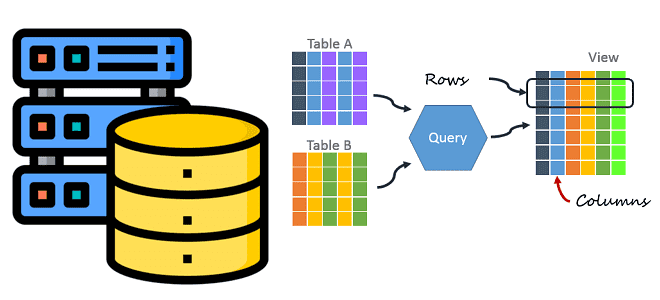
Как данные хранятся на диске при разной ориентации хранилища в СУБД: чем отличаются колоночные базы от строковых с точки зрения практического использования в дата-инженерии. Сравнительная таблица с примерами и выводами. Как данные хранятся на диске и при чем здесь ориентация СУБД Способы хранения данных в СУБД можно разделить на 2...

Что такое Delta Sharing, зачем нужен и как устроен этот открытый стандарт, а также как его использовать для централизованного управления доступом к данным в архитектуре Data Mesh. Что такое Delta Sharing и при чем здесь Data Lake Чтобы упростить обмен большими данными между разными компаниями в режиме реального времени и...

Продолжая разговор про языки запросов к графовым базам данных, сегодня познакомимся с GSQL, который поддерживается в MPP-СУБД TigerGraph. Как работает эта распределенная NoSQL-база данных и каким образом реализует ACID-требования к транзакциям в операциях с графами. Архитектура и принципы работы графовой MPP-СУБД TigerGraph — это распределенное графоориентированное хранилище данных с массивно-параллельной...
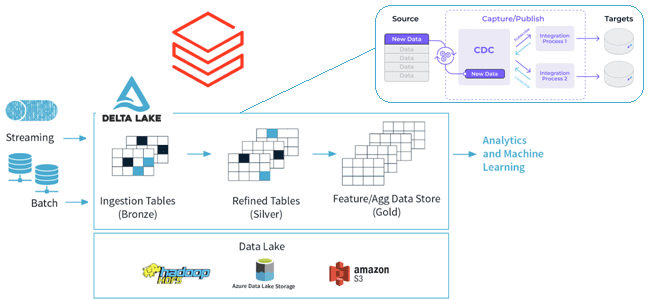
Как реализовать CDC для Delta Lake: разбираемся с функцией Change Data Feed от Databricks, которая позволяет быстро узнать обо всех изменениях строк в дельта-таблицах озера данных. Польза и принципы работы CDF для дата-инженера и архитектора данных. CDC для Delta Lake Идея сбора и обработки не всего объема данных, а только...
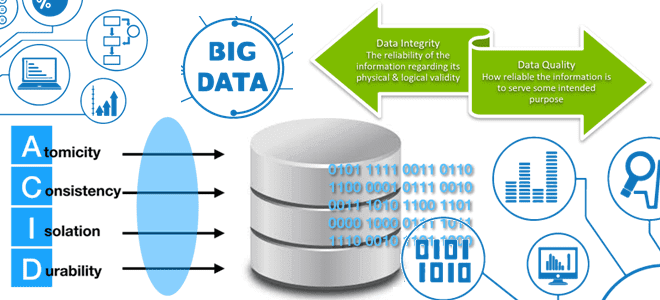
Чем целостность данных отличается от их качества и как реализуются ACID-свойства распределенных транзакций в Big Data системах. Разбираем понятия и технологии, важные для обучения ИТ-архитекторов и дата-инженеров. Целостность и качество данных: versus или вместе? Целостность данных и качество данных — связанные, но разные понятия, важные для дата-инженера. Целостность описывает точность...

Чем задание в Spark-приложениях отличается от задачи, зачем нужны этапы и при чем здесь драйверы с исполнителями. Разбираемся с основами разработки в самом популярном движке для распределенных вычислений: ликбез для дата-инженеров. Основные концепции Spark-приложений Приложение Spark — это программа, созданная с помощью Spark API и работающая в совместимом с этим...
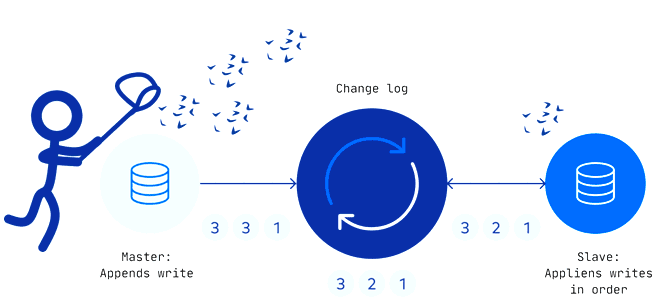
Захват измененных данных считается довольно известным паттерном организации ETL-процессов для корпоративных хранилищ и озер данных. Как реализуется CDC-технология, по каким шаблонам, что их ограничивает и чем опасен дрейф изменений в Change Data Capture. Паттерны и принципы реализации захвата измененных данных Эффективность эксплуатации озера данных зависит от ETL-процессов, поскольку объемы данных...

