Как Apache Kafka обеспечивает упорядоченность сообщений в рамках раздела, где хранятся смещения потребителей и зачем их фиксировать вместе со эпохой брокера-лидера.
Что такое смещения потребителей Apache Kafka и где они хранятся
Асинхронная интеграция между информационными системами через Apache Kafka основана на смещениях потребителей – позиции сообщения в разделе топика. Раздел является единицей параллелизма и представляет собой каталог файлов журналов. Раздел должен полностью помещаться на одной машине. Поэтому дл масштабирования скорости записи и потребления данных необходимо несколько разделов. Данные в каждом разделе упорядочены (в рамках раздела) и потребляются не более чем одним потоком/процессом потребителя в каждой группе потребителей. Такой однопоточный режим гарантирует хронологический порядок потребления сообщений в пределах раздела.
Один процесс может потреблять из нескольких разделов, т.е. количество разделов ограничено максимальным параллелизмом потребителя. Поэтому больше разделов означает больше лог-файлов, что может привести к меньшим объемам записи, если памяти недостаточно для буферизации записей и объединения их в более крупные пакеты. При использовании ZooKeeper каждый раздел соответствует нескольким Znodes в ZooKeeper. ZooKeeper хранит все в памяти, что может привести к OOM-ошибке (out Of Memory, нехватка памяти). Поскольку за каждым разделом закреплен свой лидер, куда публикуются сообщения с продюсера, много разделов означает большее время переключения лидера. Начиная с версии 2.3 потребители могут потреблять данные из ближайшей реплики вместо лидера раздела, снижая затраты на передачу данных в зоне перекрестной доступности. За это отвечает свойство конфигурации client.rack на клиенте, значение которого должно соответствовать значению свойства broker.rack на брокере в той же зоне доступности.
Задержка обработки данных в Kafka относится к разнице между последним смещением раздела и текущим смещением группы потребителей. По сути, она измеряет, насколько сильно отстает потребитель в обработке опубликованных в топике сообщений. Kafka обеспечивает репликацию и отказоустойчивость хранения данных о смещениях, гарантируя надежность и консистентность при перезапуске потребителей и обработке сбоев.
При создании контрольной точки позиции потребителя сохраняется одно смещение на раздел, поэтому чем больше разделов, тем дороже становится контрольная точка позиции. По сути, смещение потребителя – это последовательный идентификационный номер, назначаемый каждому сообщению. Потребитель использует смещения для отслеживания прогресса чтения данных из раздела топика Kafka. Когда потребитель читает сообщение, он получает сообщение вместе со смещением и затем может зафиксировать следующее смещение, чтобы указать, что каждая предыдущая запись с меньшим смещением была успешно обработана. Например, если сообщение со смещением 25 прочитано, то смещение 26 будет зафиксировано. Зафиксированное смещение относится к следующему смещению, которое потребитель намеревается прочитать, а не к смещению последнего успешно обработанного сообщения. Это зафиксированное смещение затем используется для возобновления потребления с правильной позиции в случае перезапуска потребителя или перебалансировки в группе потребителей. Зафиксированные смещения хранятся во внутреннем топике Kafka под названием __consumer_offsets. Этот топик создается автоматически при запуске Kafka и используется для хранения текущей позиции чтения потребителя в каждом разделе топика. Впрочем, Kafka позволяет использовать внешние хранилища для смещений. Например, потребитель может явно сохранять смещения в сторонней базе данных, такой как Redis, PostgreSQL или Zookeeper. Однако, в большинстве случаев смещения хранятся в самой Kafka в топике __consumer_offsets, поскольку это наиболее простой и надежный подход.
Как фиксируются и обрабатываются смещения потребителей
Чтобы повысить свою пропускную способность, потребитель не фиксирует каждое смещение по умолчанию, т.к. операция фиксации включает запрос к брокеру. По умолчанию включена политика автоматической фиксации, которая периодически фиксирует смещения с заданным интервалом. Этот интервал контролируется свойством auto.commit.interval.ms, которое по умолчанию равно 5000 миллисекунд (5 секунд). Эту автоматическую фиксацию можно отключить, установив свойство enable.auto.commit в значение false. Когда автоматическая фиксация отключена, код приложения должен вручную фиксировать смещения с помощью API фиксации потребителя. Это можно сделать синхронно или асинхронно, в зависимости от требований приложения.
