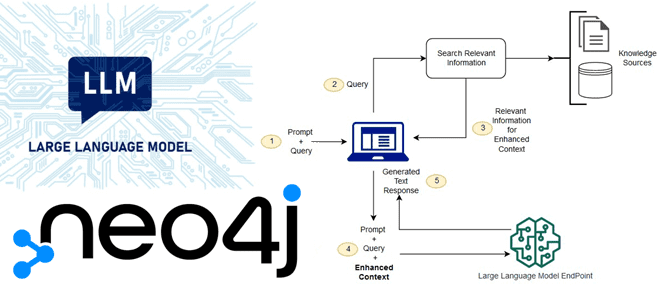
Что не так с большими языковыми моделями, как RAG-приложения расширяют возможности LLM и зачем в графовой СУБД Neo4j добавлена поддержка векторного индекса. Зачем нужны RAG-приложения: ограничения базовых LLM-сетей С появлением ChatGPT и других генеративных нейросетей, большие языковые модели (LLM, Large Language Models) стали активно применяться для решения множества бизнес-задач, связанных...

Как организовать миграцию схемы Neo4j и импортировать в графовую базу данные из реляционных систем. Знакомимся с инструментами проекта Neo4j Labs: Neo4j-ETL и Neo4j-Migrations. Как работает Neo4j-ETL В рамках развития своих продуктов, таких как графовая СУБД Neo4j и экосистема элементов вокруг нее (Graph Data Science, Neo4j Bloom, Neo4j Browser и пр.),...
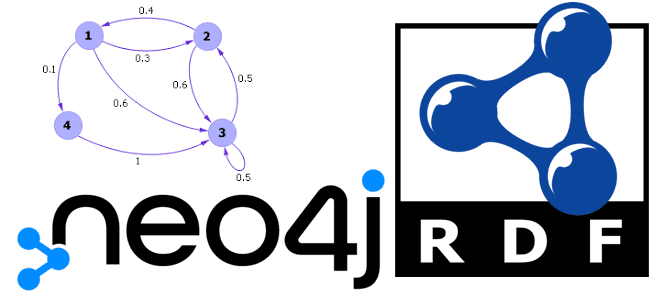
Что такое триплеты, чем они отличаются от обычных графов свойств и где используются на практике. Знакомимся с RDF и возможностями графовой СУБД Neo4j работать с этой структурой описания веб-ресурсов с помощью плагина Neosemantics. Что такое триплеты и при чем здесь RDF Триплеты (triples) — это текстовый формат, используемый для хранения...
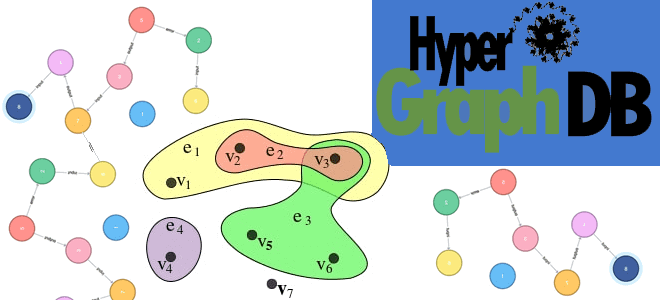
Чем гиперграфы отличаются от обычных графов знаний, где они используются на практике и как эта математическая концепция поддерживается в NoSQL-СУБД HyperGraphDB. Что такое гиперграф Гиперграф — это графовая модель данных, в которой отношения (гиперребра) могут соединять любое количество заданных узлов. Можно сказать, что это обобщение графа, в котором каждым ребром...
