
Чтобы добавить в наши практические курсы по Apache Spark еще больше приемов, полезных для дата-инженеров и разработчиков, сегодня рассмотрим, как упаковать PySpark-приложение, используя нативные Python-функции и сторонние решения. Отличия Virtualenv от PEX и Conda. 4 способа упаковать PySpark-приложение для запуска в кластере Apache Spark Разработчики распределенных приложений знают, что недостаточно...
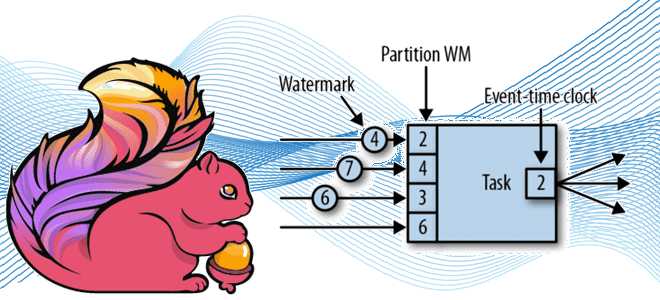
Продолжая разговор про оконные операции в Apache Flink для потоковой аналитики больших данных, сегодня рассмотрим, как это связано с другим важным концептом потоковой обработки событий – водяным знаком. Что такое Watermark и каковы стратегии его генерации в Apache Flink: самое главное для дата-инженера. Потоковая синхронизация данных c SQL для Flink...
Продвигая наш новый курс по графовой аналитике больших данных в бизнес-приложениях, сегодня разберем особенности работы оператора MERGE во встроенном SQL-подобном языке запросов Cypher популярной NoSQL-СУБД Neo4j. Чем он отличается от запросов CREATE и MATCH, а также когда этот оператор более всего полезен. Как работает MERGE-запрос в Neo4j Data Scientist’ы и аналитики данных знают,...
Сегодня заглянем под капот ИТ-инфраструктуры самой знаменитой франшизы быстрого питания. Как устроена унифицированная платформа потоковой обработки событий в McDonald’s на базе облачного полностью управляемого сервиса Apache Kafka в AWS и что гарантирует высокую доступность и надежность решения. Архитектурный дизайн Архитектуры, основанные на событиях, обеспечивают гибкость интеграции, масштабируемость и некоторые возможности...
Продолжая разбираться с популярными MLOps-инструментами, сегодня рассмотрим, как MLflow реализует управление версиями модели и данных, а также чем это отличается от DVC. Преимущества и недостатки популярных MLOps-инструментов с возможностями их совместного использования. Плюсы и минусы MLflow для MLOps-инженера Концепция MLOps, направленная на сокращение разрыва между различными специалистами, участвующими в процессах...

Сегодня рассмотрим пример построения гибридной архитектуры LakeHouse c Apache Kafka и Snowflake, которая гарантирует высокую масштабируемость и обеспечивает безопасность данных от несанкционированного доступа с помощью маскирования. От пакетного озера данных на AWS S3 к потоковому LakeHouse Будучи высоконадежной распределенной платформой потоковой передачи событий, Apache Kafka часто используется для обработки потока...
При том, что большинство современных озер данных представляют собой облачные объектные хранилища типа AWS S3, многие предприятия хранят данные в собственном кластере HDFS или даже MinIO. Поэтому сегодня специально для обучения дата-инженеров и ИТ-архитекторов рассмотрим, что представляет собой это хранилище и насколько хорошо с ним взаимодействует Apache Spark. Что такое...
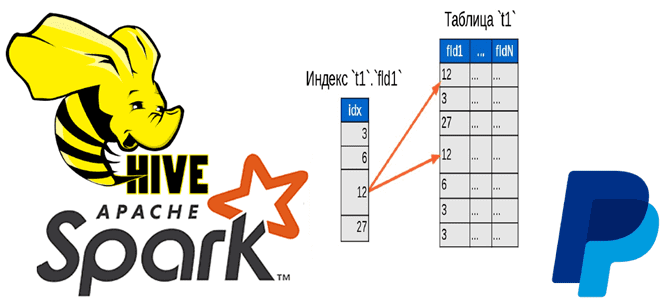
Чтобы добавить в наши курсы по Apache Hadoop и Spark еще больше интересных примеров, сегодня рассмотрим кейс компании PayPal, которой удалось ускорить работу Hive с помощью open-source библиотеки Dione. Зачем индексировать данные в HDFS и как это сделать быстро. Трудности бакетирования в Hive и Spark Вычислительный движок Apache Spark отлично...

Совсем недавно, в самом конце августа 2022 года вышел очередной минорный выпуск Greenplum. Специально для обучения дата-инженеров, ИТ-архитекторов и разработчиков распределенных OLAP-приложений мы подготовили краткий обзор самых важных обновлений и изменений версии 6.21.1. 15 исправлений на сервере Greenplum В отличие от июньского релиза, новинок в этом выпуске немного: добавлено новое...

