 565
565 
Содержание
- Построение Data Lake в автомобилестроительной компании Renault
- Как Apache NiFi используется в MasterCard
- Шлюз данных для обеспечения кибербезопасности в ИТ-инфраструктуре страховой компании
- Big Data система оперативного взаимодействия с клиентами на основе Apache Flink и NiFi
- Логистическая холодовая цепь на блокчейне и Apache NiFi
В прошлый раз мы рассмотрели пример прототипа IIoT-системы на основе одноплатного мини-компьютера Raspberry Pi, брокере обмена сообщениями Mosquitto и платформе маршрутизации данных Apache NiFi. Сегодня мы покажем, что этот инструмент преобразования и доставки данных из множества сторонних систем может применяться не только в IoT-решениях. Читайте в нашей статье про 5 примеров практического использования Apache NiFi в реальных Big Data проектах, представленных на международном саммите DataWorks в 2018 и 2019 годах.
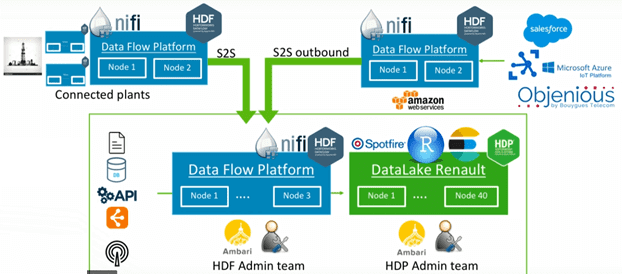
Построение Data Lake в автомобилестроительной компании Renault
В корпорации Renault Apache NiFi используется в 2-х направлениях [1]:
- Industrial Internet of Things, выполняя роль ETL-интегратора технологических данных с производственных участков, где производятся и собираются автомобильные запчасти;
- как распределенная платформа передачи информации в корпоративное озеро данных (Data Lake) и средство выгрузки из него в сторонние, в т.ч. облачные, системы и базы данных.
Во втором случае Data Engineer’ы компании Renault особенно выделяют удобство использования графического интерфейса Apache NiFi, который позволяет в наглядном виде проектировать движение информационных потоков [2]. В 2019 году эта Big Data система на базе NiFi в Renault ежедневно обслуживает 300-500 активных пользователей, 7000 запросов и более 40 промышленных источников данных [1].
Как Apache NiFi используется в MasterCard
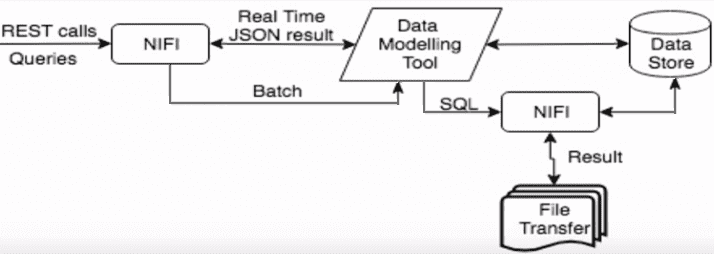
Корпорация MasterCard, обеспечивающая работу международной платежной системы, применяет эту платформу маршрутизации данных также для 2-х случаев [3]:
- как средство реализации концепции «данные как сервис» (Data as a Service), которое собирает REST-подобные запросы, отправляя их в инструмент моделирования данных как в поточном, так и в пакетном режимах. Также NiFi выполняет роль маршрутизатора больших файлов и аутентификационных потоков, взаимодействуя с внешними хранилищами данных и инструментом моделирования с помощью SQL.
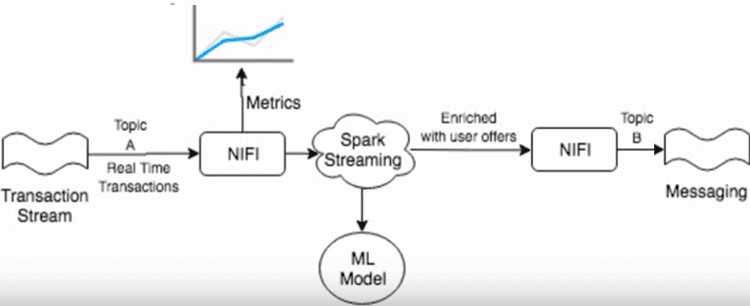
- в качестве транзакционного маршрутизатора для получения бизнес-метрик в режиме реального времени с последующей обработкой их с помощью фреймворков Apache Spark Streaming и MLLib – для построения моделей машинного обучения (Machine Learning) в рамках задач обнаружения мошеннических операций (antifraud) и предиктивной аналитики.
