 1190
1190 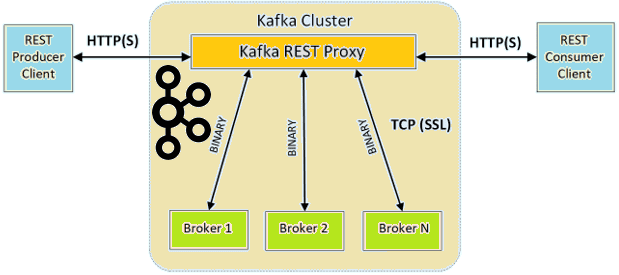
Содержание
Продолжая разбираться с Confluent REST Proxy для Apache Kafka, сегодня рассмотрим основные достоинства и недостатки этого RESTful API. Читайте далее, что Confluent REST Proxy позволяет делать с Apache Kafka и что ограничивает его взаимодействие с самой популярной Big Data платформой потоковой обработки событий.
6 главных преимуществ RESTful API к Apache Kafka
Как мы уже писали, основное назначение RESTful API к Apache Kafka – это упрощение процессов генерации и потребления сообщений, мониторинга состояния кластера и его администрирования без использования собственного протокола Kafka или специальных клиентов. Для всего этого RESTful-интерфейс должен предоставлять все Java-функции producer’ов, consumer’ов и инструментов командной строки. Все это реализуется следующим образом [1]:
- метаданные о кластере (сведения о брокерах, топиках, разделах и конфигурациях) можно прочитать с помощью GET-запросов для соответствующих URL-адресов;
- производители сообщений, от которых API принимает запросы на отправку данных для определенных топиков или разделов, маршрутизируя их через небольшой пул producer’ов. При этом REST Proxy позволяет настроить конфигурацию производителя, хотя и не для каждого запроса, т.к. экземпляры producer’ов являются общими. Тем не менее, можно глобально настроить параметры, передав новые настройки производителя в конфигурации REST Proxy. Например, параметр type, чтобы включить сжатие данных на уровне всего сайта для уменьшения объема хранилища и накладных расходов на сетевую передачу.
- Потребители сообщений отслеживают состояние и привязаны к конкретным экземплярам REST Proxy. Фиксация смещения может быть автоматической или явно запрошенной пользователем. Поскольку пока пропускная способность каждого потребителя ограничена одним потоком, рекомендуется использовать несколько потребителей для ее повышения. При том, что экземпляры потребителей не являются общими, они совместно используют ресурсы базового сервера. Поэтому через API доступны лишь некоторые параметры конфигурации. Однако, их можно настроить глобально, передав параметры потребителя в конфигурации REST Proxy. Обычно рекомендуется использовать потребителей более высокого уровня. Однако, иногда бывает полезно выполнять операции чтения низкого уровня, например, для получения сообщений с определенными смещениями.
- Форматы данных – благодаря связи со Schema Registry, о чем мы рассказывали здесь, Confluent REST Proxy может читать и записывать данные JSON, необработанные байты, закодированные с помощью base64, или с использованием Avro, Protobuf или схемы JSON.
- Балансировка нагрузки — REST Proxy предназначен для поддержки нескольких экземпляров, работающих вместе для распределения нагрузки, и может безопасно работать с различными механизмами балансировки нагрузки, таких как, например, циклический DNS, службы обнаружения и балансировщики нагрузки.
- Администрирование — Confluent REST Proxy API v3 позволяет создавать или удалять топики Kafka, а также обновлять или сбрасывать их конфигурации.
Что не так с Confluent REST Proxy: 3 главных недостатка
Обратной стороной этих достоинств являются следующие недостатки, которые можно рассматривать как ограничения [1]:
- не поддерживаются запросы на генерацию сообщений в несколько топиков одновременно – пока каждый запрос от producer’а может обращаться лишь к одному топику или разделу. На практике это ограничение не слишком усложняет работу, т.к. большинство вариантов использования не требуют генерации сообщений в несколько топиков. Если же такой сценарий необходим, можно разделить данные на несколько запросов.
- через API недоступно большинство переопределений producer’а или consumer’а в запросах, хотя есть несколько переопределений ключей, а глобальные переопределения могут быть установлены администратором. Это обусловлено несколькими причинами. Во-первых, прокси-серверы являются мультитенантными, поэтому для большинства запрашиваемых пользователями переопределений требуются дополнительные ограничения, чтобы гарантировать, что они не влияют на других пользователей. Во-вторых, слишком сильная привязка API к реализации ограничивает будущие улучшения интерфейса.
Наконец, стоит помнить, что на уровне данных REST Proxy является синхронным протоколом запроса-ответа. Однако, Kafka предоставляет возможности пакетного масштабирования до десятков параллельных экземпляров REST Proxy. Существуют развертывания, в которых четыре экземпляра REST Proxy могут обрабатывать примерно 20 000 событий в секунду, что вполне достаточно для множества сценариев использования. В будущем HTTP, возможно, будет поддерживать потоковой передачи событий в качестве альтернативы парадигме «запрос-ответ», но накладные расходы все же останутся из-за наличия REST Proxy в середине обмена данными [2]. Как сократить эти накладные расходы, передавая только нужные данные с помощью альтернативного API GraphQL, мы рассмотрим в следующий раз.
На практике разобраться со всеми преимуществами API-интерфейсов Apache Kafka и способами обхода их ограничений для эффективного администрирования кластера и разработки приложений потоковой аналитики больших данных вы сможете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники
- https://docs.confluent.io/platform/current/kafka-rest/index/
- https://www.confluent.io/blog/http-and-rest-api-use-cases-and-architecture-with-apache-kafka/

