
Чем обмен данными через XCom отличается от использования Dataset и какой из механизмов выбирать для обмена данными между задачами Apache Airflow: разбираем на практическом примере.
Обмен данными через XCom
В Apache Airflow есть несколько механизмов для обмена данными между задачами: XCom и набор данных (Dataset). При общей цели они предназначены для разных сценариев и имеют свои особенности. XCom(Cross-Communication) позволяет задачам обмениваться небольшими сообщениями. Обычно XCom используется в следующих случаях:
- когда нужно передать небольшие объемы данных между задачами;
- когда данные должны быть доступны немедленно после выполнения задачи;
- когда необходимо передать параметры конфигурации или метаданные.
Понятие Dataset появилось в Airflow с версии 2.4, о чем мы писали здесь. Набор данных помогает организовать зависимости между задачами на уровне данных. Dataset определяет, какие данные были обновлены и какие задачи должны быть запущены в ответ на эти изменения. Например, есть задача, которая обновляет таблицу в базе данных, и нужно, чтобы другие задачи запускались только после того, как данные будут обновлены. Dataset используется для отслеживания состояния данных, и задачи, зависящие от этого Dataset, будут выполнены автоматически.
Обычно набор данных используется в следующих ситуациях:
- когда необходимо организовать зависимости задач на основе состояния данных;
- когда одна задача может влиять на выполнение множества других задач в зависимости от обновленных данных;
- когда данные обновляются асинхронно, и необходимо запускать задачи только после завершения этого процесса.
Таким образом, выбирая между XCom и Dataset, первый вариант подходит, когда нужно передать конкретные значения между задачами в рамках одного DAG, и эти данные являются частью логики выполнения задач. Dataset подойдет для более сложных зависимостей на уровне данных, особенно когда их обновление влияет на выполнение нескольких задач в разных DAG или важна отслеживаемость состояния данных.
Чтобы продемонстрировать, как это работает, напишем DAG из 3-х задач генерации и обработки данных о пользовательских действиях на веб-страницах. DAG называется запускается ежедневно, начиная с текущей даты, без повтора выполнения задач за прошедший период, т.к. catchup=False. 1-ая задача генерирует фейковые данные о пользовательских действиях, 2-ая обрабатывает эти данные для получения статистики, а 3-я логирует результаты в CSV-файл. Обмен данными между задачами организуем через XCom. В качестве стартовой и конечной точки добавим задачи с пустыми операторами. Код DAG-файла, написанный в стиле смешения традиционного и TaskFlow API, выглядит так:
from airflow import DAG
from airflow.decorators import task
from airflow.operators.dummy import EmptyOperator
from datetime import datetime, timedelta
from faker import Faker
import random
import csv
import os
default_args = {
'owner': 'airflow',
'start_date': datetime.now() - timedelta(days=1),
'retries': 1
}
dag = DAG(
dag_id='ANNA_DAG_XCom',
default_args=default_args,
schedule_interval='@daily'
)
@task()
def generate_user_data(**kwargs):
fake = Faker()
# Генерация веб-страниц и пользователей
num_pages = 10
num_users = 10
pages = [fake.url() for _ in range(num_pages)]
users = [fake.ascii_free_email() for _ in range(num_users)]
# События
events = ['click', 'scroll', 'submit', 'download', 'focus']
# Генерация пользовательских событий для 5 пользователей
user_events_list = []
for _ in range(5): # Генерация данных для 5 пользователей
num_user_pages = random.randint(1, 5) # Количество страниц для пользователя
user_events = {
'user': random.choice(users),
'date': datetime.now().strftime('%Y-%m-%d'),
'actions': [
{
'page': random.choice(pages),
'events': [
{
'type': random.choice(events),
'quantity': fake.random_int(min=0, max=10)
} for _ in range(random.randint(1, 5)) # Количество событий на странице
]
} for _ in range(num_user_pages) # Генерация действий на страницах
]
}
user_events_list.append(user_events)
kwargs['ti'].xcom_push(key='user_data', value=user_events_list)
@task()
def calculate_statistics(**kwargs):
user_data = kwargs['ti'].xcom_pull(key='user_data', task_ids='generate_user_data')
overall_statistics = []
for entry in user_data:
user = entry['user']
date = entry['date']
for action in entry['actions']:
page = action['page']
for event in action['events']:
event_type = event['type']
quantity = event['quantity']
# Общая статистика
overall_statistics.append({
'date': date,
'user': user,
'page': page,
'event': event_type,
'quantity': quantity
})
kwargs['ti'].xcom_push(key='overall_statistics', value=overall_statistics)
@task()
def log_statistics(**kwargs):
# Логирование общей статистики
overall_statistics = kwargs['ti'].xcom_pull(key='overall_statistics', task_ids='calculate_statistics')
with open('/content/airflow/data/overall_statistics.csv', mode='w', newline='') as file:
writer = csv.DictWriter(file, fieldnames=['date', 'user', 'page', 'event', 'quantity'])
writer.writeheader()
for entry in overall_statistics:
writer.writerow(entry)
with DAG(dag_id='ANNA_DAG_XCom', start_date=datetime.now() - timedelta(days=1), schedule='@daily', catchup=False) as dag:
start_task = EmptyOperator(task_id='start_task')
generate_user_data_task = generate_user_data()
calculate_statistics_task = calculate_statistics()
log_statistics_task=log_statistics()
end_task = EmptyOperator(task_id='end_task')
# Задаем последовательность выполнения задач
start_task >> generate_user_data_task >> calculate_statistics_task >> log_statistics_task >> end_task
Запустим этот DAG в AirFlow.
