 1446
1446 
Содержание
Сегодня рассмотрим, как организовать полностью сохраняемый сервис Apache NiFi с помощью Docker, чтобы обеспечить безопасность конвейеров и потоков данных при изменении конфигураций и перезапуске служб. А также разберем, как дата-инженеру и администратору кластера NiFi запустить его на Kubernetes.
Проблемы масштабирования и отказоустойчивости Apache NiFi
Благодаря наличию веб-GUI, множеству готовых процессоров и возможности написать собственный обработчик данных, Apache NiFi стал одним из самых востребованных инструментов современного дата-инженера. Эта платформа потоковой маршрутизации данных позволяет легко и быстро создать конвейеры их обработки, автоматизировать сбор, преобразование и маршрутизацию информации из множества источников, эффективно организовать ETL-процессы. Например, можно в режиме реального времени получать твиты по определенным хэштегам, загружать файлы из AWS S3, вызывать методы REST API и отправлять электронные письма. А если какой-то узел обработки данных, т.е. процессор, остановлен или еще занят, информация не теряется, а помещается в очередь. Однако, возможности масштабирования NiFi очень ограничены: нельзя запустить процессоры на разных компьютерных узлах. Это также снижает отказоустойчивость созданных конвейеров, несмотря на наличие внутреннего реестра, т.к. восстановление данных из него занимает время.
Решить эти проблемы помогают технологии контейнерной виртуализации: Docker и Kubernetes. В частности, запуск приложения Apache NiFi как полностью сохраняемый Docker-сервис обеспечивает непрерывную работу даже в случае перезапуска конвейеров при сбое – их уже не придется восстанавливать вручную, перестраивать процессоры, повторно подключать реестр или перенастраивать целые группы процессов. А если требуется автоматизированное управление множеством Docker-конейнеров, платформа Kubernetes справится с этим, впрочем, не без проблем, о чем мы писали здесь. Как обеспечить безопасность конвейеров и потоков данных при изменении конфигураций и перезапуске сервисов Apache NiFi с помощью Docker и Kubernetes, мы рассмотрим далее.
Заключение Apache NiFi в Docker-контейнер
Создание полностью сохраняемого сервиса NiFi включает в себя сохранение реестра (внутренней системы контроля версий для групп процессов), а также создание Docker-контейнеров самих конвейеров обработки данных и их настроек. Для этого понадобится Apache Zookeeper, который является фундаментальной частью кластера этой платформы потоковой маршрутизации данных с версии 1, обеспечивая распределенную координацию и связь внутри кластера на случай масштабирования и запуска отдельных узлов.
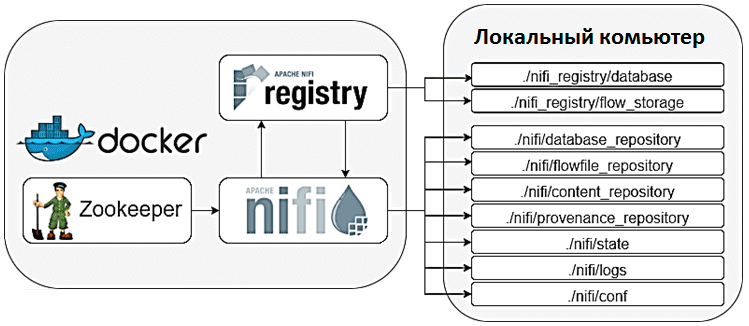
В реестре НайФай можно сохранить созданные сегменты или бакеты (bucket) и любые потоки, которые они включают, подключив к локальной машине два тома – хранилище потоков (flow_storage) и базу данных:
./nifi_registry/database:/opt/nifi-registry/nifi-registry-current/database
./nifi_registry/flow_storage:/opt/nifi-registry/nifi-registry-current/flow_storage
Каталог flow_storage включает бакеты и упакованные в них потоки, которые имеют универсальные уникальные идентификаторы (UUID), аналогичные тем, что NiFi использует для идентификации процессоров, групп процессов и сервисов контроллеров среди других элементов. Структура flow_storage выглядит так:
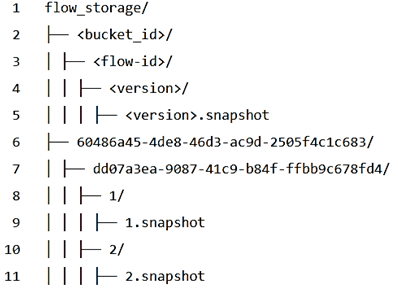
Каталог базы данных состоит из одного файла: nifi-registry-primary.mv, который позволяет загрузить бакеты и потоки из каталога хранения потока.
