
В продолжение темы про озера данных (Data Lake) и Apache Hadoop, сегодня мы рассмотрим еще 3 примера использования этих технологий Big Data для аналитики больших данных в промышленности. Читайте в нашей статье, как косметический гигант L’Oréal создает новые продукты с помощью платформы Talend Data Fabric, «УРАЛХИМ» прогнозирует объемы продукции и...

Продолжая разговор про интеграцию информационных систем с помощью стриминговой платформы, сегодня мы рассмотрим преимущества event streaming архитектуры на примере Apache Kafka. Также читайте в нашей статье про 5 ключевых сценариев использования Кафка в потоковой обработке событий: от IoT/IIoT до микросервисного разделения в системах аналитики больших данных (Big Data) и машинного...

В этой статье рассмотрим несколько примеров по аналитике больших данных в Elasticsearch (ES), а также разберем возможности алгоритмов машинного обучения в ELK Stack. Читайте, как использовать NoSQL-СУБД ES в качестве озера данных для проверки различных бизнес-гипотез с помощью Machine Learning, показывая результаты моделирования в интерфейсе Kibana: практическая аналитика Big Data....

Сегодня мы расскажем, что такое программная печать, зачем ритейлеры используют эту технологию и как programmatic print связана с Big Data. Читайте в нашей статье, как IKEA, «Рив Гош», «Ив Роше» и Bonprix используют Big Data для персонального маркетинга в своих рекламных кампаниях, а также повышают лояльность клиентов и стимулируют продажи...

В продолжение темы про использование технологий Big Data и Machine Learning в FMCG-бизнесе, сегодня мы поговорим, как распознавание лиц помогает сформировать персональные маркетинговые предложения и насколько это законно. Разбираемся с видеоаналитикой и 152-ФЗ «О персональных данных» на примерах отечественных и зарубежных ритейлеров. От воров до VIP-клиентов: 5 примеров распознавания лиц...

Современное видеонаблюдение в ритейле – это не только обнаружение магазинных воришек, а полноценная аналитика Big Data с мощными алгоритмами Machine Learning для оперативного и стратегического управления. В этой статье мы приготовили для вас 7 сценариев практического использования технологий видеоаналитики в FMCG-секторе с реальными кейсами их внедрения в России на примере...

Цифровизация ритейла – это не только внедрение Apache Hadoop, Spark, Kafka и Machine Learning для аналитики больших данных, прогнозирования спроса и оптимизации складской логистики. Сегодня мы расскажем, что такое коботы и как эти технологии помогают бизнесу. В этой статье мы собрали для вас 7 примеров использования коллаборативных роботов в FMCG....
Вчера мы затрагивали тему управления поставками в ритейле с помощью технологий Big Data и Machine Learning. Теперь разберем подробнее, как большие данные, машинное обучение и интернет вещей меняют складскую логистику и насколько это выгодно бизнесу. Сегодня мы собрали для вас 7 практических примеров: кейсы от отечественных и зарубежных транспортных компаний,...
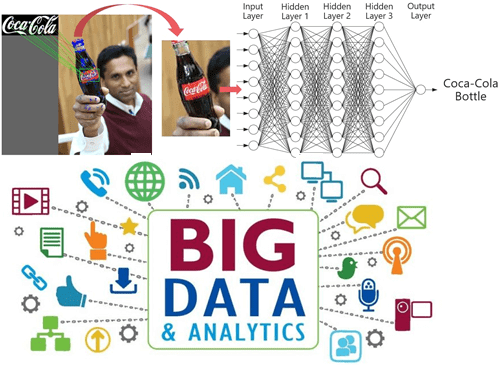
Продолжая рассказывать про применение технологий Big Data и Machine Learning в ритейле, сегодня мы собрали для вас еще 3 интересных примера от FMCG-гигантов. Читайте в нашей статье, как большие данные и машинное обучение помогли Coca-Cola, Starbucks, Neutrogena, Magnum, Procter&Gamble и Nestlé наладить геолокационный маркетинг, повысить узнаваемость своих брендов и улучшить...

По запросу одного из наших клиентов, этой статьей мы открываем серию публикаций про применение технологий Big Data и Machine Learning в торговле быстрооборачиваемых товаров повседневного спроса (FMCG, Fast moving consumer goods). Сегодня рассмотрим, как большие данные, машинное обучение и прочие методы искусственного интеллекта используются в производстве и продаже газированных напитков...

В этом материале рассмотрим, для чего современному менеджеру нужно обучение технологиям Big Data, когда стоит строить собственное Data Lake, чем цифровизация отличается от автоматизации, а также почему курс Аналитика больших данных для руководителей – это эффективная инвестиция в будущее вашего бизнеса. Почему вам нужна аналитика больших данных: мотивация эффективного обучения...

Жесткий режим карантина и самоизоляции из-за нового коронавируса кардинально изменил мировую экономику, сократив доходы большинства работающего населения. Однако, в некоторых отраслях наблюдается беспрецедентный рост продаж. Сегодня мы расскажем, какие компании продолжают успешно развиваться, несмотря на COVID-19 и вызванные им ограничительные меры. Спойлер: все они связаны с большими данными (Big Data)...

В продолжение темы про корпоративные хранилища данных, сегодня мы рассмотрим облачные варианты Data Warehouse с учетом тренда на расширенную аналитику Big Data на базе машинного обучения. Читайте в нашей статье про синергию классической LSA-архитектуры локального КХД с Лямбда-подходом, MPP-СУБД, а также Apache Hadoop, Spark, Hive и другими технологиями больших данных....

Сегодня мы поговорим про качество данных – что это за показатель, в чем он измеряется и почему так важен для машинного обучения и других приложений Big Data. Читайте в нашей статье про процессы и инструменты управления качеством данных, а также профессию Data Quality инженера. Почему большие данные должны быть качественными...
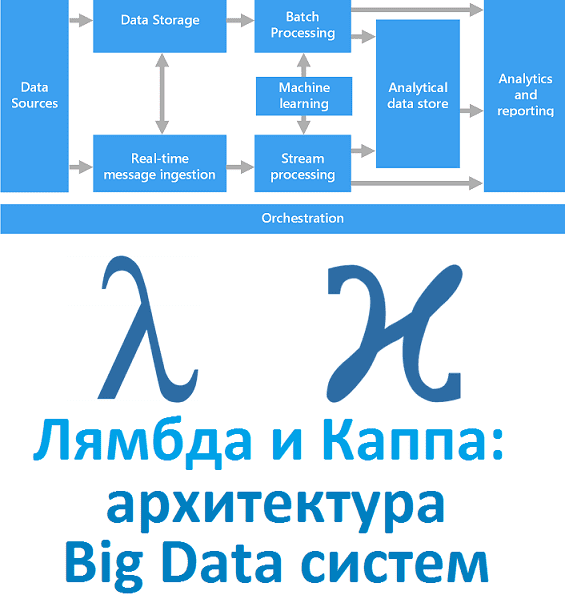
Вчера мы рассказали, что такое лямбда-архитектура. Сегодня рассмотрим Каппа - альтернативный подход к проектированию Big Data систем. Читайте в нашей статье, зачем нужна эта концепция, каковы ее достоинства и недостатки, чем Каппа отличается от Лямбда, где это используется на практике и при чем тут Apache Kafka с Machine Learning. Зачем...
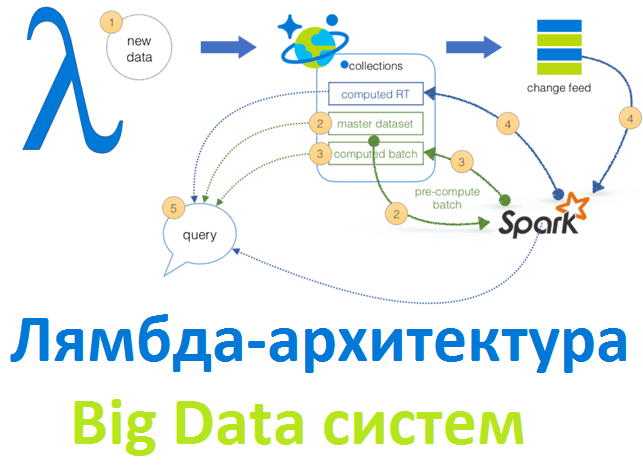
Рассматривая основы больших данных, сегодня мы расскажем лямбда-архитектуру, одну из двух главных подходов к построению Big Data систем. Читайте в нашей статье, зачем нужна эта концепция и как она работает, а также при чем тут машинное обучение, интернет вещей, Apache Spark и Hadoop. Что такое Лямбда-архитектура и зачем она нужна...

Завершая цикл публикаций о применении больших данных и машинного обучения в оперативно-розыскной деятельности и других задачах МВД, сегодня мы рассмотрим перспективы этих технологий: заменят ли они живых полицейских и когда это произойдет. Спойлер: еще не скоро. Читайте в нашей статье про доверие к Big Data и Machine Learning для их...

Чтобы зарядить вас оптимизмом и в очередной раз показать практическую пользу от технологий больших данных, машинного обучения и других методов искусственного интеллекта, сегодня мы расскажем, как Big Data и Machine Learning предупреждают аварии, диагностируют смертельные болезни на ранних стадиях и помогают найти без вести пропавших людей. Большие данные и машинное...

Продолжая разговор о том, как технологии Big Data и Machine Learning борются с нелегитимным оборотом денег, сегодня мы рассмотрим сферу страхования. Читайте в нашей статье, как графовая аналитика больших данных и алгоритмы машинного обучения помогают страховым компаниям и сотрудникам полиции раскрывать мошеннические схемы и предупреждать правонарушения. Страшно аж жуть: рынок...
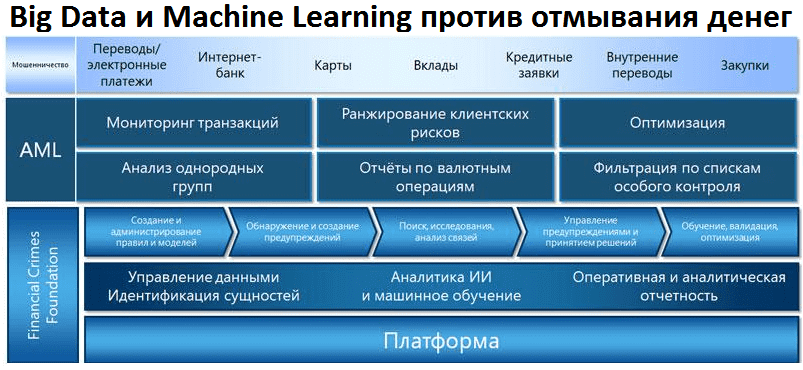
Сегодня мы продолжим разговор про антифрод-системы и расскажем, как аналитика Big Data и модели Machine Learning помогают бороться с отмыванием денег. Читайте в нашей статье, зачем нужен светофор транзакций, что такое AML-системы и при чем тут графы больших данных. Светофор транзакций и Big Data в антифрод-системах Сначала рассмотрим, как работают...