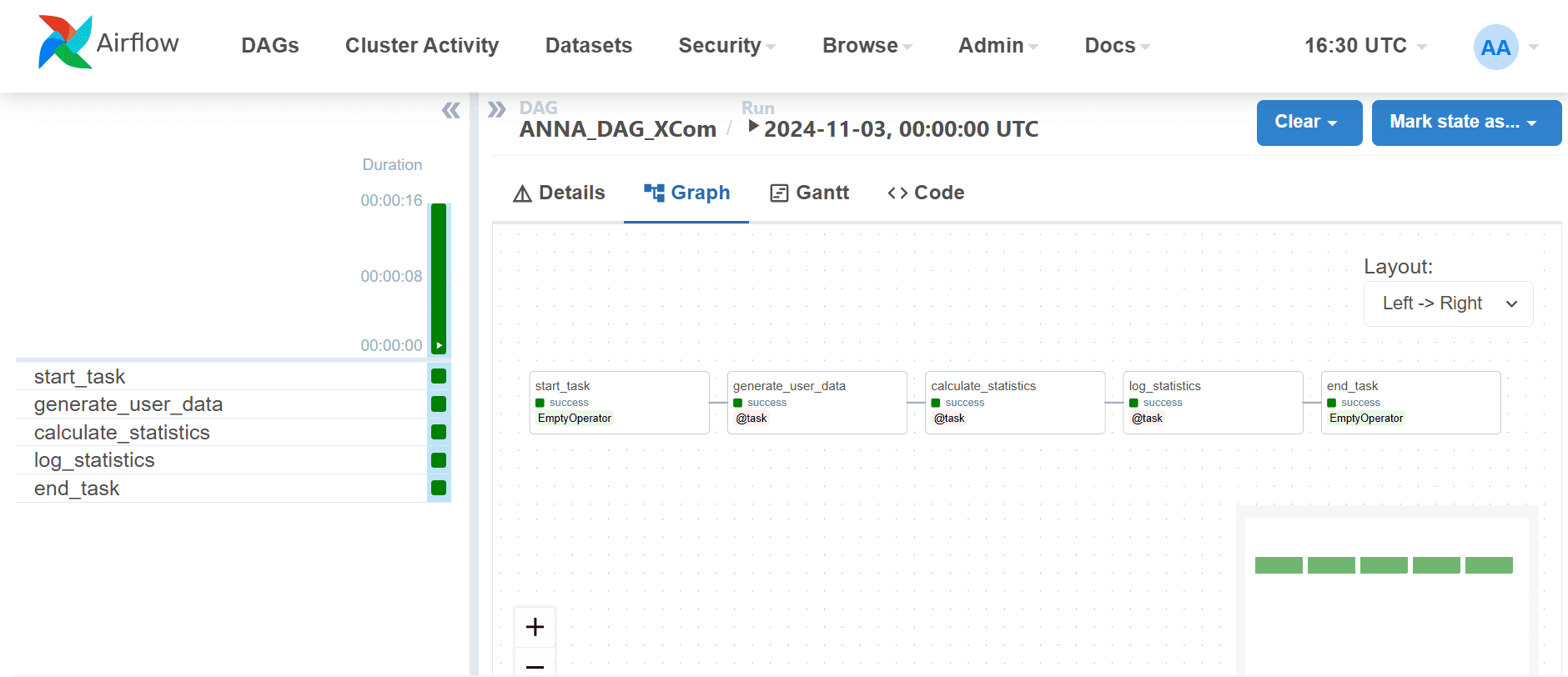
XCom-объекты отображаются в интерфейсе фреймворка.