После подключения каталогов database и database к реестру NiFi, любые файлы, которые Docker-контейнер создает в этих каталогах, в конечном итоге будут считаны и записаны на локальный компьютер. Таким образом, независимо от того, перезапускается ли Docker-контейнер или полностью воссоздается, эти файлы постоянно будут сохранены, а любые изменения в потоках или вновь созданных бакетах будут появляться снова при перезапуске Docker-контейнера.
Чтобы сохранить группы процессов, процессы, подключения и службы контроллера НайФай, следует однократно выполнить набор действий, после которого, независимо от количества перезапусков все элементы всегда будут сохранены. Напомним, платформа потоковой маршрутизации данных НайФай хранит информацию для сохранения элементов потока в каталоге конфигураций conf. Но при монтировании каталога перед первым запуском Docker-контейнера, контейнер NiFi сам не запускается. Поэтому нужно запустить его вручную:
- запустить Docker-контейнер NiFi, не монтируя каталог conf. Следует выполнить команду docker-compose up из вновь созданного каталога и немного подождать, пока NiFi полностью не развернется. Это может занять около минуты, после чего можно получить доступ к веб-интерфейсу платформы потоковой маршрутизации данных по адресу на локальном хосте.
- скопировать каталог conf из работающего контейнера в локальный каталог conf с помощью команды docker cp. Получить идентификатор нужного Docker-контейнера поможет команда docker ps. Эти команды следует выполнять из нового окна терминала, yt не прерывая работающий контейнер, но в том же каталоге, где сохранен файл docker-compose.yml, чтобы гарантировать, что он будет скопирован в правильное место.
- остановить работающие Docker-контейнеры, нажав CTRL + C в окне командной строки, где они были ранее запущены с помощью команды docker-compose up;
- смонтировать локальный каталог conf и перезапустить Docker-контейнер с помощью команды docker-compose up —force-recreate. Флаг —force-recreate позволяет убедиться, что контейнеры улавливают последние изменения в файле docker-compose.yml. Это не влияет на данные, хранящиеся на подключенных томах, но запустит сервисы НайФай со всеми элементами, службами контроллеров, сегментами реестра и подключениями, сохраненными и неповрежденными.
Таким образом, Docker позволяет перезапускать контейнеры сервисов NiFi, не беспокоясь об их масштабировании и скорости восстановления в случае сбоя [1].
Запуск на Kubernetes
При необходимости запуска контейнеров Apache NiFi на Kubernetes предварительно следует создать конфигурации развертывания, сервиса и входа, описав их в YAML-файле. При развертывании экземпляр этой платформы потоковой маршрутизации данных настраивается для работы однопользовательского режима, причем имя пользователя жестко запрограммировано для администратора, можно также указать переменную среды или секрет для хранения ранее созданного пароля.
Часть входа более сложна, т.к. платформа потоковой маршрутизации данных по умолчанию использует SSL и самостоятельно выданные сертификаты, о чем мы рассказываем здесь. Аннотации к веб-серверу NGINX позволят обеспечить верное обращение:
- cert-manager.io/cluster-issuer – здесь следует указать название выпускающего кластера диспетчера сертификатов;
- nginx.ingress.kubernetes.io/backend-protocol – чтобы NGINX использовал протокол HTTPS, а не HTTP по умолчанию, здесь следует указать это;
- nginx.ingress.kubernetes.io/upstream-vhost – свойство для переопределения HTTP-заголовка «Host» на localhost с нужным портом;
- nginx.ingress.kubernetes.io/proxy-redirect-from и nginx.ingress.kubernetes.io/proxy-redirect-to – эти свойства указывают NGINX, что необходимо переписать заголовок «Местоположение» (Location) или «Обновить» (Refresh) во внешний домен, а не на ранее указанный локальный хост.
После запуска YAML-файла с отмеченными параметрами, Apache NiFi будет готов для Kubernetes. Также можно добавить сервис реестра, чтобы сохранять изменения в рабочих процессах, конвейеры данных, а также загружать новые и перезапускать их [2]. Посмотреть содержимое YAML-файл и скачать его для практического использования можно в источнике [3].
О том, как улучшена работа с Docker и Kubernetes в новом релизе потокового ETL-маршрутизатора 1.15.0, читайте в нашей новой статье. А пример практической эксплуатации бессерверных технологий НайФай смотрите здесь.
Освойте все тонкости администрирования и эксплуатации Apache NiFi для эффективной аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники

