
Сегодня рассмотрим особенности использования оператора LIMIT в Spark SQL: как он выполняется и почему вместо него лучше использовать оператор TABLESAMPLE. Для этого в рамках обучения дата-инженеров, разработчиков распределенных приложений и аналитиков данных заглянем под капот оптимизатора Catalyst в Apache Spark и сравним физические планы выполнения SQL-запросов. Недостатки оператора LIMIT в...

В рамках обучения аналитиков данных, дата-инженеров и разработчиков распределенных приложений, сегодня поговорим про материализованные представления в Apache Hive. Что это такое, зачем нужно и как реализуется в самом популярном NoSQL-хранилище стека SQL-on-Hadoop. Что такое материализованное представление и зачем это надо в аналитике больших данных: краткий ликбез Аналитика данных включает в...

Специально для обучения администраторов кластера Apache Hadoop сегодня рассмотрим, как улучшить производительность распределенной файловой системы. Зачем перемещать файлы на последний узел в кластере, как оптимизировать управление дисками, а также чем полезно централизованное кэширование в HDFS. Оптимизация операций ввода-вывода на жестком диске Преимущества HDFS – распределенной файловой системы Apache Hadoop по...
Чтобы сделать наши курсы для специалистов по Machine Learning еще более интересными, сегодня рассмотрим 5 лучших практик по использованию популярного MLOps-инструмента. Как Data Scientist может работать с MLflow и сделать свои конвейеры машинного обучения еще более эффективными. Компоненты Mlflow для разработки и развертывания ML-систем Сегодня MLOps считается одним из самых...

Недавно мы писали про Lakesoul – новое унифицированное решение для хранения потоковых и пакетных таблиц, которое реализует архитектуру данных LakeHouse. Сегодня заглянем под капот этого унифицированного механизма на базе Apache Spark и разберемся с преимуществами его последнего релиза. Как работает LakeSoul: краткий обзор Напомним, LakeSoul от команды DMetaSoul представляет собой...

Сегодня рассмотрим компоненты и механизмы обеспечения отказоустойчивости Apache HBase. Что делать, когда региональный сервер выходит из строя и как процедура ServerCrashProcedure перераспределяет регионы данных на другие рабочие сервера в кластере Apache HBase. А также разберем, какие параметры конфигурации следует настроить администратору кластера для наиболее эффективного выполнения процессов записи и восстановления...
Недавно мы писали про HTTP-коннектор к Apache Flink от компании GetInData, который позволяет обогатить ML-модель данными из внешней системы с использованием REST API и SQL-концепции Lookup Joins. Как устроен этот коннектор с открытым исходным кодом, и какие методы Flink SQL он использует: разбираем на практическом примере. Что такое HATEOAS: блеск...

Сегодня рассмотрим опыт международной компании Emumba, которая специализируется на инженерии и аналитике больших данных. Читайте далее, как выгодно масштабировать конвейер потоковой передачи данных от миллионов устройств интернета вещей, используя Apache Kafka, KStream и Druid в облачной инфраструктуре AWS. Архитектура PoC для потоковой передачи событий от миллионов IoT-устройств Миллионы устройств интернета...

Продвигая наш новый курс по графовой аналитике больших данных в бизнес-приложениях, сегодня рассмотрим, что такое Nebula Graph и как использовать мощные возможности обработки графов этой NoSQL-СУБД в сочетании с Apache Spark, одним из самых популярных механизмов анализа данных. Что такое Nebula Graph и как это работает Nebula Graph — это...
В этой статье для специалистов по Machine Learning рассмотрим, от каких факторов зависит выбор MLOps-средств и как сделать его наиболее верным способом. Когда развертывание продукта с открытым исходным кодом или индивидуального решения на собственной инфраструктуре лучше готового инструмента в облаке и почему часто бывает наоборот. 3 главных фактора выбора MLOps-решений...

Сегодня рассмотрим новое унифицированное решение для хранения потоковых и пакетных таблиц, созданное на основе Apache Spark. Что такое Lakesoul, чем это лучше Apache Iceberg, Hudi и Deta Lake. Также разберем, в чем конкурентные преимущества этого табличного хранилища по сравнению с этими форматами открытых таблиц, включая поддержку upsert, управление метаданными и...