Шлюз данных для обеспечения кибербезопасности в ИТ-инфраструктуре страховой компании
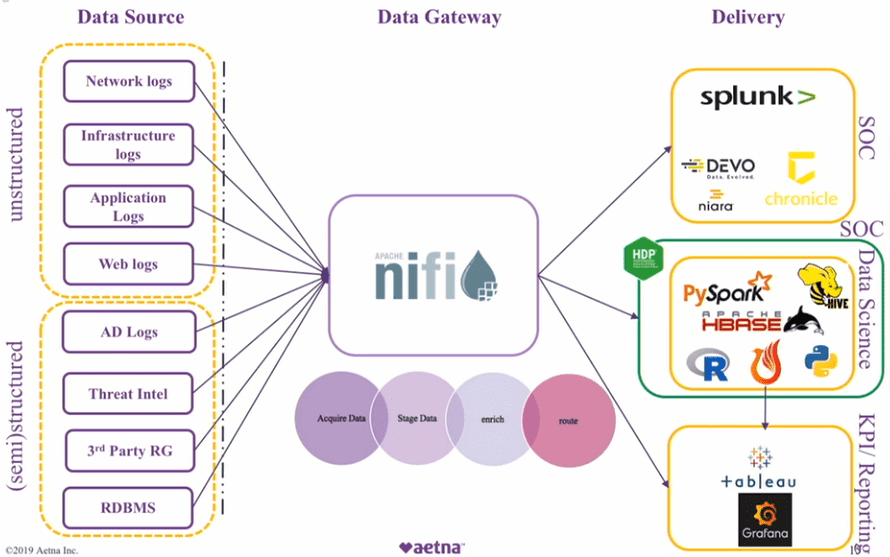
Aetna Inc., американская компания медицинского страхования, использует Apache NiFi в качестве ETL-шлюза, обеспечивающего сбор, агрегацию и первичную обработку неструктурированных и полуструктурированных данных более чем из 60 различных источников. При этом 95% информационных потоков (более 20 миллиардов событий в день) обрабатывается в реальном времени. Шлюз данных на основе Apache NiFi заменил собой ранее используемую комбинацию из фреймворков Flume, Sqoop и PySpark, позволяя корпоративным аналитикам и ученым по данным (Data Analyst) автоматически собирать всю информацию от журналов приложений и облачных сервисов, сетевых и бизнес-событий, систем аутентификации, IoT-устройств и прочих источников данных. Инструменты Machine Learning (Spark MLLib, а также собственные разработки на Scala, R и Python) помогают выявить угрозы информационной безопасности и аномалиях в использовании данных практически в реальном времени. Кроме того, Apache NiFi отправляет необходимые данные в центры кибербезопасности (SOC, Security Operation Center) и BI-систему Tableau для отображения важных бизнес-метрик (KPI) на графических дэшбордах и формирования деловых отчетов [4].
Big Data система оперативного взаимодействия с клиентами на основе Apache Flink и NiFi
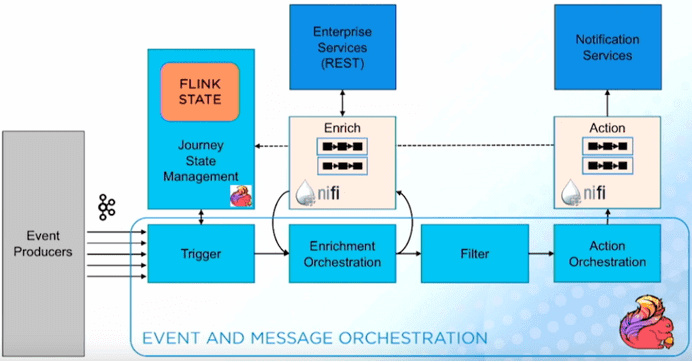
Американская телекоммуникационная корпорация Comcast разработала собственную платформу взаимодействия с клиентами, которая анализирует пользовательское поведение почти в реальном времени и оперативно реагирует на события. Это позволяет эффективно работать с потребителями в режиме онлайн, обеспечивая их потребности и предугадывая желания. Очень низкая временная задержка обработки потоковых данных (latency), характерная для Apache Flink комбинируется с возможностями NiFi для запуска, обогащения, фильтрации и реагирования на события пользовательского поведения [5]. Также в этой Big Data системе используется Apache Kafka в качестве источника данных о событиях (поведенческих тригерах), которые обрабатываются Apache Flink. NiFi подключается на этапах обогащения данных и отправки уведомлений пользователям, выполняя роль быстрого ETL-шлюза, легко интегрируемого с разными источниками и приемниками потоковых данных.
