 764
764 
Содержание
Что такое код верхнего уровня в Apache AirFlow, почему его следует избегать и как это сделать: шаблонные переменные, динамическое сопоставление задач, Python-функции и библиотеки для кэширования. А также 3 нативных способа создания перекрестных зависимостей между DAG для их запуска: TriggerDagRunOperator, ExternalTaskSensor и SimpleHttpOperator.
Что такое код верхнего уровня в Apache AirFlow, почему его следует избегать и как это сделать
Наиболее важными для дата-инженера преимуществами Apache AirFlow можно назвать его гибкость и относительную простоту использования. Используя широко распространенный язык программирования Python, можно написать собственный оператор для выполнения любой задачи во всем конвейере, который называется DAG (Directed Acyclic Graph) и представляет собой направленный ациклический графы. Каждая задача в DAG — это единица работы, например извлечение данных из источника, их преобразование и загрузка в место назначения. Цепочка задач образует конвейер обработки данных, а зависимости между ними могут определять порядок их выполнения.
Однако, при работе с DAG дата-инженеру следует помнить о некоторых особенностях этого представления конвейера обработки данных. В частности, одним из них является так называемый верхнеуровневый код, который не является частью DAG или экземпляров оператора. Этот код находится вне операторов, например, выполняющий запросы к внешним системам. Обычно в AirFlow такой код используется для динамического создания задач, DAG или иного изменения того, что делает DAG при каждом его запуске. Например, скрипт запрашивает в базе данных список клиентов и создает одну копию DAG для каждого из них. Это довольно просто, но может привести к проблемам, если этот список клиентов велик или внешняя система чувствительна к большому объему запросов или же недоступна. По умолчанию AirFlow выполняет весь код в папке dags_folder каждые 30 секунд. Поэтому код верхнего уровня, который делает запросы к внешним системам, таким как API или база данных, или выполняет вызовы функций вне задач, может вызвать проблемы с производительностью, поскольку эти запросы и соединения выполняются каждые 30 секунд, а не только в запланированные моменты запуска DAG. Это может вызвать нагрузку на инфраструктуру AirFlow и на внешнюю систему.
Поэтому рекомендуется как можно меньше использовать код верхнего уровня, перепроектировав DAG. Например, когда нужно использовать переменную AirFlow в качестве параметра для задачи DAG вместо запроса на получение переменной за пределами экземпляра оператора:
foo = Variable.get("foo")
BashOperator(
task_id="bash_use_variable_good",
bash_command="echo variable foo=${foo_env}",
env={"foo_env": foo}
)
можно использовать шаблонную переменную, которая будет делать запрос к базе данных только во время выполнения:
BashOperator(
task_id= "bash_use_variable_good" ,
bash_command= "echo variable foo=${foo_env}" ,
env={ "foo_env" : "{{ var.value.foo }}" }
)
Таким образом, шаблоны могут отлично обеспечить динамическую передачу информации задачам во время выполнения, без использования кода верхнего уровня.
Другой альтернативой для динамического создания задач или DAG является использование динамического сопоставления задач, которое позволяет создавать параллельные копии задач во время выполнения на основе внешних критериев. Динамическое сопоставление задач было выпущено в Airflow 2.3, о чем мы писали здесь.
