 813
813 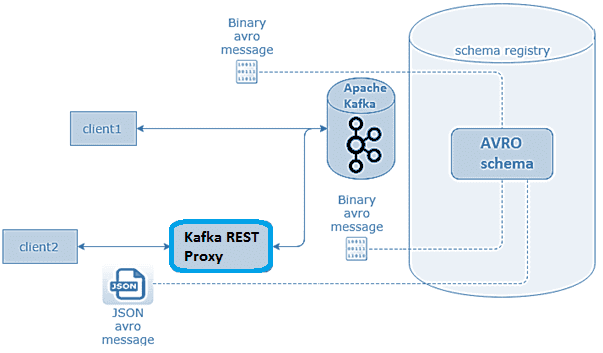
Содержание
В этой статье разберем, что такое Confluent REST Proxy для Apache Kafka, как работает этот RESTful API, каким образом он связан с облачным сервисом этой популярной Big Data платформой потоковой обработки событий, а также при чем здесь Schema Registry.
Основы Confluent REST Proxy для Apache Kafka
Широко известная в области Big Data компания Confluent, разработчик коммерческих инструментов, упрощающих работу с open-source системой Apache Kafka, представила свой прокси-сервер с RESTful-интерфейсом для этой стриминговой платформы. Что такое RESTful к Apache Kafka и как это связано с HTTP, мы рассматривали вчера. Confluent REST Proxy упрощает генерацию и потреблением сообщений, мониторинг состояния кластера и его администрирование без использования собственного протокола Kafka или специальных клиентов. На практике это очень полезно в следующих случаях [1]:
- отправка данных в Kafka из внешнего приложения на любом языке, не поддерживаемом официальными клиентами Confluent;
- передача сообщений во фреймворк потоковой обработки, который не поддерживает Kafka;
- создание сценариев административных действий для автоматизированного управления Kafka-кластером.
Дополнительным удобством является наличие плагина для Confluent REST Proxy, который помогает аутентифицировать входящие запросы и распространяется на аутентифицированного принципала, посылающего запросы к Kafka. Благодаря этому клиенты Confluent REST Proxy могут использовать функции мультитенантной безопасности брокера Kafka [1]. Напомним, в мультинатентной (multi-tenant) или мультиарендной архитектуре единый экземпляр приложения, запущенный на сервере, обслуживает много клиентов (арендаторов), работая одновременно с несколькими конфигурациями и наборами данных. При этом каждый клиент взаимодействует только со своим экземпляром виртуального приложения, видя лишь свою конфигурацию и свой датасет [2].
Интересно, что Confluent REST Proxy существует уже достаточно давно и доступен по лицензии Confluent Community License. Этот RESTful API к Apache Kafka используется в качестве самоуправляемого компонента для данной Big Data платформы, а также в сочетании с Confluent Platform или Confluent Cloud, о котором мы упоминали здесь на примере кейса цифровой трансформации британского ритейлера Boden. В 2020 году в Confluent REST Proxy были добавлены дополнительные архитектурные опции [3]:
- Самоуправляемый экземпляр REST Proxy или кластер экземпляров как «выделенный узел» отделен от брокера Kafka и Confluent Server, что позволяет изолировать рабочие нагрузки друг от друга;
- унифицированный REST API в Confluent Server как «плагин брокера» и в Confluent Cloud упрощают администрирование кластера, поскольку не требуются дополнительные узлы для специализированного API;
- встроенные API-интерфейсы REST в Confluent Server и в Confluent Cloud позволяют выделять несколько отдельных и независимых от сервера экземпляров REST Proxy, обеспечивая масштабируемость и гибкость всей системы, в т.ч. организацию гибридных архитектур и миграцию в облако без каких-либо критических изменений.

Интеграция Big Data с RESTful API или работа со Schema Registry
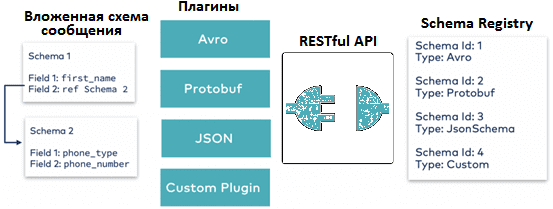
Реестр схем данных (Schema Registry) обеспечивает поддержку множества файловых форматов в Apache Kafka (AVRO, JSON, Protobuf и пр.), о чем мы подробно писали здесь. Confluent REST Proxy работает с Kafka для публикации и чтения сообщений, схемы моделей данных которых хранятся в Schema Registry. Реестр схем обеспечивает управление данными и применение схемы для всех событий, предоставляя RESTful-интерфейс для хранения и извлечения схем AVRO, JSON и Protobuf. Он хранит историю версий всех схем на основе заданной стратегии имен субъектов, предоставляет несколько параметров совместимости и обеспечивает эволюцию схем в соответствии с настроенными параметрами совместимости и расширенной поддержкой их типов. Он предоставляет сериализаторы, которые подключаются к клиентам Kafka, обрабатывающим хранение и извлечение схемы для сообщений.
При том, что применение схемы происходит на стороне клиента, Confluent Platform и Confluent Cloud обеспечивают проверку схемы на стороне сервера. Это полезно, если некорректные или вредоносные клиентские приложения отправляют сообщения в Apache Kafka без интеграции с реестром схем [3].
Confluent REST Proxy может читать и записывать данные с использованием JSON, необработанных байтов, закодированных с помощью base64, кодированных JSON Avro, Protobuf или схемы JSON. В Avro, Protobuf или JSON схемы регистрируются и проверяются в реестре схем [1].
При работе с Confluent Cloud в графическом интерфейсе следует проверить подключение к конечной точке Schema Registry, включить возможность работы с реестром схем, а также создать ключ API и секрет для подключения к нему [4]:
schema.registry.url=https://{{ SR_ENDPOINT }}
basic.auth.credentials.source=USER_INFO
schema.registry.basic.auth.user.info={{ SR_API_KEY }}:{{ SR_API_SECRET }}
Практические примеры работы с Confluent REST Proxy подробно описаны в официальной документации [4]. Завтра мы продолжим разбирать этот RESTful-интерфейс и рассмотрим его основные достоинства и недостатки. А освоить все тонкости администрирования кластера, разработки и интеграции приложений Kafka для потоковой аналитики больших данных вы сможете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники
- https://docs.confluent.io/platform/current/kafka-rest/index/
- http://www.openedge.ru/read/733/
- https://www.confluent.io/blog/http-and-rest-api-use-cases-and-architecture-with-apache-kafka/
- https://docs.confluent.io/platform/current/tutorials/examples/clients/docs/rest-proxy/

