 714
714 
Чем гиперграфы отличаются от обычных графов знаний, где они используются на практике и как эта математическая концепция поддерживается в NoSQL-СУБД HyperGraphDB.
Что такое гиперграф
Гиперграф — это графовая модель данных, в которой отношения (гиперребра) могут соединять любое количество заданных узлов. Можно сказать, что это обобщение графа, в котором каждым ребром могут соединяться не только две вершины, но и любые подмножества множества вершин. Гиперграфы часто используются при моделировании электрических цепей.
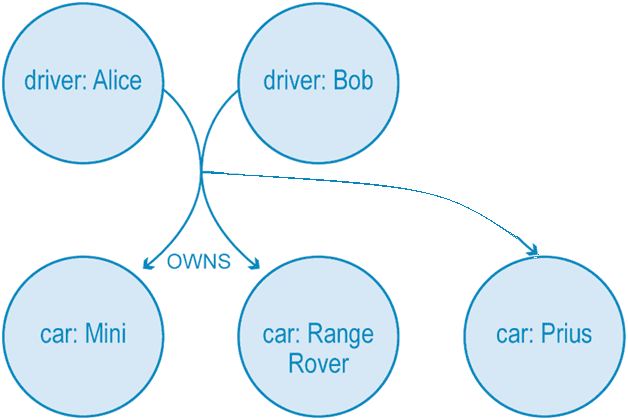
В обычном графе знаний (или графе свойств) отношения имеют только один начальный узел и один конечный узел. А в гиперграфе может быть любое количество узлов на обоих концах отношения. Такие гиперграфы полезны, когда данные включают большое количество отношений много-ко-многим. Например, этот направленный граф показывает, что Алиса и Боб являются владельцами трех транспортных средств. Выразить эту связь можно с помощью всего одного гиперребра вместо 6 ребер в обычном графе знаний.
Теоретически гиперграфы должны создавать информативные и очень точные модели данных. Однако, на практике очень легко упустить некоторые детали при моделировании. Для примера чуть усложним ранее рассмотренный пример, заложив в нее владельца транспортного средства (ТС), которым может быть 1 и только 1 человек. Эта модель графа свойств требует нескольких отношений OWNS, чтобы выразить то, что гиперграф зафиксировал с помощью всего одного гиперребра.
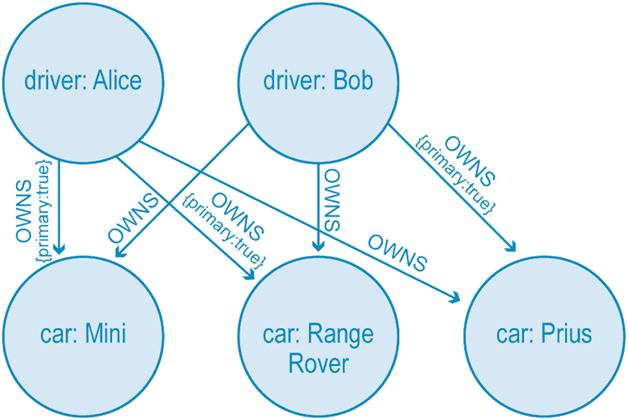
Использование шести отношений вместо одного гиперребра дает следующие преимущества:
- более популярный и знакомый большинству разработчиков метод моделирования данных;
- можно более точно настроить модель, добавив свойство основной владелец ТС, чего нельзя сделать с одним гиперребером.
Поскольку гиперребра многомерны, модели гиперграфов являются более обобщенными, чем графы свойств. Тем не менее, они изоморфны, поэтому всегда можно представить гиперграф как граф свойств, хотя и с большим количеством связей и узлов. Обратное же невозможно: граф не каждый свойств можно представить в виде гиперграфа.
Хотя считается, что графы свойств имеют лучшее соотношение эффективности использования и моделирования, гиперграфы демонстрируют свою особую силу в улавливании мета-намерения. Например, если нужно квалифицировать одно отношение с помощью другого, когда человек меняет свое мнение о чем-то в зависимости о том, как об этом предмете думает другой человек. В таком случае модель гиперграфа проще, чем обычный граф свойств. Таким образом, выбор модели всегда остается за разработчиком и основывается на поиске баланса между удобством моделирования и эксплуатации.
