
Для дата-инженеров и аналитиков про манипулирование данными в Apache Hadoop HDFS средствами SQL-запросов с помощью удобных инструментов. Apache Phoenix для обращения к таблицам NoSQL-хранилища HBase через SQL-запросы из графического интерфейса Hue. Как обратиться к таблицам HBase через SQL-запросы с Phoenix Apache HBase как хранилище данных над Hadoop HDFS предоставляет множество...

В рамках обучения разработчиков распределенных Spark-приложений, сегодня рассмотрим, как добавить функции из пользовательских JAR-файлов в кластер AWS EMR. Достоинства и недостатки действия начальной загрузки EMR с переопределением конфигурации Spark, а также расширенное управление зависимостями через spark-submit. Трудности обращения к пользовательским JAR в Amazon EMR с Apache Spark и Livy На...

Сегодня рассмотрим пару важных тем для администратора Greenplum: требования к программно-аппаратному окружению, а также особенности установки и настройки этой MPP-СУБД. Еще разберем, как Arenadata Cluster Manager облегчает и автоматизирует эти процессы в Arenadata DB. Программное окружение Greenplum: операционные системы и Java Greenplum 6 работает на следующих платформах операционных систем: Red...

При том, что развертывание и эксплуатация Apache Kafka на Kubernetes требуют от администратора кластера много сил и времени, эта идея имеет массу достоинств, о чем мы писали здесь. Поэтому появляются новые инструменты, которые облегчают эти процессы, например, KubeMQ или Strimzi, который мы рассмотрим в этой статье. Что такое Strimzi и при...

В этой статье для дата-инженеров и разработчиков распределенных приложений разберем кейс американской ИТ-компании FiscalNote, которая использует Apache Flink в качестве движка потоковой обработки информации со сторонних веб-сайтов. Трудности сериализации сообщений из очередей RabbitMQ с разной скоростью поступления Big Data и способы их обхода. Постановка задачи: требования для Flink-приложения FiscalNote специализируется...
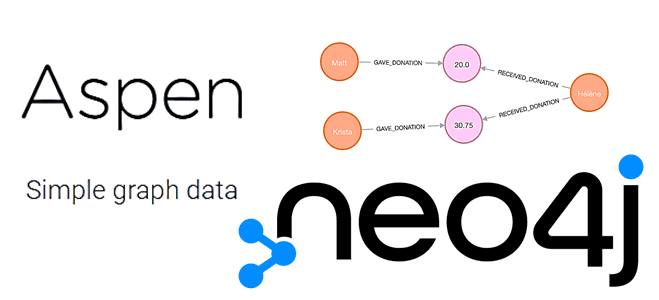
Обучая дата-аналитиков и разработчиков Neo4j, сегодня разберем, что такое Aspen, как этот язык разметки переводит текст в запрос Cypher с помощью одной командной строки и каким образом это пригодится для графовой аналитики больших данных в бизнес-приложениях. Что такое Aspen, а также как он связан с Neo4j и Cypher Будучи написанным на Ruby...
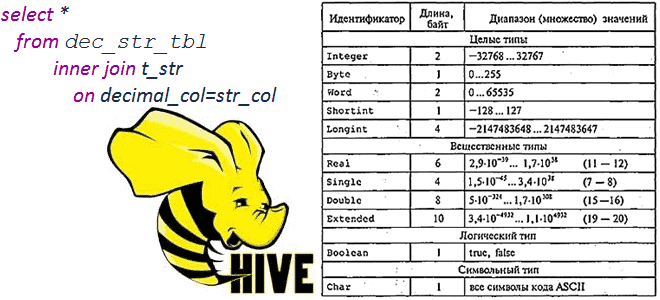
Сегодня рассмотрим тему, полезную для обучения администраторов SQL-on-Hadoop и разработчиков распределенных приложений: операции сравнения и арифметические вычисления между строковыми и десятичными типами в Apache Hive 1.2.0 и 3.1.0, а также MySQL и Microsoft SQL Server 2017. Про типы данных и SQL-запросы в Apache Hive Чтобы упростить сравнение, будем считать типы...

Мы уже писали, что Apache Hadoop 3.3.1 поддерживает технологию кодирования со стиранием (Erasure Coding, EC), которая экономит место на жестком диске по сравнению с репликацией. Однако, беспечное применение этой новой фичи может обернуться настоящей катастрофой. Кейс соцсети «Одноклассники» от ведущего разработчика Дениса Ефарова, представленный на конференции Smart Data для инженеров данных в...

2022 год только начался, а John Snow Labs уже радует разработчиков ML-приложений новым релизом библиотеки Spark NLP. Ключевые фичи 3.4.0 для версии Apache Spark 3.2.x на Scala 2.12: новые GPT-2 трансформеры, аннотаторы для ALBERT, XLNet, RoBERTa, XLM-RoBERTa и Longformer, расширенный хаб готовых Machine Learning моделей и конвейеров, а также исправление...