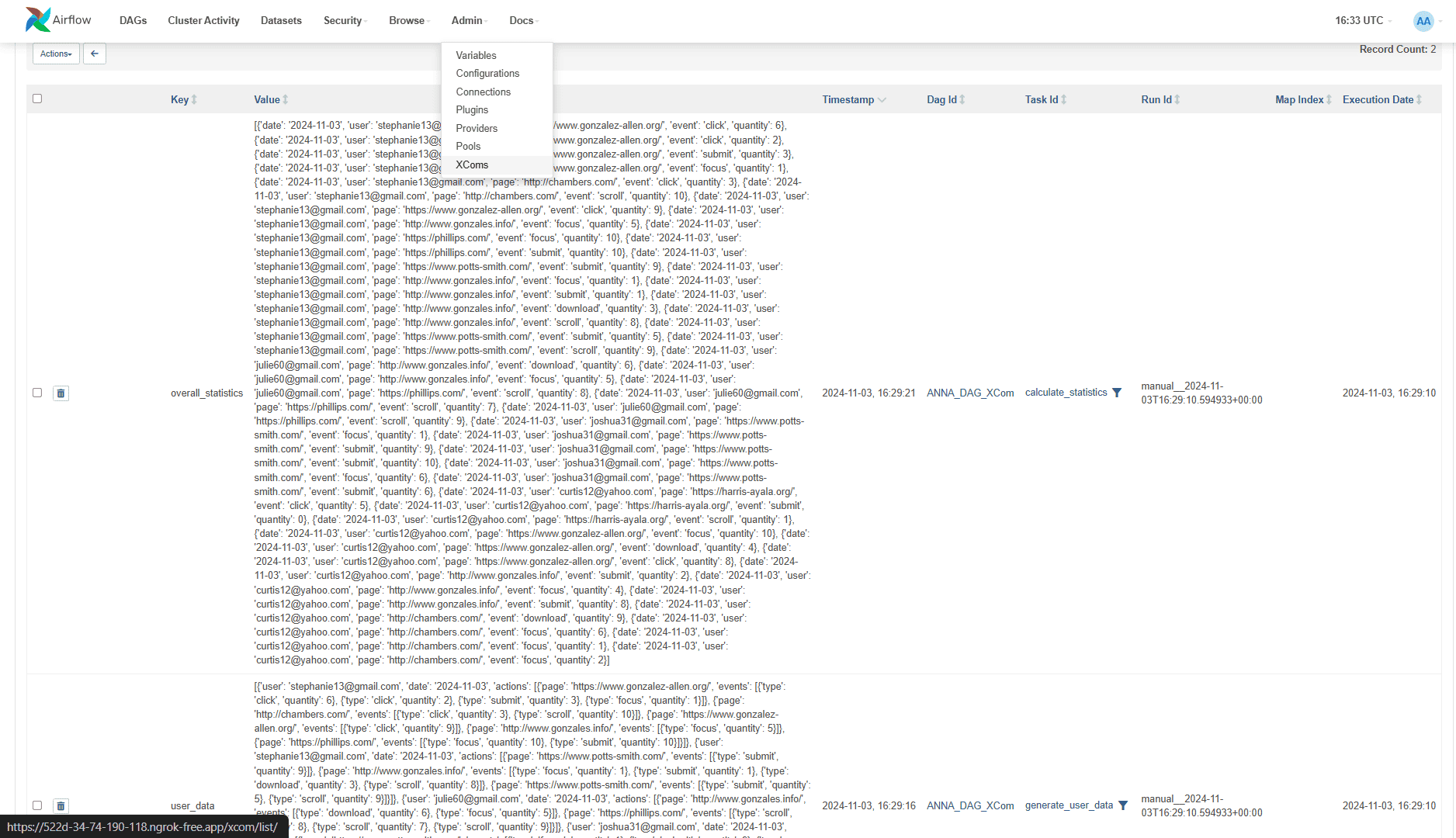
Сгенерированный файл статистики пользовательского поведения сохранен в директории Colab, где я запускала AirFlow. Этот CSV-файл можно посмотреть и скачать.