Kafka стремится к обеспечению семантики exactly-once, когда данные обрабатываются без потерь или дублирования, сохраняя согласованность и точность. Транзакции Kafka допускают атомарную запись в несколько разделов, гарантируя, что либо все сообщения в транзакции будут успешно записаны, либо ни одно. Для этого Kafka использует контрольные записи окончания транзакций, чтобы указать, что все сообщения в транзакции будут либо полностью зафиксированы, либо отменены. Управляющие записи также продвигают смещение, как и записи данных, хотя они не видны напрямую приложениям. Эти управляющие записи записываются в те же журналы данных, что и обычные записи, обеспечивая бесшовную интеграцию транзакционных метаданных с потоком сообщений.
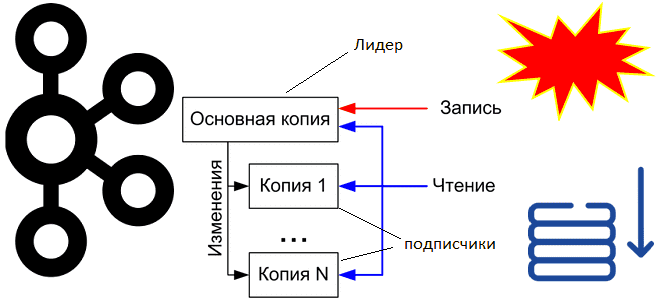
У каждого раздела топика Kafka есть назначенный лидер – брокер, ответственный за обработку всех чтений и записей для этого раздела. Продюсер публикует сообщение в раздел, размещенный на лидере, откуда оно реплицируется по подписчикам для отказоустойчивости. При сбое лидера один из брокеров-подписчиков, синхронизированный с ним, выбирается в качестве нового лидера, чтобы обеспечить доступность раздела. Как это происходит, мы разбирали здесь. Обычно Kafka автоматически переназначает лидера раздела, выполняя процедуру leader election на основе набора синхронизированных реплик (ISR, In-Sync Replicas). Можно также назначить лидера вручную, используя команду kafka-topics.sh с параметрами –alter –partitions для ручного переназначения разделов.
Когда выбирается новый лидер, он увеличивает эпоху – монотонно увеличивающееся число, непрерывный период лидерства для одного раздела. Это позволяет всем подписчикам идентифицировать последнего лидера и синхронизировать свои логи с ним. Потребитель может зафиксировать эпоху лидера вместе со смещением, чтобы обеспечить согласованность и точность в управлении смещением. Эпоха лидера также хранится в топике __consumer_offsets, помогая определить правильного лидера раздела на момент фиксации смещения. Это особенно важно во время смены лидера и перебалансировки группы потребителей.
Когда лидер раздела меняется (из-за сбоя брокера, перезапуска брокера или ручного переназначения), брокер Kafka обновляет метаданные, чтобы отразить нового лидера для затронутых разделов. Потребители в группе потребителей полагаются на эти метаданные, чтобы узнать, к какому брокеру обратиться для получения данных. При обнаружении смены лидера потребители получат ошибку LEADER_NOT_AVAILABLE или NOT_LEADER_FOR_PARTITION при попытке получить данные от старого лидера. В этом случае потребители должны обновить свои метаданные, связавшись с брокерами Kafka, чтобы получить обновленную информацию о новом лидере. Этот процесс помогает поддерживать доступность данных и гарантирует, что потребители перенаправят свои запросы в правильный раздел топика, размещенный на брокере-лидере.
Однако, иногда потребители могут не знать о необходимости обновления своих метаданных. Например, после перебалансировки группы потребителей раздел топика переназначается другому потребителю. Но из-за задержек в сети или проблем с распространением метаданных этот потребитель не обновлял свои метаданные после перебалансировки, а сохраняет устаревшую эпоху лидера для этого раздела. Бывший лидер раздела, который продолжает работать и пытается выполнять свои обязанности, несмотря на потерю статуса лидера из-за сетевых проблем, принимает запрос на выборку от потребителя и отвечает ошибкой OFFSET_OUT_OF_RANGE, поскольку он не получил никаких новых сообщений от продюсера.
Поэтому потребитель должен знать текущую эпоху лидера вместе со смещением, которое ему нужно получить, чтобы вовремя обнаружить устаревание своих метаданных, и обновить их. Это делает фиксацию эпохи лидера вместе со следующим смещением необходимой и полезной. Когда потребитель фиксирует смещение вместе со своей эпохой лидера, это помогает другим потребителям в группе распознавать и игнорировать устаревшие метаданные. Когда все потребители в группе следуют этой практике, потребитель с устаревшими метаданными может использовать зафиксированную эпоху лидера в качестве ссылки для запуска обновления метаданных, предотвращая потребление данных из устаревшего лидера.