3 ноября 2021 года компания Confluent, которая занимается продвижением и коммерциализацией Apache Kafka, выпустила новый релиз ksqlDB, который включает 20 исправленных ошибок и 18 добавленных фич. Самое интересное в выпуске 0.22.0: улучшенные push- и pull-запросы, а также source-потоки и таблицы. 20 исправленных багов и 18 новых фич в ksqlDB 0.22.0...

В этой статье для разработчиков Spark-приложений и дата-инженеров рассмотрим особенности взаимодействия с облачным объектным хранилищем больших данных AWS S3. Как повысить эффективность и ускорить выполнения Spark-заданий на чтение данных из S3: рекомендации Pinterest. Пара советов по работе Apache Spark с AWS S3 Прежде чем перейти к опыту дата-инженеров фотохостинга Pinterest,...
В этой статье для администраторов Greenplum рассмотрим, как настроить систему сетевой защиты Kerberos для этой MPP-СУБД, чтобы контролировать доступ к хранящимся в ней данным с помощью сервера аутентификации. А также рассмотрим основные понятия и термины Kerberos применительно к Greenplum. Что такое Kerberos и зачем это в Greenplum Напомним, Kerberos –...

Сегодня разберем практический вопрос из обучения администраторов кластера Apache Kafka и разработчиков распределенных приложений. Про исключения в Kafka-приложениях: какие они бывают, почему случаются, с какими параметрами конфигурации связаны и что могут сказать о тонкостях потоковой обработки больших данных. Исключения и транзакции в Apache Kafka В ИТ под исключением понимается исключительная...

Чем хороши JSON-файлы и как с ними работать в Apache Spark и Hive: проблемы обработки вложенных структур данных и способы их решения на практических примерах. Как автоматизировать переименование некорректных названий полей во вложенных структурах данных JSON-файлов на любом количестве таблиц со множеством полей, чтобы создать таблицу в Hive Metastore и...
Недавно мы писали про пользу snapshot’ов Apache HBase на примере компании Vimeo. Сегодня рассмотрим кейс корпорации Box, которая специализируется на облачных enterprise-продуктах совместного управления контентом и файлами. Переход от локальной HBase к Google Cloud BigTable: сложности миграции и способы их обхода. Сходства и различия Apache HBase с Google Cloud BigTable...

Разбираемся с механизмами отказоустойчивости Flink-приложений. Что такое контрольные точки (Checkpoint), чем они отличаются от точек сохранения (Savepoint) и что между ними общего. А также при чем здесь snapshot, что выбирать в разных случаях и как это использовать для отказоустойчивости stateful-приложений Apache Flink. Snapshot как механизм обеспечения отказоустойчивости приложений Apache Flink...
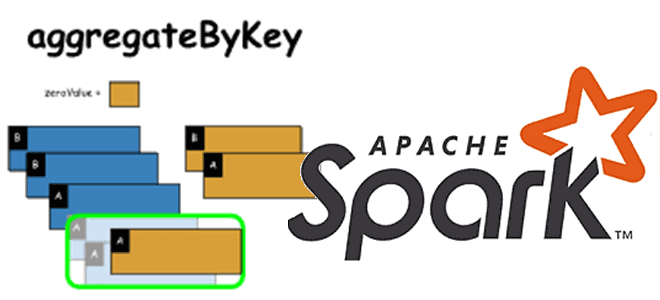
В рамках обучения дата-аналитиков и разработчиков Spark-приложений, сегодня рассмотрим одну из агрегатных функций обработки данных в этом распределенном вычислительном фреймворке. Чем aggregateByKey() отличается от reduceByKey() и groupByKey(), и когда стоит ее использовать. Как устроена функция aggregateByKey(): назначение и синтаксис Функция aggregateByKey() - одна из агрегатных функций, наряду с reduceByKey() и...

Чтобы сделать наши курсы по Apache Kafka для администраторов кластеров и разработчиков распределенных приложений еще более полезными, сегодня рассмотрим несколько полезных и значимых конфигурационных параметров этой платформы потоковой передачи событий. Что настроить на брокере, топике, продюсере и потребителе, как распараллелить потоки и обрабатывать транзакции. Настройка брокеров и потоков в Apache...

Добавляя новые интересные примеры в наши курсы для дата-аналитиков, разработчиков распределенных приложений и администраторов SQL-on-Hadoop, сегодня рассмотрим опыт видеоаналитики в компании Vimeo с использованием Apache Spark. Как быстро запросить множество данных из Apache HDFS через Phoenix и Spark из моментальных снимков HBase с минимальным влиянием на кластер. Аналитика очень больших...

Сегодня рассмотрим кейс международной ИТ-компании AppsFlyer, которая создает SaaS-решения для маркетинговой аналитики в режиме онлайн. В этой статье команда разработки аналитического продукта Data Locker делится опытом оптимизации ETL-приложений Apache Spark для снижения стоимости обработки данных и ускорения вычислений. Предыстория: слишком много файлов в ETL-решении на Spark и AWS S3 в...