 1144
1144 
Содержание
Продолжая разговор про расширенную аналитику больших данных с помощью инструментов Big Data и методов Data Science, сегодня рассмотрим, что такое самообслуживаемое машинное обучение, а также разберем, чем self-service Machine Learning отличается от AutoML.
Что такое самообслуживаемое машинное обучение
В июне 2020 года аналитическое агентство Gartner опубликовало очередной список самых перспективных трендов в области аналитики данных. Первое место в этой десятке топовых технологий занимает умный, быстрый и ответственный искусственный интеллект (ИИ), включая прозрачные датасеты и легко интерпретируемые алгоритмы машинного обучения. Анализируя другие тренды из этого исследования, можно сделать вывод об общей тенденции к повышению уровня демократизации технологий Big Data и Data Science, таких как расширенное управление данными, публичные облака, интеллектуальное принятие решений и аналитический подход к использованию информации [1].
Таким образом, по аналогии с самообслуживаемыми BI-сервисами, о которых мы рассказывали здесь, появляется потребность в self-service Machine Learning (ML), включая повышение прозрачности и автоматизации всех процессов машинного обучения, от подготовки данных до интерпретации результатов моделирования [2].
На первый взгляд, эта концепция не отличается от идеи автоматического машинного обучения (AutoML) с помощью специальных библиотек и готовых решений, таких как Google AutoML, Auto Keras, RECIPE, TransmogrifAI, Auto-WEKA, H2O AutoML и прочие фреймворков для автоматического конструирования признаков, оптимизации гиперпараметров, поиска наилучшей архитектуры, подбора каналов и оценочных метрик, определения ошибок и выполнения других ML-процедур [3]. Однако, self-service ML представляет собой нечто большее, чем просто упакованные для широкого использования Data Science инструменты. Что общего между самообслуживаемым Machine Learning и AutoML, чем различаются эти понятия и при чем здесь технологии Big Data, мы рассмотрим далее.
Чем Self-service Machine Learning отличается от AutoML
В очередном отчете исследовательского агентства Gartner, посвященному топовым технологиям ИИ, в 2019 году автоматическое машинное обучение располагалось на пике завышенных ожиданий в цикле зрелости технологий (Hype Cycle), о котором мы писали здесь. К этому привела повсеместная популяризация технологий Big Data и Data Science, в частности, методов Machine Learning [4].
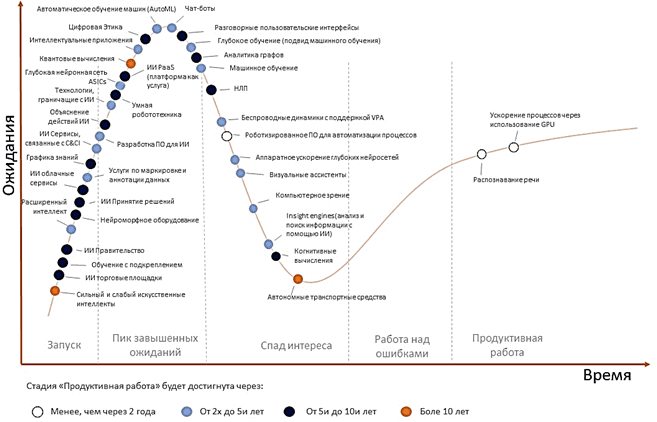
Главная идея AutoML состоит демократизации ИИ, чтобы прогнозирование будущих событий и анализ накопленных данных был доступен не только опытным Data Scientist’ам, а всем бизнес-пользователям без специальных профессиональных компетенций. Средства AutoML нацелены на максимальное упрощение процессов создания и применения прикладных ML-алгоритмов с помощью наглядных пользовательских интерфейсов. Скрывая за GUI сложную программно-математическую базу, они позволяют пользователю быстро создавать собственные модели, автоматизируя этапы подготовки данных и проверки качества вычислений. Разумеется, часть работы остается за пользователем, например, предварительная подготовка данных с помощью расстановки идентифицирующих меток или определения нужной выборки. Например, помимо вышеупомянутых AutoML-библиотек, это реализовано в облачных сервисах Microsoft Azure ML, Google Cloud AutoML и Amazon SageMaker. Таким образом, локальные или облачные инструменты AutoML расширяют возможности простого пользователя и облегчают работу Data Scientist’а, позволяя ему сфокусироваться на бизнес-задаче, а не на проблемах обработки данных [3].