О том, что такое триплеты и чем они отличаются от гиперграфов и обычных графов свойств, читайте в нашей новой статье.
Знакомство с HyperGraphDB
Поскольку модель гиперграфа отличается от обычного графа знаний, неудивительно, что для практической реализации этой концепции нужны специальные технологии. Одной из них является HyperGraphDB – NoSQL СУБД с открытым исходным кодом для хранения направленных гиперграфов. Впрочем, хотя это хранилище предназначено в основном для управления знаниями, ИИ и семантических веб-проектов, его также можно использовать в качестве встроенной объектно-ориентированной базы данных для Java-проектов любого масштаба.
Будучи написанной на Java, HyperGraphDB отлично поддерживает объекты Java, но основное ядро базы данных нацелено исключительно на реализацию обобщенных, типизированных, направленных гиперграфов. Компоненты приложения HyperGraphDB реализуют различные модели предметной области, стандарты, алгоритмы и инструментальные средства предметной области, пользуясь преимуществом его универсальности. Каждая сущность в этих компонентах в конечном счете является атомом HyperGraphDB, что позволяет естественным образом интегрировать и компоновать их.
Базовая единица хранения в HyperGraphDB называется атомом. Каждый атом имеет тип, имеет произвольное значение и может указывать на ноль или более других атомов. Типы данных управляются общей расширяемой системой типов, встроенной в структуру гиперграфа. Типы сами по себе атомы, как и все остальные, но с определенной ролью. Схема хранения данных не зависит от платформы, поэтому к ней может обращаться любой язык программирования с любой платформы.
Система типов в HyperGraphDB не является полноценной формальной моделью в традиционном понимании систем типов. Ее основная цель — служить мостом между хранилищем и объектами среды выполнения. И он действительно поддерживает два фундаментальных понятия, которыми обладают системы типов: возможность сказать, принадлежит ли какой-либо атом A данному типу T, а также возможность заявить (и затем запросить), что тип T1 является подтипом типа Т2. Кроме того, типы в основном похожи на сериализаторы/десериализаторы: реализации могут брать объект Java и представлять его в HyperGraphDB, и наоборот, брать низкоуровневый граф хранилища и создавать объект времени выполнения. Это позволяет гибко настроить хранилище и использовать несколько моделей данных вместе, комбинируя их достоинства.
HyperGraphDB является встроенной базой данных, т.е. она предназначена для использования в том же процессе, что и приложение. Поэтому для использования HyperGraphDB следует изучить его API и концепций, лежащие в его основе. Низкоуровневое хранилище в настоящее время основано на BerkeleyDB от Sleepycat Software. Ограничений по размеру практически нет. Программное ограничение на размер графа, управляемого экземпляром HyperGraphDB, отсутствует. Размер каждого отдельного значения ограничен базовым хранилищем, т.е. ограничением BerkeleyDB в 2 ГБ. Однако архитектура позволяет при желании обходить BerkeleyDB для определенных типов атомов. Реализация HyperGraphDB очень простая и не содержит большого количества конфигураций и других настраиваемых параметров BerkeleyDB. База данных поставляется в виде библиотеки, которую можно использовать непосредственно через ее API. Фактически, чтобы использовать HyperGraphDB, разработчику нужно всего лишь включить библиотеку в свое приложение. При возникновении проблем можно использовать набор инструментов BerkeleyDB для отладки.
Поскольку реализация HyperGraphDB основана исключительно на Java, она предлагает автоматическое сопоставление идиоматических типов Java со схемой данных HyperGraphDB, что превращает HyperGraphDB в объектно-ориентированную базу данных, подходящую для обычных бизнес-приложений. Платформа P2P для распределенной обработки была реализована для алгоритмов репликации/разделения данных, а также для вычислений в стиле клиент-сервер.
В модели данных HyperGraphDB есть две особенности, которые отличают ее от обычного графа:
- ребра, указывающие на более чем два узла (n-арные ребра);
- ребра, указывающие на другие ребра (метаребра).
В обоих случаях речь идет об усилении отношений между узлами, которые можно выразить. Простым примером n-арного ребра является любое n-арное отношение, которое может быть в реляционной базе данных. Поэтому HyperGraphDB в основном работает с кортежами.