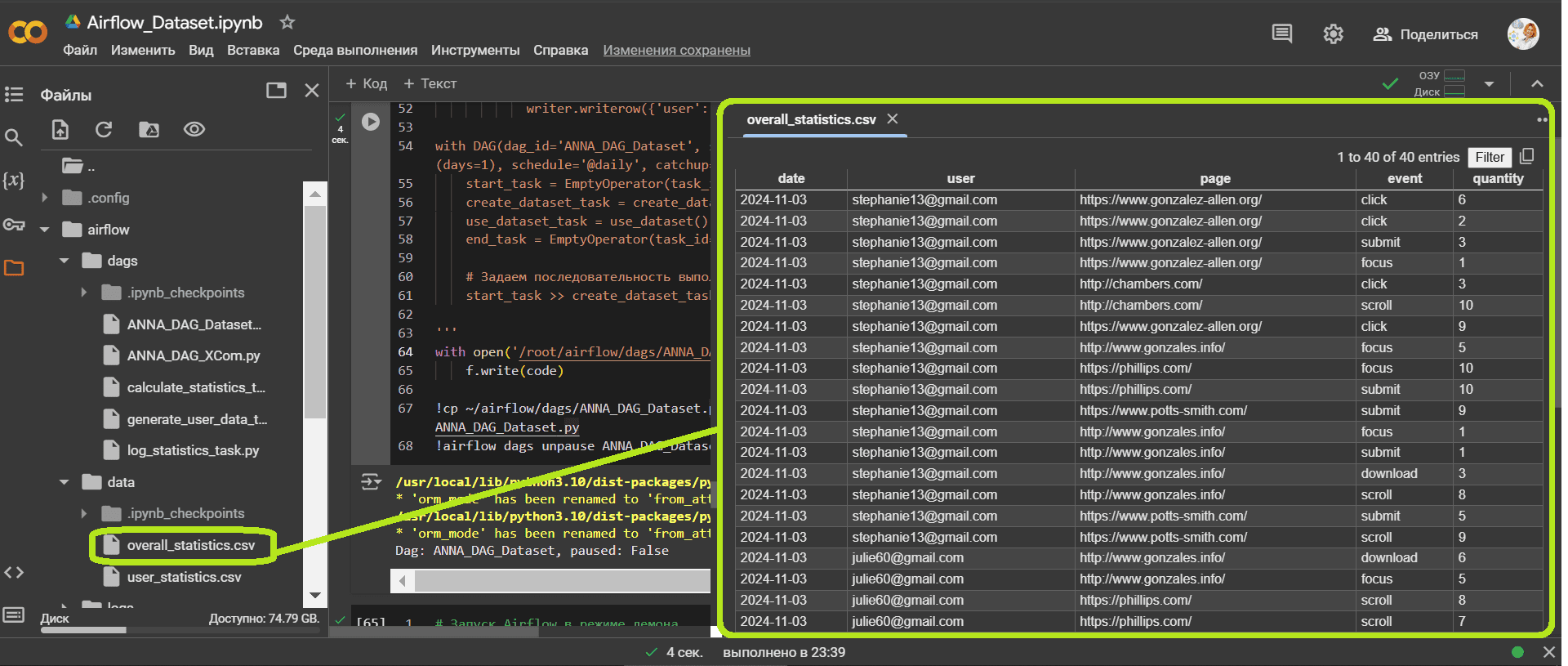
Обмен данными через Dataset в Airflow
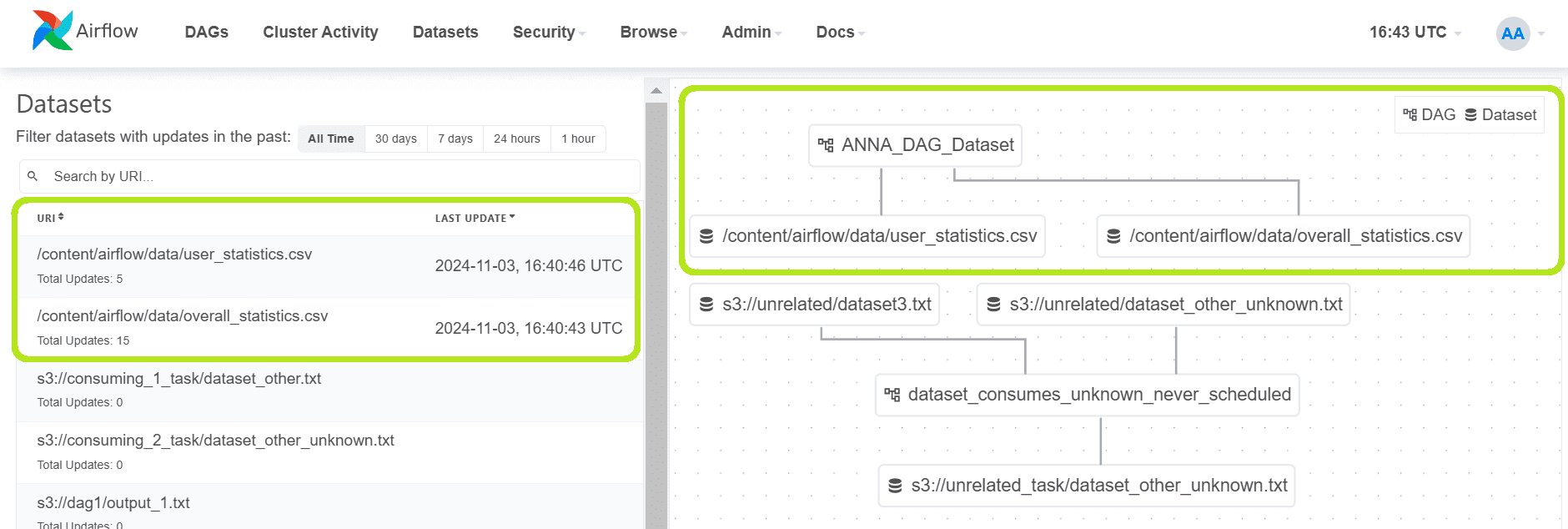
Рассмотрим аналогичный пример с Dataset для обмена данными. Dataset предоставляет возможность обмениваться данными между DAG-ами, но его реализация требует некоторой настройки среды. Например, я буду использовать ранее сгенерированный файл в качестве источника данных. Сперва определим два набора данных: исходный файл данных data_file и файл с обработанными данными processed_data_file. Задача create_dataset проверяет существование исходного файла. Если файл не найден или пуст, записывает сообщение об ошибке в лог-файл. Задача use_dataset считывает данные из CSV-файла и подсчитывает количество событий для каждого пользователя, а также записывает результаты в новый CSV-файл user_statistics.csv. Чтобы выполнять эту задачу, если ни одна из предыдущих задач не завершилась с ошибкой и хотя бы одна завершилась успешно, зададим ей правило триггера none_failed_min_one_success. Аналогично предыдущему примеру в качестве стартовой и конечной точки добавим задачи с пустыми операторами. Код DAG-файла выглядит так:
from airflow import DAG, Dataset
from airflow.decorators import task
from airflow.operators.dummy import EmptyOperator
from datetime import datetime, timedelta
import csv
import os
# Определяем путь к файлу
file_path = '/content/airflow/data/overall_statistics.csv'
log_file_path = '/content/airflow/data/dataset_errors.log'
output_file_path = '/content/airflow/data/user_statistics.csv'
# Определяем Dataset
data_file = Dataset(file_path)
processed_data_file = Dataset(output_file_path)
@task(outlets=[data_file])
def create_dataset():
# Проверяем, существует ли файл
if not os.path.exists(file_path):
raise FileNotFoundError(f"Файл {file_path} не найден")
# Проверяем, не пустой ли файл
if os.path.getsize(file_path) == 0:
with open(log_file_path, 'a') as log_file:
log_file.write(f"Dataset not found: {file_path} - {datetime.now()}")
return
print(f"Файл {file_path} существует и готов к использованию")
@task(outlets=[processed_data_file], trigger_rule='none_failed_min_one_success')
def use_dataset():
user_statistics = {}
with open(file_path, 'r') as f:
reader = csv.DictReader(f, delimiter=',')
for row in reader:
user = row['user']
if user not in user_statistics:
user_statistics[user] = 0
user_statistics[user] += int(row['quantity'])
with open(output_file_path, mode='w', newline='') as file:
writer = csv.DictWriter(file, fieldnames=['user', 'events_quantity'])
writer.writeheader()
for user, count in user_statistics.items():
writer.writerow({'user': user, 'events_quantity': count})
with DAG(dag_id='ANNA_DAG_Dataset', start_date=datetime.now() - timedelta(days=1), schedule='@daily', catchup=False) as dag:
start_task = EmptyOperator(task_id='start_task')
create_dataset_task = create_dataset()
use_dataset_task = use_dataset()
end_task = EmptyOperator(task_id='end_task')
# Задаем последовательность выполнения задач
start_task >> create_dataset_task >> use_dataset_task >> end_task
Запустим этот DAG в AirFlow.