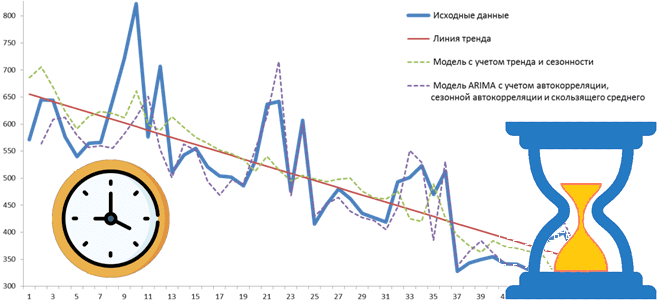
Чем базы данных временных рядов отличаются от реляционных и key-value хранилищ, какова модель данных для хранения метрик, значения которых меняются во времени, какие решения этой категории NoSQL-СУБД сегодня популярны на рынке и для чего они используются. Что такое база данных временных рядов и где она используется Как и следует из...
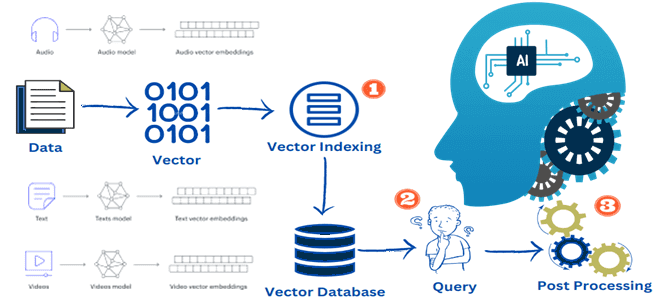
Как устроены векторные базы данных и почему они стали так популярны с распространением ИИ. Архитектура, алгоритмы, принципы работы и примеры векторных СУБД. Что такое векторная СУБД и при чем здесь ИИ Как и следует из названия, векторная база хранит данные в виде векторов. Это понятие из математики означает специализированное представление...
Как включить отрицательные веса в поиск пути, выявлять центральные и периферийные кластеры на основе заданной плотности, а также делать выборки из больших графов для масштабирования машинного обучения. Знакомимся с графовыми алгоритмами, недавно добавленными в библиотеку Neo4j Graph Data Science 2.4: декомпозиция K-ядра, алгоритм кратчайшего пути Беллмана-Форда и случайное блуждание с...
Как устроены по-настоящему мультимодельные базы данных, чем они отличаются от реляционных и NoSQL-СУБД, а также какова истинная природа универсального подхода к хранению и оперированию данными. Разбираемся на примере ArangoDB, OrientDB и Cosmos DB. Что такое мультимодельная СУБД и зачем она нужна Любая технология предназначена, прежде всего, для решения конкретных проблем,...
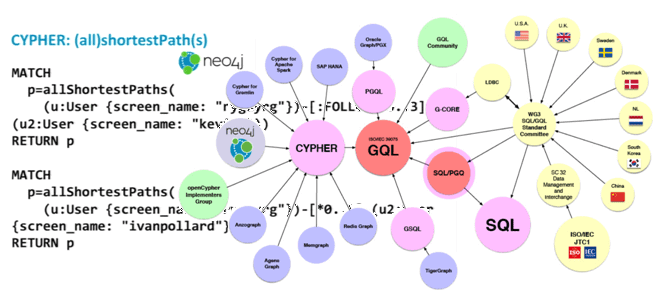
Кто и зачем создает аналог SQL для запросов к графовым базам данных, когда выйдет официальная версия стандарт и при чем здесь Cypher из Neo4j. Что такое GQL и кто его разрабатывает В рамках продвижения нашего курса по графовым алгоритмам в бизнес-приложениях мы часто рассказываем про инструменты хранения и анализа графовых...

Зачем биомедикам понадобился свой язык описания онтологий, как эти задачи решает BioCypher и при чем здесь Neo4j: практическое приложение Data Science и графовых алгоритмов в биомедицинской сфере. Что такое BioCypher Графовые алгоритмы активно применяются в биомедицине для анализа различных биологических данных, таких как геномные, протеомные, данные о белковых взаимодействиях и...