Логистическая холодовая цепь на блокчейне и Apache NiFi
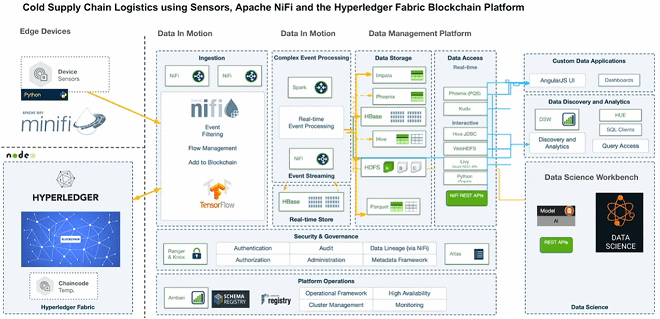
В фармацевтике и пищевой промышленности соблюдение температурного режиме – это критично важное условие сохранения и обеспечения срока годности продукции. В частности, для таких товаров, как свежие сельскохозяйственные продукты, морепродукты, замороженная рыба и мясо, фотопленка, химикаты и многие лекарственные препараты необходимо поддерживать непрерывную холодовую цепь – серию операций по производству, хранению и распределению в холодильнике и сопутствующем оборудовании, которые обеспечивают желаемый диапазон низких температур. Логистика холодовой цепи включает в себя все средства, используемые для обеспечения постоянной температуры продукта, который не является термостабильным, с момента его изготовления до момента его использования. Проверка соответствия холодовой цепи является задачей производителей и импортеров продукции, а также регулирующих органов, например, в США – это Управление по санитарному надзору за качеством пищевых продуктов и медикаментов.
Технологически представить информацию обо всех операциях холодовой сети можно с помощью блокчейн-сети, в которой сохраняются данные от каждого участника логистического процесса. Данные о температуре продукции регистрируются с помощью IIoT-датчиков, которые через MiNiFi-агенты отправляют информацию в кластер Apache NiFi. За blockhain-часть отвечает Hyperledger Fabric – программный фреймворк для разработки приложений и специализированных бизнес-решений на основе блокчейна. Apache NiFi маршрутизирует потоки данных в дальнейших процессах обработки и хранения информации с помощью соответствующих Big Data средств: Spark Streaming, HBase, HDFS, Phoenix и т.д. Конечные пользователи просматривают информацию о холодовой сети и сохраняемой в ней продукции с помощью графических дэшбордов в соответствии со своими правами доступа [6].
Читайте в нашей следующей статье про главные преимущества Apache NiFi в контексте его прикладного использования в Big Data системах и IoT/IIoT-проектах.
Все подробности по работе с Apache NiFi и другими технологиями Big Data и интернета вещей (Spark, Kafka, Hbase и т.д.) разбираются на наших практических курсах для менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков больших данных в лицензированном учебном центре обучения и повышения квалификации ИТ-специалистов в Москве:
Источники
- https://dataworkssummit.com/berlin-2018/session/apache-NiFi-best-practices-and-lessons-learnt/
- https://medium.com/@abdelkrim.hadjidj/best-practices-for-using-apache-NiFi-in-real-world-projects-3-takeaways-1fe6912101db
- https://dataworkssummit.com/san-jose-2018/session/using-nifi-to-simplify-data-flow-streaming-use-cases-mastercard/
- https://dataworkssummit.com/washington-dc-2019/session/building-the-high-speed-cyber-security-data-pipeline-using-apache-NiFi/
- https://dataworkssummit.com/washington-dc-2019/session/event-driven-messaging-and-actions-using-apache-flink-and-apache-NiFi/
- https://dataworkssummit.com/washington-dc-2019/session/cold-supply-chain-logistics/