В этой статье рассмотрим настройку инфраструктуры Kubernetes для потоковой платформы комплексных мобильных приложений на основе Apache Kafka. Что поможет добиться оптимальной масштабируемости приложений-потребителей и высокой доступности всей Big Data системы. Проблемы масштабирования платформы Grab из приложений-потребителей Apache Kafka Grab считается ведущей платформой суперприложений в 8 странах Юго-Восточной Азии, которая предоставляет...
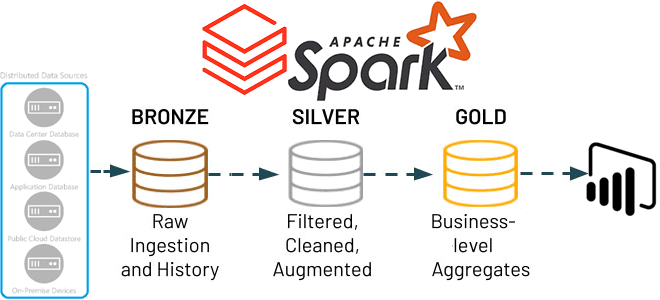
В этой статье для обучения дата-инженеров и ИТ-архитекторов рассмотрим, как Apache Spark Structured Streaming помогает реализовать самообслуживаемый сервис потоковой передачи данных в Delta Lake. А также вспомним каноническую 3-хслойную модель этого уровня хранения от Databricks. Много потоковых сценариев в одном приложении Apache Spark Structured Streaming Мы недавно писали, что архитектуры,...

Зачем корпорации Confluent, которая продвигает Apache Kafka, понадобился Flink-стартап, чего ожидать от очередного слияния поглощения крупным игроком более мелкого предприятия, и какую пользу это принесет экосистеме потоковой передачи событий. Что Immerok и зачем это Confluent Год только начался, а в мире Big Data уже появились интересные новости. 6 января в...
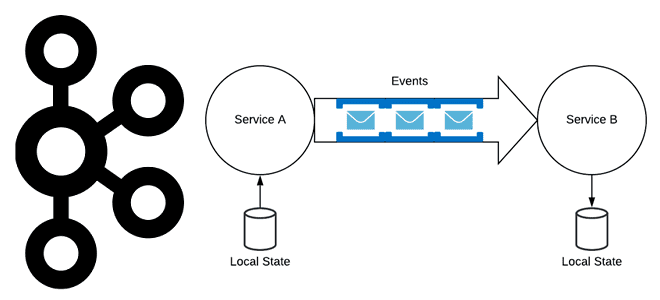
Хотя Apache Kafka часто используется в качестве шины обмена данными в микросервисной архитектуре, о чем мы писали здесь, не стоит воспринимать эту платформу как хранилище событий. В чем разница между событием и сообщением, а также другие тонкости построения микросервисной архитектуры, управляемой событиями. События vs сообщения Событие — это сообщение программной...