Сегодня заглянем внутрь Neo4j, чтобы разобраться с базовыми концепциями этой графовой базы данных. Какие уровни изоляции транзакций поддерживаются в Neo4j, почему одна установка по умолчанию содержит две базы данных, что такое составная БД и как с этим работать. Транзакции в Neo4j Neo4j — это популярная нативная графовая СУБД, способная управлять...
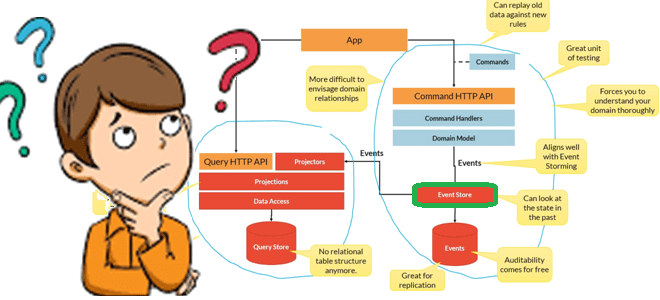
Что представляет собой паттерн проектирования микросервисов под названием источник событий (Event Sourcing) и как его реализовать в реляционных базах данных и NoSQL-системах. Разбираемся с архитектурой данных и архитектурой ПО на практических примерах. Архитектурный шаблон Event Sourcing Многие архитектурные шаблоны рассматривают сущности (entity) как основную концепцию, описывая способы их сохранения и...
Что такое безиндексная смежность и как она снижает сложность алгоритмов обхода графа, позволяя быстро и эффективно запрашивать множество узлов и отношений. Разбираемся с уникальными принципами работы графовых баз данных на примере Neo4j. Архитектура и принципы работы графовых баз данных Несмотря на стремление разработчиков современных СУБД к унификации их решений, первичная...
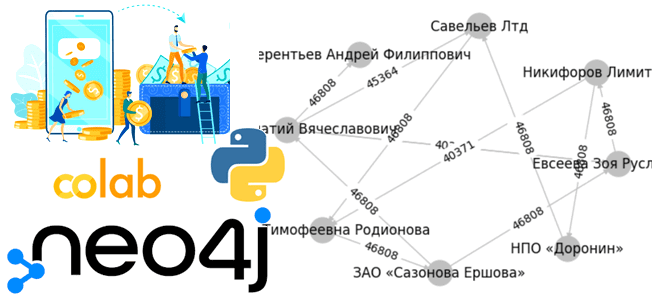
Чтобы показать еще один вариант использования графовой базы данных Neo4j, сегодня реализуем небольшое Python-приложение, которое генерирует граф знаний в облачной платформе Aura DB. Ищем финансовые переводы между компаниями и физическими лицами, считаем общую сумму и визуализируем найденные транзакции с помощью библиотеки Networkx. Python-приложение для работы с Neo4j в AuraDB Как...
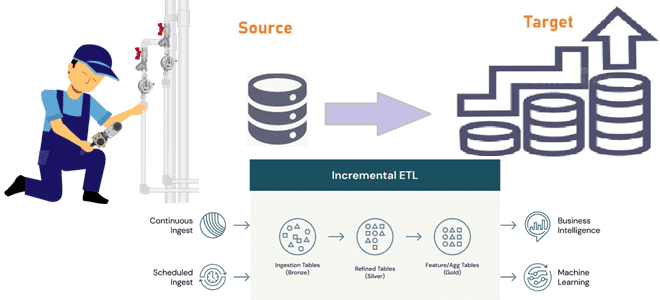
Инкрементные конвейеры загрузки больших объемов данных в корпоративное хранилище или озеро как самый экономичный способ масштабирования архитектуры данных. Разбираемся, как дата-инженеру эффективно организовать такие ETL-конвейеры. 2 способа организации конвейеров инкрементной загрузки данных Инкрементный ETL (Extract, Transform and Load) для классического DWH стал обычным явлением с источниками CDC (сбор данных об...
