 1171
1171 
Содержание
Сегодня поговорим про обучение Apache Kafka и рассмотрим сценарии применения HTTP и RESTful протоколов в этой Big Data платформе потоковой обработки событий. Читайте далее, чем парадигма request-response отличается от event streaming processing, как связаны REST и HTTP, каковые преимущества RESTful API и где это используется на практике для обработки и аналитики больших данных.
Что такое REST и при чем здесь HTTP
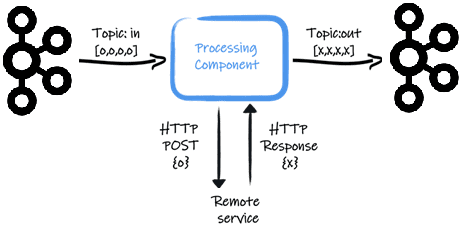
Начнем с практического примера: предположим, нужно вызвать удаленный сервис для каждого полученного сообщения из Apache Kafka. В одном из топиков хранятся данные для потребления (Topic:in), к примеру, транзакции, которые считывает компонент обработки (Processing Component). Для каждой считанной транзакции processing component вызывает удаленный сервис, например, для ее проверки на мошенничество. Полученный результат компонент обработки записывает в другой топик Kafka (Topic:out). Для такого случая можно использовать удаленную HTTP-службу, но также подходит и REST-клиент, который обеспечивает отличный способ взаимодействия с HTTP-службами без необходимости обрабатывать низкоуровневые детали протоколов передачи данных [1].
Напомним, в основе HTTP-протокола лежит парадигма «запрос-ответ» (request-response), для которой характерны следующие признаки [2]:
- низкая временная задержка
- синхронность (в большинстве случаев);
- прямое соединение (точка-точка, point to point)
- предопределенный API.
Потоковой обработке событий (event streaming processing), на которую ориентирована Apache Kafka, присущи совсем другие особенности:
- непрерывная обработка;
- асинхронность (в большинстве случаев);
- фокус на событиях;
- универсальный подход к обработке событий.
На практике чаще всего требуется совмещение обоих парадигм. В частности, запрос-ответ для точечной связи, например, между сервером и мобильным приложением, и потоковая передача событий для непрерывной обработки данных.
Таким образом, потоковая обработка может быть реализована с помощью REST (Representational State Transfer, передача состояния представления), архитектурного стиля взаимодействия компонентов распределённого приложения в сети. Напомним, REST – это согласованный набор ограничений при проектировании распределённой системы, чтобы повысить ее производительность и упростить архитектуру. REST считается альтернативой удаленного вызова процедур (RPC, Remote Procedure Call), но не является стандартом или протоколом. Если веб-сервис разработан с учетом архитектурного стиля REST, т.е. не нарушает его ограничений, его называют RESTful. В качестве формата данных большинство RESTful-реализаций используют JSON, реже XML, но также могут работать с любым форматом (TXT, CSV и пр.). В качестве протокола транспорта данных RESTful-реализации активно используют HTTP [3].
Чем хорош RESTful API в Apache Kafka: 7 популярных use-case’ов
Возвращаясь к Apache Kafka, отметим, что при выборе HTTP или REST API нужно учитывать следующие аспекты в архитектуре системы [2]:
- управление и администрирование кластера Kafka, в т.ч. его конфигурирование (управление топиками, группами потребителей, списками контроля доступа и пр). В плане интеграция CI/CD и DevOps наиболее популярным способом создания конвейеров и автоматизации процессов является HTTP API. Это удобнее Python-скриптов и прочих альтернатив. О Python-клиентах для работы с Apache Kafka мы рассказывали здесь.
- данные – обычно разработчики распределенных Big Data приложений предпочитают REST API для отправки сообщений в топики Kafka и потребления их оттуда.
- распространенность практического использования – многие разработчики и администраторы знакомы и успешно работают с REST API, который предоставляет различные передовые практики и рекомендаций обеспечения информационной безопасности.
Таким образом, можно выделить следующие сценарии использования REST API для Apache Kafka в задачах обработки и интеграции больших объемов данных [2]:
- мобильные приложения, которые часто требуют интеграции через HTTP и запрос-ответ. WebSockets, Server-Sent Events (SSE) и аналогичные концепции лучше подходят для потоковой передачи событий с помощью Kafka. Они находятся в клиентском фреймворке, хотя часто не поддерживаются.
- интеграция проприетарных систем (legacy) со сторонними приложениями. При этом ETL-процессы (извлечение, преобразование и загрузка) и работа с сервисной шиной предприятия (ESB, Enterprise Service Bus) могут быть отлично реализованы с помощью потоковой передачи событий на базе Kafka. Примеры таких систем мы описывали здесь и здесь.
- шлюз API, если инструменты управления API не обеспечивают встроенной поддержки потоковой передачи событий с Kafka и работают только поверх REST-интерфейсов. Взаимодействие с Kafka через REST-интерфейс и управление API хорошо дополняют друг друга и подходят для таких сценариев, как монетизация услуг или интеграция с партнерскими системами.
- разные языки программирования, которые могут не поддерживаться Kafka. В этом случае пригодится REST API. Например, COBOL, на мэйнфреймах, до сих пор часто распространенный во многих государственных предприятиях и банках с длительной историей существованиях, не предоставляет клиента Kafka. Поэтому REST Proxy будет подходящим и жизнеспособным решением для работы такой системы с потоками Big Data.
Дополнительными преимуществами практического использования REST API в Apache Kafka можно назвать следующие [2]:
- независимость от технологии;
- распространенность стиля REST;
- безопасность и простота: открывать порты HTTP проще, чем TCP собственного протокола Kafka, используемого клиентами Java, Go, C ++ или Python.
Завтра мы продолжим разговор о REST API в Apache Kafka и рассмотрим его реализацию от Confluent. О том, как записать содержимое REST API или HTTP-ответа в топик Кафка с использованием утилиты cURL, читайте здесь. А научиться администрированию кластера и разработке приложений Kafka для потоковой аналитики больших данных вы сможете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
[elementor-template id=»13619″]
Источники