Хотя Apache HBase обладает массой достоинств, такими как строгая согласованность на уровне строк при больших объемах запросов, гибкая схема, доступ к данным с малой задержкой и интеграция с Hadoop, эта NoSQL-СУБД имеет ряд недостатков: чрезмерная сложность и дороговизна эксплуатации, отсутствие вторичных индексов и ACID-транзакций. Поэтому инженеры фотохостинга Pinterest приняли решение...

Мы уже писали, что технологии Big Data ориентированы на работу с большими данными, а не множеством маленьких. Сегодня рассмотрим подробнее, почему Apache Hadoop, Spark и основанные на HDFS NoSQL-СУБД Hive и HBase плохо работают с большим количеством маленьких файлов, а также как это исправить. Почему HDFS плохо работает со множеством...

Мы регулярно добавляем в наши курсы по Apache Flink и Spark для дата-инженеров полезные материалы и инструменты, которые помогают повысить эффективность разработки и эксплуатации приложений аналитики больших данных. Читайте далее, что такое SeaTunnel и как эта высокопроизводительная платформа интеграции распределенных данных упрощает их потоковую синхронизацию средствами SQL-заданий Apache Flink и...

Чтобы добавить в наши курсы для ИТ-архитекторов и дата-инженеров еще больше практических примеров, сегодня разберем ключевые требования к современному озеру данных и самые последние тренды в аналитике Big Data. Что такое DaaS, зачем это нужно и каковы риски. 7 преимуществ развертывания Data Lake в облаке При том, что Data Lake...

Специально для обучения дата-инженеров и администраторов кластера Apache Kafka, сегодня разберем, как обеспечить безопасность клиента этой распределенной платформы потоковой передачи событий по REST API с помощью возможностей открытого ПО. Что такое PEM-файлы и при чем здесь SSL-сертификаты, а также другие криптографические средства защиты данных: кейс инженеров Expedia Group. Инструменты обеспечения...

В этой статье для дата-инженеров и разработчиков распределенных приложений рассмотрим, что такое динамическое партиционирование таблиц в Apache Spark, зачем это нужно и как реализовать такие вставки разделов. Разбираем на практическом примере. Что такое динамическое партиционирование в Apache Spark Партиционирование – это разделение данных на основе значения столбца и их сохранение...

В отличие от каменных зданий, архитектуры данных постоянно меняются. Сегодня рассмотрим новую архитектурную модель под названием BigLake, выпущенную Google весной 2022 года. Что это такое, как устроено, чем похоже на Lakehouse, озеро данных и Data Mesh, а также чем от них отличается и какую пользу несет для конвейеров аналитики Big...

Недавно мы писали, от каких факторов зависит выбор подходящего MLOps-инструмента. В продолжение этой темы сегодня специально для ML-инженеров разберем сходства и различия двух самых популярных MLOps-решений: что общего у MLflow и Kubeflow, чем они отличаются и в каких случаях выбирать тот или иной инструмент. Краткий обзор 2-х самых популярных MLOps-решений...
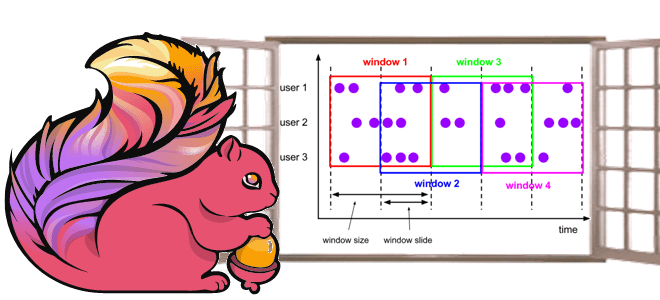
Чтобы сделать наши курсы по Apache Flink для дата-инженеров и разработчиков распределенных приложений еще более полезными, сегодня рассмотрим, как этот фреймворк потоковой аналитики больших данных реализует концепцию оконных функций. Жизненный цикл окна, ключевые понятия и оконные операции Apache Flink, управляемые данными и временем. Что такое окно в потоковой обработке данных...
В рамках продвижения нашего нового курса по графовой аналитике больших данных в бизнес-приложениях, сегодня разберем сложности рефакторинга графовых моделей в Neo4j и способы их обхода с помощью библиотеки APOC и плагина Liquibase. Что такое Liquibase и как Data Scientist и аналитик данных могут использовать его совместно с Neo4j. Гибкость модели данных и трудности...

Как найти компромисс между задержкой, пропускной способностью, долговечностью и доступностью в Apache Kafka: проблемы CAP-теоремы и поиски оптимальной стороны PACELC-ромба. Архитектурные ограничения распределенных систем и лучшие практики для настройки конфигурационных параметров для администратора кластера Apache Kafka и дата-инженера потоковых приложений аналитики больших данных. CAP-теорема и распределенные системы На производительность Apache...