Apache Airflow для инженеров данных
Код курса
AIRF
Ближайшая дата курса
2 марта, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
Для иллюстрации этого варианта использования рассмотрим пример, когда нужно создать задачу для каждого элемента в списке, а сам список создается путем запроса к базе данных. Если использовать для получения списка код верхнего уровня и циклический просмотр результатов для создания задач:
from airflow.decorators import dag
from airflow.providers.postgres.operators.postgres import PostgresOperator
from airflow.providers.postgres.hooks.postgres import PostgresHook
from pendulum import datetime
# Bad practice: top-level code in a DAG file
hook = PostgresHook("database_conn")
results = hook.get_records("SELECT * FROM grocery_list;")
sql_queries = []
for result in results:
grocery = result[0]
amount = result[1]
sql_query = f"INSERT INTO purchase_order VALUES ('{grocery}', {amount});"
sql_queries.append(sql_query)
@dag(
start_date=datetime(2023, 1, 1),
max_active_runs=3,
schedule="@daily",
catchup=False
)
def bad_practices_dag_1():
insert_into_purchase_order_postgres = PostgresOperator.partial(
task_id="insert_into_purchase_order_postgres",
postgres_conn_id="postgres_default",
).expand(sql=sql_queries)
bad_practices_dag_1()
Такой DAG может снизить производительность Apache AirFlow, потому что подключение к базе данных и SQL-запрос на выборку данных SELECT * FROM product_list; будет выполняться каждые 30 секунд. Вместо этого лучше сделать задачу Python, чтобы получить список значений, и использовать динамическое сопоставление задач, чтобы создать задачу для каждого элемента в списке:
from airflow.decorators import dag, task
from airflow.providers.postgres.operators.postgres import PostgresOperator
from airflow.providers.postgres.hooks.postgres import PostgresHook
from pendulum import datetime
@dag(
start_date=datetime(2023, 1, 1), max_active_runs=3, schedule="@daily", catchup=False
)
def good_practices_dag_1():
@task
def get_list_of_results():
# good practice: wrap database connections into a task
hook = PostgresHook("database_conn")
results = hook.get_records("SELECT * FROM grocery_list;")
return results
@task
def create_sql_query(result):
grocery = result[0]
amount = result[1]
sql = f"INSERT INTO purchase_order VALUES ('{grocery}', {amount});"
return sql
sql_queries = create_sql_query.expand(result=get_list_of_results())
insert_into_purchase_order_postgres = PostgresOperator.partial(
task_id="insert_into_purchase_order_postgres",
postgres_conn_id="postgres_default",
).expand(sql=sql_queries)
good_practices_dag_1()
Этот метод устраняет проблемы с производительностью, связанные с вызовами верхнего уровня к внешней базе данных, и обеспечивает видимость всех исторических экземпляров задач, даже если они изменяются во время каждого запуска DAG.
Если же все-таки необходимо использовать код верхнего уровня для динамического создания DAG, можно уменьшить нагрузку на инфраструктуру AirFlow и внешние системы средствами Python. Например, функция get_with_cache() от дата-инженерами компании Astronomer, которая коммерциализирует и развивает экосистему AirFlow. Эта функция при использовании в качестве кода верхнего уровня в динамическом сценарии генерации DAG кэширует результаты запроса во внешнюю систему на указанный период времени. Так можно ограничить количество запросов, которые код верхнего уровня делает для одной DAG. По сути, функция get_with_cache() может стать альтернативой изменению параметра min_file_process_interval для всей среды AirFlow.
Пример ее использования выглядит так:
from datetime import datetime
from airflow import DAG
from dags.caching_util import get_with_cache
def get_sql_tables():
…
return …
with DAG(dag_id="my_caching_dag", schedule_interval=None, start_time=datetime(1970, 1, 1)):
my_sql_tables = get_with_cache(get_sql_tables, f"{dag_id}.cache")
for table in my_sql_tables:
SnowflakeOperator(…)
Вместо функции get_with_cache() можно использовать Python-библиотеку cachier для кэширования или tenacity для управления повторными попытками, чтобы по-прежнему выполнять синтаксический анализ DAG, даже если в запросе кода верхнего уровня возникла проблема. Впрочем, это не единственные способы динамического создания и запуска DAG, которые следует знать дата-инженеру. Далее рассмотрим, как реализовать зависимости между несколькими DAG в Apache AirFlow при построении сложных конвейеров обработки данных.
3 способа организации перекрестных зависимостей между разными DAG
С ростом популярности такой архитектуры данных, как Data Mesh, о чем мы писали здесь, наблюдается ярко выраженная тенденция к децентрализованному владению данных. Однако, целостное представление данных по-прежнему необходимо в корпоративном масштабе. В частности, дата-инженерам при проектировании сложных конвейеров обработки данных нужно, чтобы разные DAG знали состояние других конвейеров для создания или запуска новых цепочек задач. Apache AirFlow предоставляет 3 нативных способа создания таких перекрестных зависимостей: через TriggerDagRunOperator, ExternalTaskSensor и SimpleHttpOperator.