На UML-диаграмме последовательности это выглядит так:
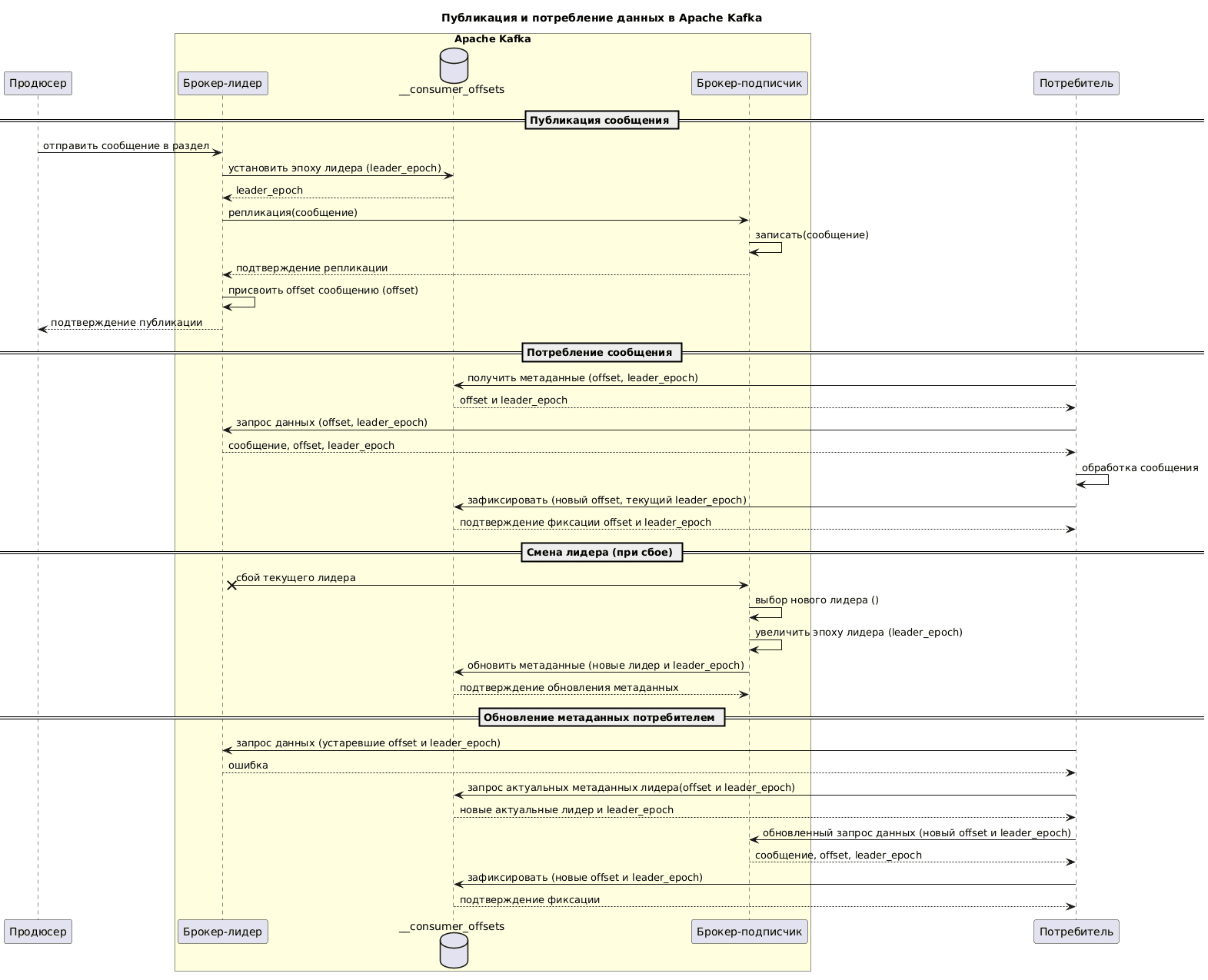
Как уже было отмечено выше, иногда необходимо вручную фиксировать определенные смещения. Как это сделать, какие при этом могут возникнуть проблемы и как их решить, рассмотрим в следующий раз.
Научитесь администрированию и эксплуатации Apache Kafka на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники

