обновление обрабатывается, вплоть до приложений конечных пользователей.
Как эффективно администрировать и использовать Apache Kafka для потоковой обработки и хранения больших данных в проектах цифровизации своего бизнеса, а также государственных и муниципальных предприятий, вы узнаете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники