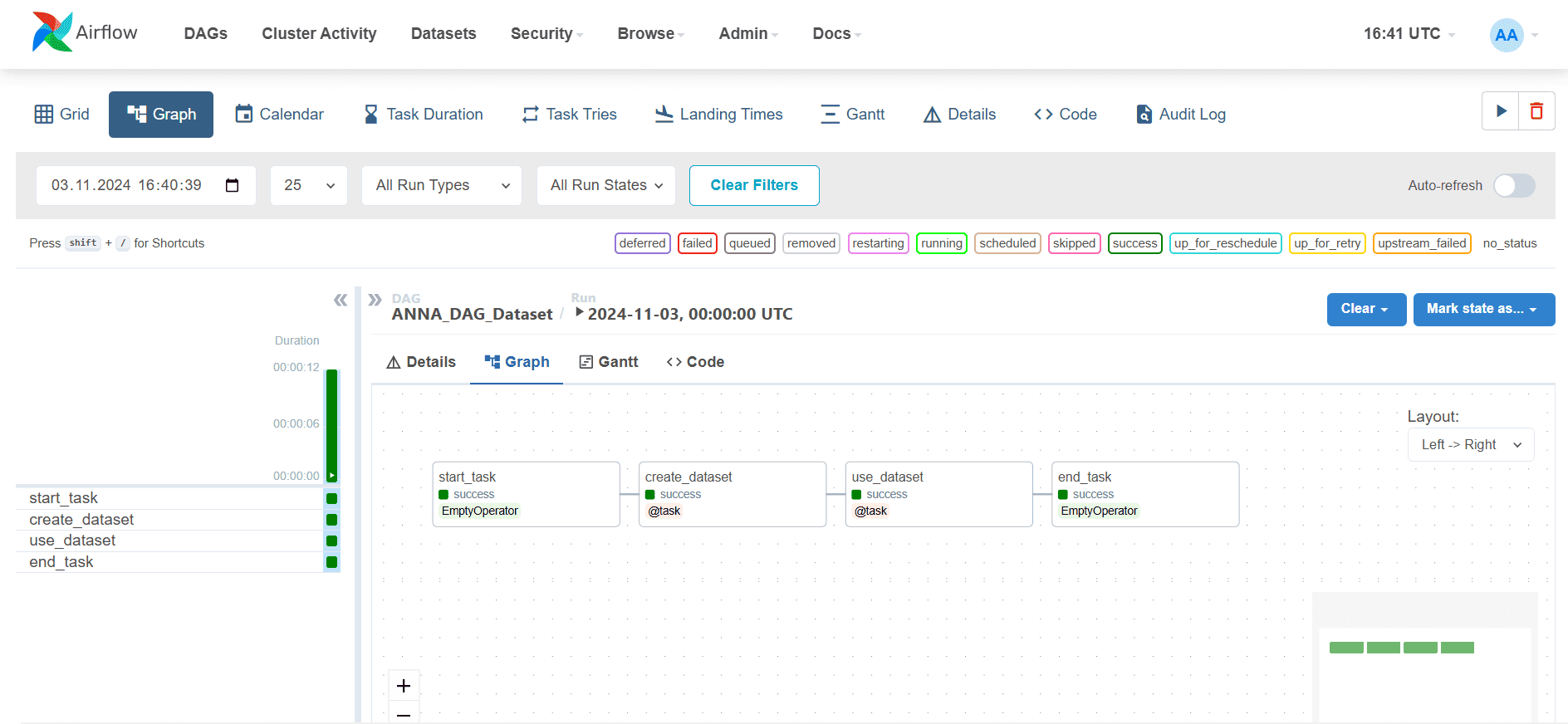
Сгенерированные датасеты отображаются в веб-интерфейсе фреймворка.