Постоянно добавляя в наши курсы для дата-инженеров и разработчиков распределенных Spark-приложений интересные примеры, сегодня мы хотим поделиться с вами простыми, но эффективными приемами, как улучшить производительность этого вычислительного движка. Чем метод take() лучше collect() в Apache Spark, какие открытые инструменты помогут выполнить профилирование кода и как быстро прочитать множество маленьких...
Чтобы добавить в наши курсы для дата-инженеров и разработчиков распределенных приложений еще больше практических примеров, сегодня рассмотрим, как написать Python-код для вычисления задержки потребителя Apache Kafka, расширив типовой слушатель StreamingQueryListener, который есть в Java и Scala API библиотеки Spark Structured Streaming, но недоступен в PySpark. Проблема отставания потребителя Apache Kafka...
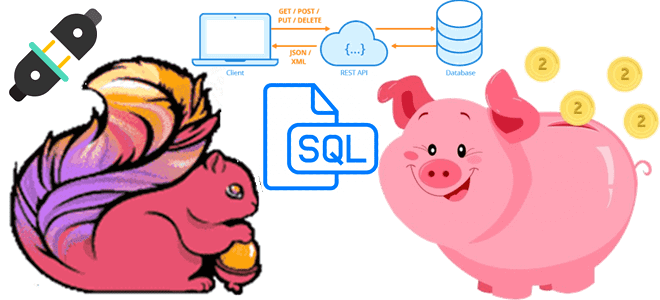
В этой статье для обучения дата-инженеров и разработчиков распределенных приложений рассмотрим, как Flink SQL может обогатить ML-модель данными из внешней системы в режиме реального времени с использованием REST API. Что представляет собой http-flink-connector с открытым исходным кодом, разработанный GetInData на основе концепции Lookup Joins. Обогащение данных c SQL: достоинства использования...
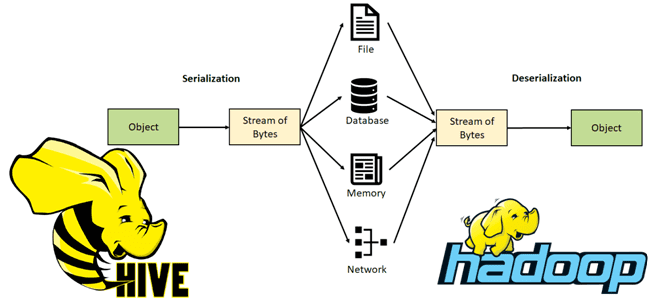
Чтобы добавить еще больше практики в наши курсы для дата-инженеров и разработчиков распределенных приложений, сегодня рассмотрим тонкости сериализации данных в Apache Hive. Читайте далее, как этот популярный SQL-on-Hadoop инструмент обрабатывает данные из HDFS, что такое SerDe и как написать собственный сериализатор/десериализатор. Сериализация и десериализация данных в Apache Hive В настоящее...
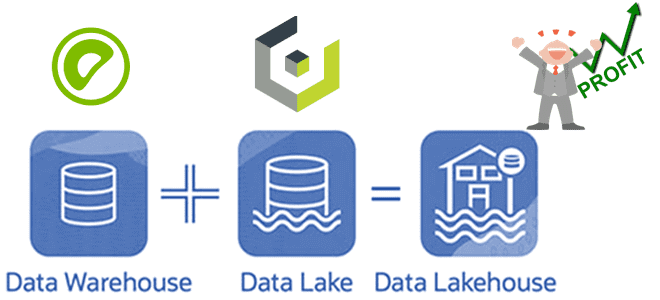
Специально для обучения дата-инженеров и архитекторов DWH сегодня разберем, как построить LakeHouse на Greenplum и объектном хранилище Cloudian HyperStore, совместимом с AWS S3. Что такое Cloudian HyperStore Object Storage, как оно совмещается с Greenplum и при чем здесь Apache Cassandra с интеграционным фреймворком PXF. Что такое объектное хранилище Cloudian HyperStore...

В линейке продуктов Databricks не только облачная платформа аналитики больших данных на базе Apache Spark. В портфолио компании также присутствует популярный MLOps-инструмент под названием MLflow, последний релиз которого (1.27.0) вышел 1 июля 2022 года. Однако, разработчики уже анонсировали в мажорный выпуск новой версии MLOps-фреймворка с открытым исходным кодом. Читайте далее,...

Как Cluster Autotuner от Sync для автонастройки кластера Spark в AWS EMR помог edtech-компании Duolingo снизить затраты на 55%. Полезный сервис для дата-инженера и администратора кластера, чтобы устранить неэффективную ручную настройку, обеспечив оптимальную стоимость, производительность и надежность распределенных вычислений без изменения кода. Дорогой Apache Spark на AWS EMR Duolingo –...
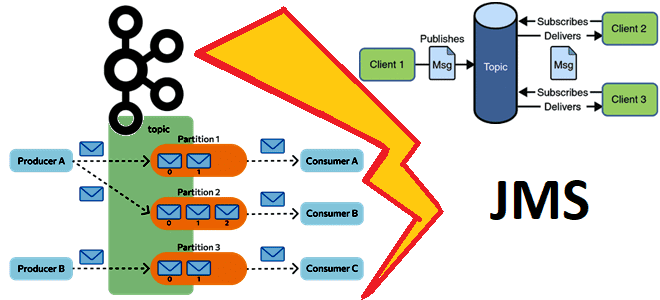
В этой статье для обучения дата-инженеров и разработчиков распределенных систем сравним Apache Kafka с популярными реализациями Java-стандартов обмена сообщениями, к которым относится Apache ActiveMQ, IBM MQ, Rabbit MQ и другие JMS-брокеры. Чем распределенная платформа потоковой передачи событий отличается от JMS-брокеров и что между ними общего. Что такое JMS-брокер Прежде чем...

Сегодня разберем тему, особенно полезную для обучения разработчиков распределенных приложений и дата-инженеров масштабных платформ аналитики больших данных на Apache Flink: обнаружение сложных цепочек связанных событий в потоковой обработке. Как создать свой шаблон поиска сложных событий с библиотекой FlinkCEP. Комплексная обработка событий или зачем вам CEP Современный data-driven бизнес хочет принимать...