Использование СУБД вместо очереди сообщений считается антипаттерном, однако, команда разработки облачной системы организации конвейеров обработки данных Dagster Cloud выбрала PostgreSQL вместо Apache Kafka для регистрации событий. Разбираемся, почему плохой шаблон принес хорошие результаты и что нужно учитывать при выборе технологии. Почему не стоит использовать СУБД вместо очереди сообщений Dagster Cloud...
Недавно мы писали про сравнения технологий потоковой аналитики больших данных и аналитических баз данных реального времени на примере сравнения ksqlDB и Rockset. Продолжая этот разговор про архитектуру данных и приложений, сегодня рассмотрим сходства и отличия потоковых баз данных со stateful-приложениями обработки событий в реальном времени. 2 технологии потоковой обработки: stateful-приложения...
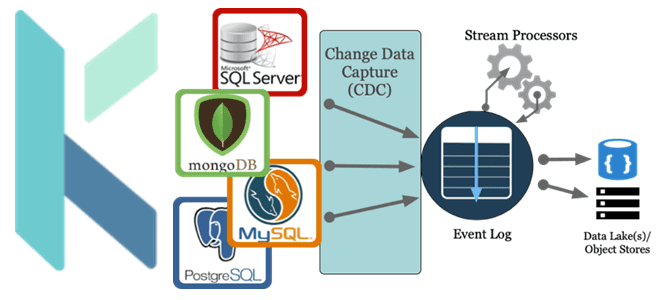
Как реализовать CDC-сценарий, используя платформу оркестрации Kestra вместо Debezium с Kafka Connect для планирования и управления конвейером обработки данных. За счет чего Kestra работает эффективнее Debezium с коннекторами Kafka Connect и при чем здесь Apache AirFlow с NiFi. Что не так с реализацией CDC на Debezium с Kafka Connect Мы...
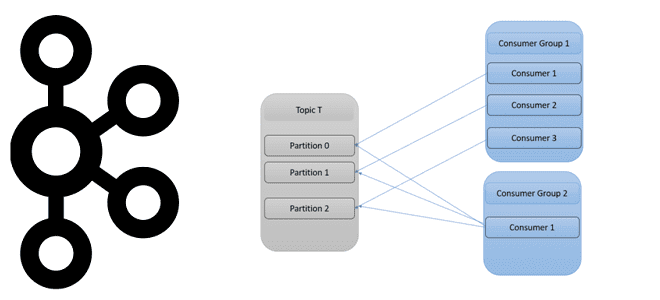
Как количество разделов топика Apache Kafka влияет на потребителей и продюсеров, зачем нужны группы потребителей и как этот механизм реализует идею микросервисной архитектуры Big Data систем. Как работают группы потребителей в Apache Kafka Будучи распределенной платформой потоковой передачи событий, Apache Kafka выполняет роль средства обмена сообщениями между приложениями-продюсерами и приложениями-потребителями...
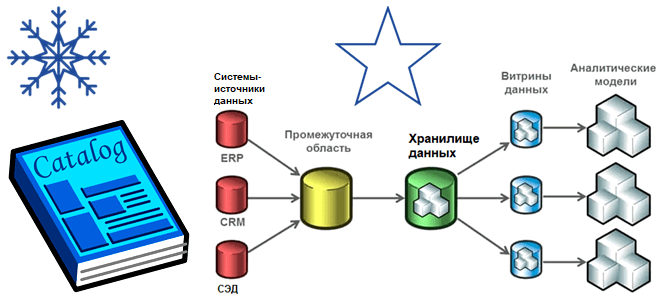
Хотя современная аналитика больших данных чаще базируется на Data Lake, Data Mesh, Delta Lake и DeltaLakeHouse, многие компании до сих пор активно используют классические витрины и хранилища. Разбираем особенности этих архитектур, а также оцениваем их применимость к текущим потребностям бизнеса. Витрины и хранилища данных Витрина данных (Data Mart) предоставляет информацию...
Как использовать мощь Apache Kafka в ИТ-архитектуре корпоративных приложений и интеграции информационных систем: краткий ликбез по ключевым принципам работы этой платформы потоковой передачи событий и важность дата-контрактов для инженера данных, разработчика и архитектора. 9 лучших практик использования Apache Kafka в архитектуре приложений Чтобы успешно применять Apache Kafka в качестве основной...
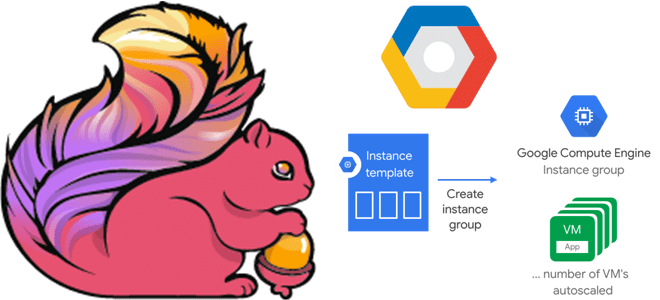
В этой статье для дата-инженеров и разработчиков Flink-приложений рассмотрим, как связаны диспетчеры задач и заданий, зачем настраивать автоматическое масштабирование кластера и как это сделать с помощью Google Auto Scaler в облачной инфраструктуре этого провайдера. Роль диспетчера заданий в Apache Flink и механизмы отказоустойчивости Apache Flink — отличный фреймворк создания приложений...

Сегодня поговорим про основные программные компоненты и принципы работы Apache AirFlow: как DAG состоит из задач, в чем разница между операторами и датчиками, зачем нужны правила триггеров, а также каким образом фреймворк защищает переменные. DAG и задачи: зависимости, состояния, триггеры Основной концепцией Apache AirFlow является DAG – направленный ациклический граф,...

Чтобы добавить в наши курсы по аналитики больших данных еще больше практически примеров, сегодня рассмотрим, как современные технологий Big Data помогают в реальном времени выявлять телекоммуникационные мошенничества. Почему для антифрод-задач особенно подходит Apache Flink с его потоковом движком обработки данных и за счет чего этот фреймворк такой быстрый. Антифрод в...