Еще одним примером является отношение «между». В частности, когда точка A находится между B и C, это взаимосвязь между тремя узлами: A, B и C. Обычный граф не может выразить это. Примером четвертичных отношений может быть выражение «один к трем, как три к девяти». Это отношение нельзя показать на стандартном графе, как и построить отношения типа «А к В, как С к D», выражающие аналогии. Понадобятся цели для ребер или метаребра: обычный граф не справится с такой задачей. Вернее, это можно сделать на обычном графе свойств, но он будет содержать очень много узлов и ребер, а также код для управления ими.
При разработке модели данных HyperGraphDB разработчику следует решить, какие из классов представляют отношения, а какие — базовые данные. Экземпляры классов, которые представляют базовые данные, могут быть добавлены в экземпляр HyperGraphDB без каких-либо изменений. Они будут просто атомами арности 0, которые не указывают на другие атомы. Классы, которые представляют отношения, должны быть преобразованы в ссылки HyperGraphDB, то есть реализации интерфейса HGLink. При работе со сторонним API, которые нельзя изменить, можно использовать класс-оболочку HGValueLink. Однако, в этом случае не нельзя получить доступ к целевому набору ссылки из экземпляра объекта Java, и придется полагаться на API HGValueLink. Впрочем, можно превратить любой объект в ссылку гиперграфа, обернув его как HGValueLink, чтобы не нужно изменять класс Java объекта. Объект будет храниться как значение «полезной нагрузки» ссылки и по-прежнему будет представлять связь на графе. Объект, т.е. атом гиперграфа однозначно идентифицируется только своим дескриптором HGDB. В отличие от РСУБД, в HyperGraphDB не требуется указывать первичный ключ для типа атома: обычно его свойства идентифицируют его однозначно. Как минимум, его ценность и целевой набор делают его уникальным. Таким образом, для создания уникального объекта надо добавить объект с уникальной идентификацией, сначала выполнив поиск по свойствам, которые определяют его уникальным образом, а затем вставить в базу данных, только если этот поиск не возвращает никаких результатов.
Все примитивные операции, предлагаемые API HyperGraphDB, автоматически инкапсулируются в транзакцию. Также HyperGraphDB поддерживает вложенные транзакции, в которых дочерние транзакции могут завершаться сбоем и корректно обрабатываться, в то время как родительская транзакция по-прежнему выполняется успешно. Выделяют три сценария, когда можно начать и завершить транзакцию самостоятельно через HyperGraph.getTransactionManager():
- пользователь сам выполняет итерацию по набору результатов запроса, а не извлекает все данные из коллекции Java;
- есть несколько операций, которые надо рассматривать как единое целое — это самый распространенный случай. Например, нужно вставить два атома и отношения между ними, и ни атомы, ни отношения по отдельности не имеют смысла в модели данных. Тогда можно обернуть 3 вызова в транзакцию add().
- есть часть приложения, интенсивно использующая данные, которая добавляет сотни атомов в цикле. Можно обернуть эти дополнения в транзакцию для повышения производительности, т.к. при выполнении примитивной операции HyperGraphDB создаст транзакцию только если в данный момент она не действует. Иначе HyperGraphDB будет повторно использовать текущую транзакцию. Если делать сотню добавлений атомов в цикле без создания транзакции, HyperGraphDB создаст и зафиксирует сотню отдельных транзакций. Это гораздо дороже, чем создавать и совершать одну транзакцию на все 100 дополнений. Однако, таким образом будут добавлены либо все атомы, либо ни один из них. Оптимальное количество таких примитивных операций, объединяемых в одну транзакцию, варьируется от системы к системе и от сложности самих атомарных значений.
Поскольку HyperGraphDB является встроенной базой данных, если ее экземпляр будет уничтожен до того, как завершится процесс задания, может произойти потеря данных. В производственных системах рекомендуется обеспечить операцию graph.close(), заключая код в блок try, graph.close() в блок finally. Поскольку в большинстве ситуаций реальной опасности потери данных нет, а открытие и закрытие связаны с затратами, можно оставить базу данных открытой до завершения работы приложения.
Узнайте больше про использование графовых алгоритмов и средств работы с ними для практического применения в реальных проектах аналитики больших данных на специализированных курсах нашего лицензированного учебного центра обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники

