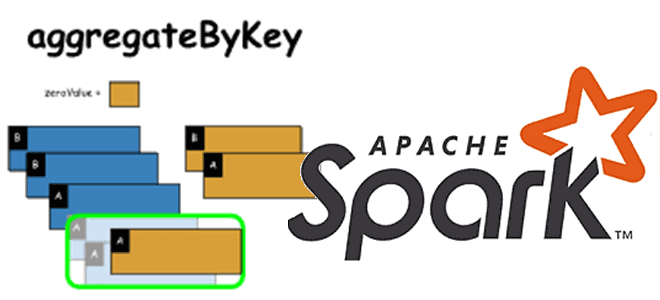
В рамках обучения дата-аналитиков и разработчиков Spark-приложений, сегодня рассмотрим одну из агрегатных функций обработки данных в этом распределенном вычислительном фреймворке. Чем aggregateByKey() отличается от reduceByKey() и groupByKey(), и когда стоит ее использовать.
Как устроена функция aggregateByKey(): назначение и синтаксис
Функция aggregateByKey() – одна из агрегатных функций, наряду с reduceByKey() и groupByKey(), доступных в Spark. Все они относятся к Shuffle-операциям, о чем мы упоминали здесь. Однако, в отличие от них, это единственная функция агрегирования, которая допускает одновременное агрегирование нескольких типов: максимальное, минимальное, среднее, сумма и подсчет количества. Перед тем как погрузиться в aggregateByKey(), напомним, что она работает со структурой данных RDD – устойчивая распределенная коллекция данных. RDD в Spark состоит из нескольких разделов, к каждому из которых применяются преобразования. Фреймворк запускает столько задач преобразования данных, сколько разделов есть в RDD. Таким образом, по умолчанию уровень параллелизма вывода зависит от количества разделов родительского RDD. С помощью необязательного аргумента numTasks можно установить другое количество задач.
Синтаксис функции имеет следующий вид: aggregateByKey(zeroValue)(seqOp, combOp, [numTasks]). При вызове для набора данных из пар ключ/значение (K, V) функция возвращает набор данных из (K, U) пар, где значения для каждого ключа агрегируются с использованием заданных функций комбинирования, а также нейтральное «нулевое» значение. Функция позволяет использовать тип агрегированного значения, отличный от типа входного, избегая при этом ненужного выделения. Как и в groupByKey(), количество Reduce-задач настраивается с помощью необязательного второго аргумента. Однако, в отличие от groupByKey(),производительность aggregateByKey() намного выше при группировке данных для выполнения агрегации, например, вычисления суммы или среднего, по каждому ключу.
Рассмотрим входные параметры aggregateByKey(zeroValue)(seqOp, combOp, [numTasks]):
- zeroValue – начальное значение, которое не влияет на собираемые агрегированные значения. Чаще всего оно равно 0. Например, 0 будет начальным значением для выполнения суммирования, подсчета количества или для выполнения операции со строкой, тогда начальное значение будет пустой строкой. Если цель агрегации – найти минимальное значение, в качестве начального может быть Double.MaxValue или Double.MinValue, если цель агрегации – найти максимальное значение. Если же в качестве вывода для каждого ключа просто нужна соответствующая коллекция, в качестве zeroValue может быть пустой список, map-карта соответствия или HashSet.
- seqOp – комбинирующая функция последовательности, которая принимает два параметра, объединяя значения в одном разделе (merge). Она преобразует данные одного типа [V] в другой тип [U].
- combOp – комбинирующая функция слияния, которая также принимает два параметра, объединённые в один в разделах RDD. Этот шаг объединяет значения по разделам, т.е. функция объединяет несколько преобразованных типов [U] в один тип [U].
Таким образом, aggregateByKey() имеет 3 основных входа, и 1 из них работает на выходе при преобразовании каждого раздела RDD. Если в RDD имеется всего один раздел, aggregateByKey() не будет работать. Входной RDD для aggregateByKey() будет парой значений ключа. Количество начальных входов в zeroValue будет зависеть от количества различных агрегаций, которые необходимо выполнить. Первый входной параметр seqOp будет того же типа, что и zeroValue, а другой параметр будет значением RDD датафрейма. Следующим набором входных данных для combOp будет то, что было обработано на предыдущем шаге. Как это работает на практике, рассмотрим далее.
Практический пример сложной агрегации по ключу в Apache Spark
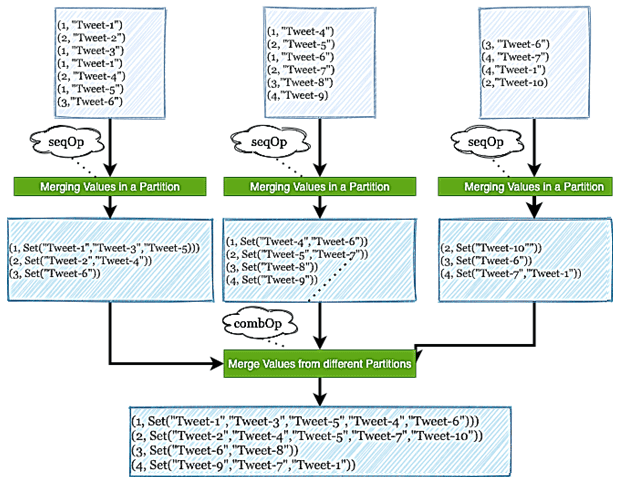
Предположим, необходимо определить среднюю длину комментария в час, которые каждый день оставляют пользователи соцсети. Из входного датасета, основанного на собранном списке комментариев, для поставленной задачи будем использовать атрибуты Text и CreationDate, где Text – это фактический комментарий пользователя, а CreationDate – отметка времени, когда каждый комментарий был зарегистрирован. Это поле будет использоваться для группировки.
Если изначально список комментариев хранился в XML-файле, необходимо сперва выполнить его синтаксический анализ (парсинг), чтобы перевести текст в RDD. Это можно сделать с помощью следующей команды на Spark Java:
JavaRDD<Map<String, String>> mapJavaRDD = stringJavaRDDdd.map(MRDPUtils::transformXmlToMap);
Далее можно работать с полученным RDD, применяя функцию aggregateByKey():
JavaPairRDD<String, String> javaPairRDD = mapJavaRDD.
mapToPair(pair -> new Tuple2<>(pair.get("CreationDate"), pair.get("Text")));
JavaPairRDD<Integer, String> pairRDD = javaPairRDD.filter(p -> p._1 != null && p._2 != null)
.mapToPair(tuple -> new Tuple2<>(LocalDateTime.parse(tuple._1, MRDPUtils.DATE_FORMAT).getHour(), tuple._2));
Tuple2<Integer, Integer> zeroValue = new Tuple2<>(0, 0);
JavaPairRDD<Integer,Tuple2<Integer,Integer>> aggregate = pairRDD.aggregateByKey(zeroValue,(acc, elem) -> {
{
Integer localCommentLength = acc._1 + elem.length();
Integer localCountOfTotalComments = acc._2 + 1;
return new Tuple2<>(localCommentLength, localCountOfTotalComments);
}
},
(partition1, partition2) -> {
{
return new Tuple2<>(partition1._1 + partition2._1, partition1._2 + partition2._2);
}
}
);
}
}
Узнайте больше про администрирование и использование Apache Spark для разработки распределенных приложений и аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Основы Apache Spark для разработчиков
- Анализ данных с Apache Spark
- Потоковая обработка в Apache Spark
- Машинное обучение в Apache Spark
- Графовые алгоритмы в Apache Spark
Источники