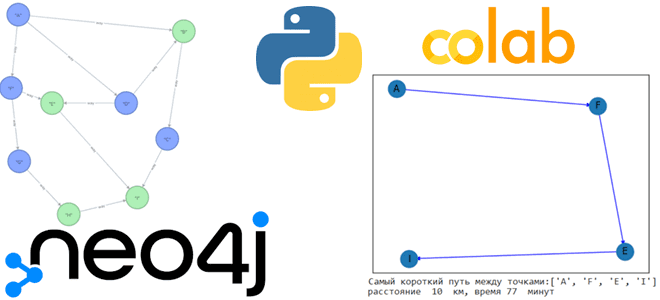
Сегодня решим логистическую задачу поиска кратчайшего пути, создав граф знаний в Neo4j, развернутой в облачной платформе Aura DB и визуализируем найденный путь с помощью Python-библиотеки Networkx. Работа с Neo4j в AuraDB В прошлой статье мы упоминали, что для работы с популярной графовой СУБД Neo4j совсем необязательно устанавливать ее локально. Можно...
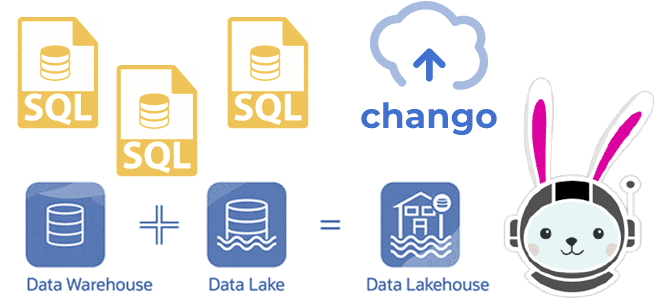
Как реализовать гибридную архитектуру данных Lakehouse на новой платформе Chango с движком обработки распределенных запросов Trino без дополнительного развертывания кластера Kafka и разработки Spark-приложений потоковой передачи событий. Что такое Trino: принципы работы распределенного SQL-движка О том, что представляет собой новая гибридная архитектура данных под названием Lakehouse, мы подробно писали здесь,...

Что такое потоковая аналитика больших данных, какие бывают СУБД потоковой передачи, когда и зачем их использовать, а также что влияет на выбор этих инструментов хранения и аналитической обработки Big Data. Что такое потоковые базы данных и как они работают Мы уже упоминали, что аналитика данных в реальном времени может быть...
Недавно мы писали про резидентную графовую СУБД Memgraph, которая хранит данные в оперативной памяти. Сегодня рассмотрим, как выгрузить граф знаний из Memgraph на диск с помощью библиотеки GQLAlchemy, а также поговорим про персистентность другого популярного NoSQL-хранилища Redis, которое также является резидентным, но относится к семейству key-value. Как сохранить данные из...
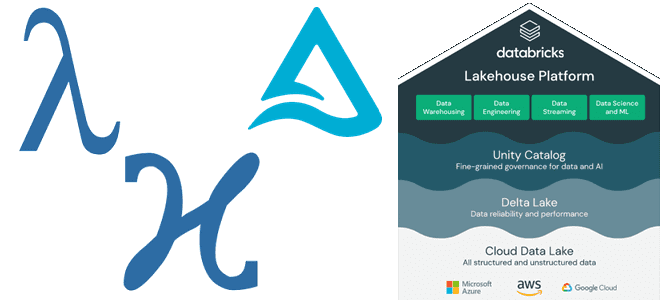
Как Lakehouse объединяет пакетную и потоковую обработку, какие проблемы возникают при реализации этой гибридной архитектуры данных и каким образом они решаются с помощью Delta-подхода и Apache Spark Structured Streaming. Краткая история появления дельта-архитектуры от лямбда- и каппа-моделей Мир больших данных постоянно развивается: появляются новые технологии и архитектурные шаблоны. В частности,...