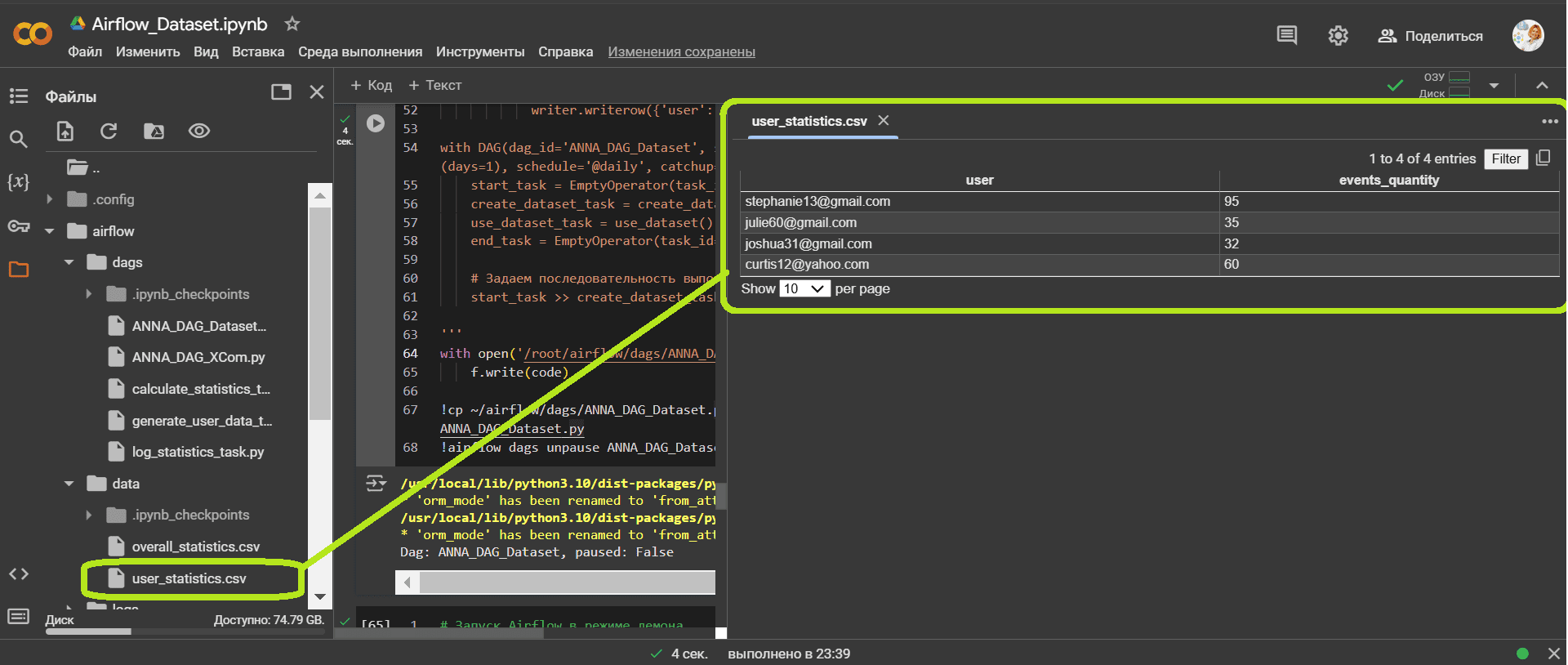
Как и в предыдущем случае, сгенерированный CSV-файл статистики пользовательского поведения сохранен в директории Colab, где запущен AirFlow.
Обмен данными через XCom-объекты мне показался немного проще, чем через наборы данных. Однако, поскольку XCom имеет ограниченный размер и по умолчанию сохраняется в базе данных метаданных, он подходит только для простых кейсов. Поэтому дата-инженеру полезно знать про возможности Dataset, который может быть подгружен из любого, в т.ч. внешнего источника, и уметь пользоваться этим механизмом. Читайте в новой статье о переименовании Dataset в Asset и других новинках Airflow 3.0.
Узнайте больше про администрирование и эксплуатацию Apache AirFlow для оркестрации пакетных процессов в задачах реальной дата-инженерии на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:

