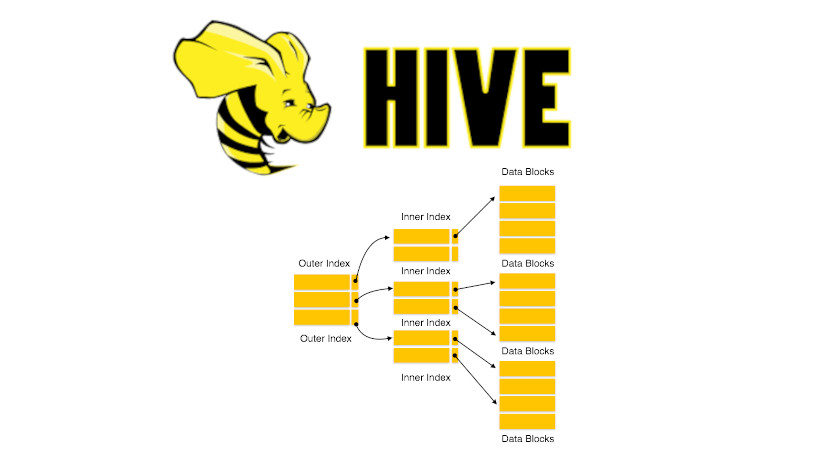
В прошлый раз мы говорили про драйвер JDBC и его использование в Hive. Сегодня поговорим про особенности создания и работы индекса в распределенной Big Data платформе Apache Hive. Читайте далее про особенности работы с индексами в распределенной среде Big Data СУБД Hive. Какую роль играет использование индекса при обработке Big...

В этой статье мы поговорим про функции группировки и сортировки в распределенной СУБД Apache Impala. Читайте далее про особенности работы механизма группировки и сортировки Big Data, которые позволяют Impala-разработчику обрабатывать большие массивы данных любых типов с минимальными временными затратами. Как работает механизм группировки и сортировки данных: особенности обработки Big Data...

В прошлый раз мы говорили про особенности работы и создания представлений в Impala. Сегодня поговорим про модифицированный вывод в распределенной SQL-платформе Apache Impala. Читайте далее про особенности модификации вывода записей в Impala, включая базовые операторы, которые применяются для вывода конкретных записей. Базовые SQL-операторы для модификации вывода записей в распределенной СУБД...

В прошлый раз мы говорили про особенности работы с основными join-операциями в Hive. Сегодня поговорим про использование JDBC-драйвера при работе в распределенной Big Data платформе Apache Hive. Читайте далее про особенности использования этого драйвера при работе в распределенной среде Hive. Использование драйвера JDBC в распределенной СУБД Apache Hive Драйвер JDBC...

В прошлый раз мы говорили про особенности работы с базовыми CRUD-операциями в Hive. Сегодня поговорим про основные join-операции в распределенной Big Data платформе Apache Hive. Также рассмотрим применение этих операций к данным, хранящимся в этой СУБД. Читайте далее про особенности работы с join-операциями в распределенной СУБД Apache Hive. Join-операции в...

В прошлый раз мы говорили про особенности работы с пользовательскими функциями (UDF) в Hive. Сегодня поговорим про основные SQL-операции в распределенной Big Data платформе Apache Hive. Также рассмотрим применение этих операций к данным, хранящимся в этой СУБД. Читайте далее про CRUD-операции в Hive и их особенности. CRUD-операции в СУБД Apache...

В этой статье мы поговорим про основные базовые операции в МонгоДБ. Также рассмотрим применение этих операций к данным, хранящимся в этой СУБД на практических примерах. Читайте далее про базовые CRUD-операции в MongoDB и их особенности. Основные операции СУБД MongoDB Прежде всего отметим, что MongoDB - это документно-ориентированная (данные хранятся в...

В этой статье мы поговорим про работу с представлениями в Apache Impala. Также рассмотрим структуру представлений в этой SQL-подобной распределенной СУБД, входящей в экосистему Hadoop. Читайте далее про особенности работы с представлениями в Impala, которые делают эту СУБД весьма удобным и мощным средством хранения и обработки Big Data. Как работает...

В прошлый раз мы говорили про виды таблиц для быстрой работы с Big Data в Apache Hive. Сегодня поговорим про создание пользовательских функций и их применение в Hive. Читайте далее про особенности создания и применения UDF для работы с Big Data в распределенной платформе Apache Hive. Что такое пользовательские функции...

В прошлой статье мы рассматривали архитектуру Apache Hive и ее основные элементы. Сегодня поговорим про основные виды таблиц в Hive. Также подробно рассмотрим создание этих таблиц на практических примерах. Читайте далее про виды таблиц в Hive и их особенности. 2 основных вида таблиц для быстрой работы с большими данными в...

В этой статье мы поговорим про структуру системы управления базами данных (СУБД) Apache Hive. Также рассмотрим, какие базовые компоненты входят в структуру известной SQL-подобной СУБД, входящей в экосистему Hadoop. Читайте далее про основные компоненты структуры Apache Hive, которые делают эту СУБД весьма удобным и мощным средством хранения и обработки больших...