Однако, автоматизация части Data Science задач за счет AutoML не покрывает весь спектр работ по анализу данных с помощью ИИ. В частности, остается открытым вопрос сбора информационных массивов из различных источников, их трансформации и передачи результатов ML-моделирования в BI-системы. Именно это и предполагает концепция самообслуживаемого машинного обучения, когда автоматизируются не только локальные задачи Data Scientist’a и аналитика данных, а также инженера и разработчика Big Data решений. Перечислим основные практические направления, где self-service Machine Learning приносит комплексную пользу бизнесу [2]:
- cоздание и повторное использование интеграционных конвейеров обработки больших данных (data pipelines);
- замена процессов кодирования на Python, Java или другом языке программирования операциями пользовательского интерфейса;
- снижение нагрузки на инженеров данных, разработчиков Big Data решений и DevOps за счет исключения дополнительных этапов развертывания ML-моделей на тестовых серверах благодаря инкапсуляции всех процессов работы с данными;
- автоматизация рутинных задач с низкой стоимостью, таких как очистка данных, чтобы высвободить время, энергию и ресурсы для аналитика Big Data и Data Scientist’a для более важной деятельности;
- сокращение срока выхода Data Science продукта на рынок за счет исключения этапа перевода обученной и протестированной ML-модели в production-версию. Обычно, разработчик Big Data или DevOps-инженер переводит результаты труда Data Scientist’а на другой язык программирования, например, с Python на Java, чтобы синхронизировать ее со всей корпоративной инфраструктурой. Self-service Machine Learning позволяет развернуть готовую ML-модель как API без промежуточных перекодировок и трудоемких настроек.
- организация непрерывного обучения и повторного развертывания ML-модели с помощью ранее построенных data pipeline’ов, автоматизированных процедур подготовки данных и запуска готовых алгоритмов в production.
- расширение области действия моделей Machine Learning за счет унификации и демократизации процедур подготовки данных, а также разработки и эксплуатации ML-приложений.
- интеграция технологий Big Data и Data Science на одной платформе, что повышает производительность приложений, эффективность труда и синергию комплексного анализа данных. Например, когда корпоративное Data Warehouse интегрировано с озером данных на базе Apache Hadoop, куда стекаются потоки и пакеты информации из различных источников согласно ETL/ELT-процессам, выстроенных с помощью Apache NiFi, Airflow и аналогичных фреймворков. Подобным образом Self-service ML предполагает наличие других data pipeline’ов, например, с использование Apache Kafka для агрегации потоковых данных, а также Spark или подобных инструментов для их анализа. Практический кейс подобной Big Data системы мы недавно рассматривали здесь, на примере интеллектуального озера данных у аптечного агрегатора АСНА.
Таким образом, можно сделать вывод, что AutoML – это часть Self-service Machine Learning, а в целом самообслуживаемое машинное обучение представляет собой плотное взаимодействие технологий Big Data с методами Data Science. Это отлично укладывается в концепцию цифровой трансформации, поддерживая идею комплексной интеграции данных, процессов и технологий.
Как на практике организовать Self-service Machine Learning для анализа больших данных в проектах цифровизации своего бизнеса, вы узнаете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники
- https://www.gartner.com/smarterwithgartner/gartner-top-10-trends-in-data-and-analytics-for-2020/
- https://dzone.com/articles/the-eight-essential-traits-of-self-service-machine
- https://chernobrovov.ru/articles/mesto-nejrosetej-v-data-science-kratkij-likbez-i-poslednie-trendy/
- https://www.gartner.com/smarterwithgartner/top-trends-on-the-gartner-hype-cycle-for-artificial-intelligence-2019/