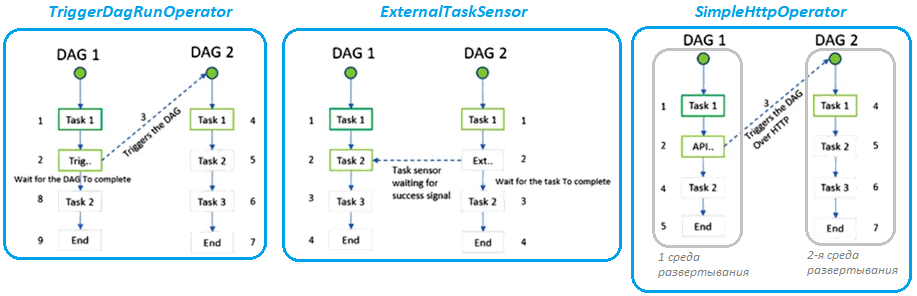
TriggerDagRunOperator позволяет иметь задачу в одной DAG, которая инициирует выполнение другой DAG в той же среде AirFlow . Это добавляет гибкости при создании сложных конвейеров. При настройке этого оператора следует внимательно задать значения следующих параметров:
- conf — отправляет данные в вызванную DAG;
- wait_for_completion — значение true позволяет инициировать нисходящие задачи только после завершения вызванной DAG;
- allow_states — список состояний, соответствующих успешному выполнению (успех, пропущенный);
- failed_states — список состояний, соответствующих неудачам;
- poke_interval — интервал работы в режиме датчика (сенсора) для ожидания события, если для параметра wait_for_completion установлено значение true.
Если необходимо, чтобы датчик искал прошлые выполнения другой DAG или задачи и в зависимости от своего статуса обрабатывал последующие задачи в своей собственной DAG, можно использовать ExternalSensor. Этот оператор будет сопоставлять те внешние DAG, которые используют один и тот же момент, чтобы разные DAG имели одинаковый интервал расписания. При настройке этого оператора надо установить параметр external_task_id в значение none, если необходимо полностью завершить DAG. ExternalTaskSensor получит только состояние SUCCESS или FAILED, соответствующее обнаруженной задаче или DAG, но не какое-либо выходное значение. Если требуется принять решение на основе значений, рассчитанных в задаче, нам нужно добавить BranchPythonOperator.
Вышеописанные методы TriggerDagRunOperator и ExternalTaskSensor предназначены для работы с DAG в одной среде AirFlow. Если нужно установить зависимость между DAG, работающими в двух разных развертываниях AirFlow, следует использовать REST API фреймворка, чтобы запустить DAG, отправив POST-запрос к конечной точке DAGRuns. Для этого можно использовать SimpleHttpOperator. Этот оператор используется для вызова HTTP-запросов и получения ответа. При его настройке надо задать необходимую конечную точку /api/v1/dags/<dag—id>/dagRuns и тело POST-запроса с полезной нагрузкой в формате JSON, где будет задан ключ, например, дата выполнения. Также необходимо задать сведения о соединении для другой среды в параметре http_con_id.
Если необходимо абстрагировать от обеих сред развертывания разных установок AirFlow до централизованной системы с перекрестными зависимостями разных DAG, необходимо реализовать 3 компонента:
- DependencyRuleEngine — для регистрации зависимости, что можно автоматизировать, указав в документе DAG параметры восходящего конвейера (DAG_ID и TASK_ID);
- DependencyEvaluation – для выдачи состояния DAG и задачи, что можно автоматизировать, подключившись к серверной базе данных AirFlow;
- Исполнитель, который инициирует выполнение DAG по расписанию в случае backfill-сценариев, о которых мы писали здесь.
Читайте в нашей новой статье о том, как дата-инженеру повысить эффективность работы с Apache AirFlow с помощью внешних пакетов: обзор ADA, Ditto, Amundsen, gusty и Viewflow.
Узнайте больше про администрирование и эксплуатацию Apache AirFlow для дата-инженерии и аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники

