
В продолжение темы про использование технологий Big Data и Machine Learning в FMCG-бизнесе, сегодня мы поговорим, как распознавание лиц помогает сформировать персональные маркетинговые предложения и насколько это законно. Разбираемся с видеоаналитикой и 152-ФЗ «О персональных данных» на примерах отечественных и зарубежных ритейлеров. От воров до VIP-клиентов: 5 примеров распознавания лиц...

Современное видеонаблюдение в ритейле – это не только обнаружение магазинных воришек, а полноценная аналитика Big Data с мощными алгоритмами Machine Learning для оперативного и стратегического управления. В этой статье мы приготовили для вас 7 сценариев практического использования технологий видеоаналитики в FMCG-секторе с реальными кейсами их внедрения в России на примере...

Цифровизация ритейла – это не только внедрение Apache Hadoop, Spark, Kafka и Machine Learning для аналитики больших данных, прогнозирования спроса и оптимизации складской логистики. Сегодня мы расскажем, что такое коботы и как эти технологии помогают бизнесу. В этой статье мы собрали для вас 7 примеров использования коллаборативных роботов в FMCG....
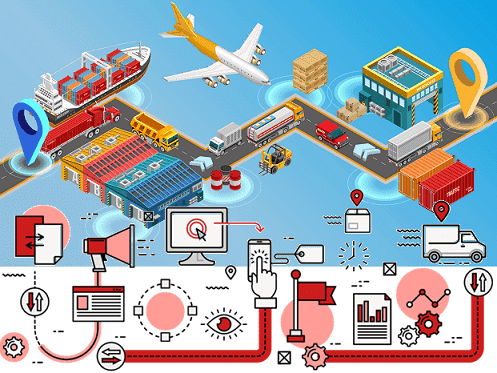
Вчера мы затрагивали тему управления поставками в ритейле с помощью технологий Big Data и Machine Learning. Теперь разберем подробнее, как большие данные, машинное обучение и интернет вещей меняют складскую логистику и насколько это выгодно бизнесу. Сегодня мы собрали для вас 7 практических примеров: кейсы от отечественных и зарубежных транспортных компаний,...
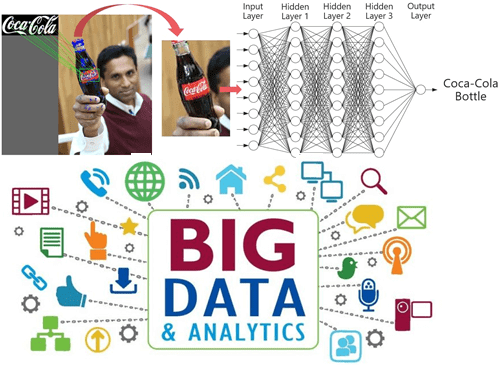
Продолжая рассказывать про применение технологий Big Data и Machine Learning в ритейле, сегодня мы собрали для вас еще 3 интересных примера от FMCG-гигантов. Читайте в нашей статье, как большие данные и машинное обучение помогли Coca-Cola, Starbucks, Neutrogena, Magnum, Procter&Gamble и Nestlé наладить геолокационный маркетинг, повысить узнаваемость своих брендов и улучшить...

По запросу одного из наших клиентов, этой статьей мы открываем серию публикаций про применение технологий Big Data и Machine Learning в торговле быстрооборачиваемых товаров повседневного спроса (FMCG, Fast moving consumer goods). Сегодня рассмотрим, как большие данные, машинное обучение и прочие методы искусственного интеллекта используются в производстве и продаже газированных напитков...

В этом материале рассмотрим, для чего современному менеджеру нужно обучение технологиям Big Data, когда стоит строить собственное Data Lake, чем цифровизация отличается от автоматизации, а также почему курс Аналитика больших данных для руководителей – это эффективная инвестиция в будущее вашего бизнеса. Почему вам нужна аналитика больших данных: мотивация эффективного обучения...
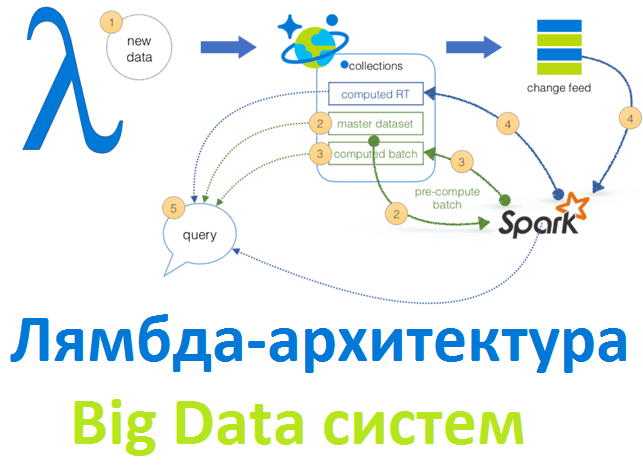
Рассматривая основы больших данных, сегодня мы расскажем лямбда-архитектуру, одну из двух главных подходов к построению Big Data систем. Читайте в нашей статье, зачем нужна эта концепция и как она работает, а также при чем тут машинное обучение, интернет вещей, Apache Spark и Hadoop. Что такое Лямбда-архитектура и зачем она нужна...
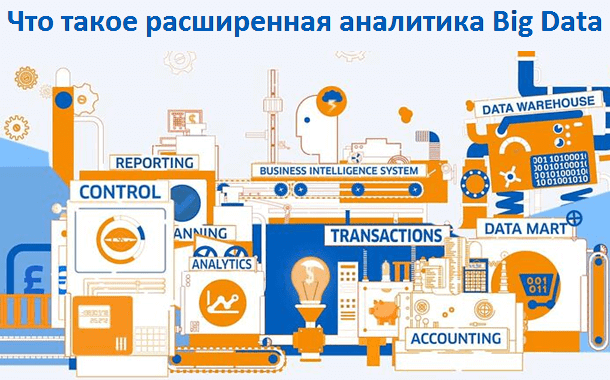
Сегодня мы рассмотрим, что такое расширенная аналитика и дополненное управление данными, как они связаны с цифровизацией бизнеса и почему исследовательское бюро Gartner включило эти технологии в ТОП-10 самых перспективных трендов 2020 года. Читайте в нашей статье, как машинное обучение (Machine Learning) помогает аналитикам и руководителям находить во множестве больших данных...

В этой статье мы разберем одно из ключевых понятий цифровизации: что такое предиктивная аналитика и чем она отличается от дескриптивной. Также рассмотрим на практических примерах, какие виды аналитики больших данных (Big Data) еще бывают и где они используются. Читайте в нашем сегодняшнем материале, как машинное обучение (Machine Learning) и другая...

Рассматривать обучение Кафка интереснее на практических примерах. Сегодня мы расскажем, как Apache Kafka применяется в одной из крупнейших промышленных компаний России - ПАО «Северсталь». Эта статья написана на основе выступления Доната Фетисова, главного архитектора «Северсталь Диджитал». Доклад был представлен 7 декабря 2019 года на очередном ИТ-митапе компании Авито по Big...

Сегодня рассмотрим, чем корпоративное обучение большим данным (Big Data) отличается от индивидуального. Читайте в нашей статье, почему образовательные курсы по Apache Kafka, Hadoop, Spark и другим технологиям Big Data сплотят ваших сотрудников лучше любого тимбилдинга и как повысить эффективность такого обучающего тренинга. Почему корпоративное обучение Big Data эффективнее индивидуальных курсов:...

Продолжая разговор о том, как выбрать курсы по Kafka и другим технологиям больших данных (Big Data), сегодня рассмотрим, кому и в каких случаях нужно такое повышение квалификации. В этой статье мы собрали для вас 5 прикладных кейсов по Кафка для ИТ-профессионалов разных специальностей, от системного администратора до Data Engineer’а. А...
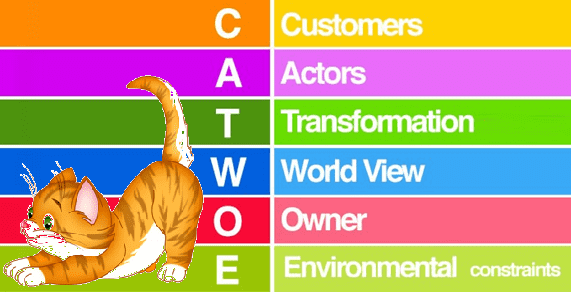
Сегодня мы поговорим о том, что такое CATWOE и зачем эта техника бизнес-анализа нужна руководителю. Также рассмотрим практическое применение этого метода на примере реального бизнес-кейса по цифровизации крупного предприятия и внедрения Big Data системы промышленного интернета вещей (Industrial Internet of Things, IIoT) в виде RFID-технологий. Как сэкономить время на бизнес-анализ...

Продолжая тему Cybersecurity, сегодня мы поговорим про биометрические системы: что это такое, как они работают и чем нарушают требования GDPR и № 152-ФЗ. Также в этом материале мы собрали для вас примеры таких наиболее известных проектов на базе технологий Big Data и Machine Learning. Что такое биометрические персональные данные и...

Продолжая разговор о том, что такое цифровой двойник и где эта технология Industry 4.0 используется на практике, сегодня мы рассмотрим несколько реальных примеров такой цифровизации в отечественной и зарубежной промышленности. Читайте в нашей статье про практическую синергию технологий Big Data, ML, PLM и IIoT в нефтегазовой, теплоэнергетической и машиностроительной отраслях....

В этой статье мы разберем, что такое цифровой двойник – один из главных трендов развития 4-ой промышленной революции (Industry 4.0) на ближайшие 5 лет. Читайте в сегодняшнем материале, зачем нужен виртуальный макет завода, из чего состоит информационная модель изделия и где используются цифровые двойники. Также рассмотрим, как CALS- и PLM-технологии...

На пороге 3-го десятилетия 21 века пришло время подвести итог прошедшим годам и cделать прогнозы на будущее. В этой статье мы поговорим о ключевых событиях минувших лет, помечтаем о том, что ждет Big Data и чего нам принесет эта ИТ-область. Также поделимся с вами своими планами на 2020 год: расскажем...

Рассмотрев ключевые сходства и различия Cassandra и HBase, сегодня мы поговорим, в каких случаях стоит выбирать ту или иную нереляционную СУБД для обработки больших данных (Big Data) в NoSQL-хранилище. Где используются NoSQL-СУБД в Big Data Прежде всего отметим основные области применения рассматриваемых нереляционных СУБД. Проанализировав наиболее известные примеры использования (use...

Благодаря быстроте, надежности и другим достоинствам Apache Cassandra, эта распределенная NoSQL-СУБД широко применяется во многих Big Data проектах по всему миру. В этой статье мы собрали для вас несколько интересных примеров реального использования Кассандры в 5 ключевых направлениях современного ИТ. Где используется Apache Cassandra: 5 главных приложений c примерами Промышленные...