 934
934 
Содержание
Обогащение потока данных информацией из внешнего API без остановки вычислений: 3 способа реализовать это средствами Apache Flink на примере сервиса геолокации.
Зачем обогащать потоковые данные через внешний API и как это сделать для Flink-приложения?
Иногда необходимо обогатить потоки данных, т.е. дополнить потоковые данные в реальном времени, т.е. на лету, не прерывая обработку постоянно генерируемых событий. Один из подобных случаев мы разбирали в этом материале. Сегодня рассмотрим другой пример из области геоинформационных задач, таких как поиск свободной машины такси, определение наименее загруженного пути и т.д.. В этом сценарии нужно найти геолокацию клиента по IP на лету и добавить эти данные в каждую запись. Apache Flink позволяет реализовать подобный сервис, объединяя возможности потоковой и пакетной обработки в своих универсальных API.
Предположим, Flink-приложение обращается к внешнему REST-сервису, чтобы получить сведения о геолокации по IP-адрес клиентского запроса. Самое простое, хотя и небезопасное решение – просто передавать IP-адрес в параметра GET-метода HTTP-запроса, ожидая в ответа JSON-документ с данными о геолокации этого IP-адреса. Однако, подобное синхронное взаимодействие может оказаться медленным, что противоречит самой идее потоковой передаче данных. А если вызов метода API сервиса геолокации будет запускаться для каждого IP-адреса отдельно, для обработки всего потока записей потребуется много времени.
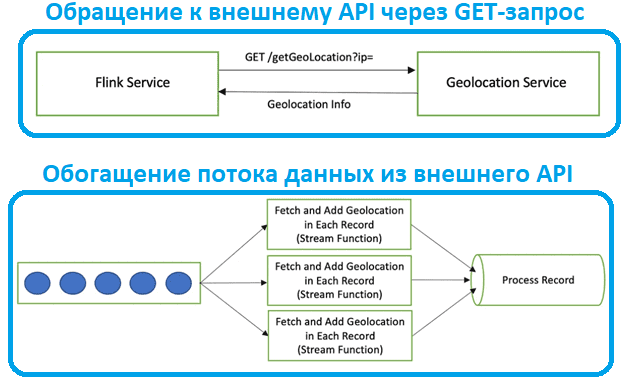
Для реализации этого взаимодействия Flink-приложения с внешним API для обогащения потока данных в реальном времени можно использовать несколько подходов, которые отличаются производительностью:
- группировка записей с помощью оконных функций Apache Flink;
- разделение исходного потока на несколько разных по ключам с помощью оператора KeyBy;
- гибридный подход – совмещение группировки через оконные функции и разделение по ключам.
Далее рассмотрим, что представляет собой каждый из этих способов, и разберем, какой из них работает более эффективно.
Тестирование гипотез: проверка 3-х возможных способов
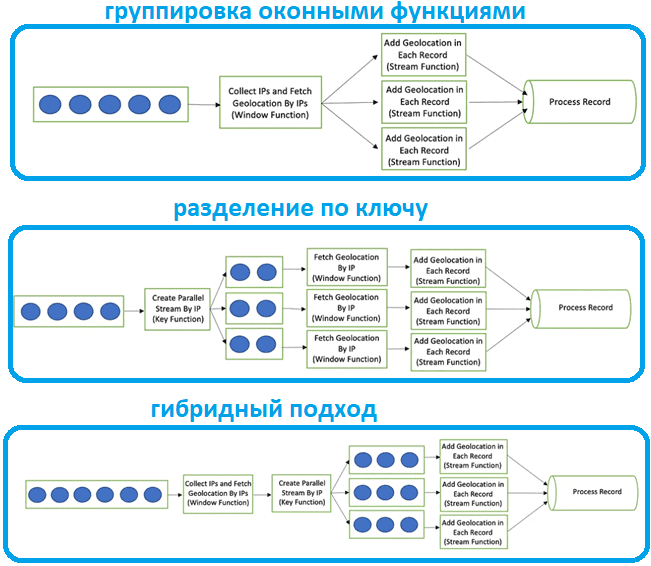
Начнем с группировки записей без их разделения на несколько потоков. Это реализуется с помощью оконных функций, о которых мы писали здесь и здесь. Окно разбивает поток на «сегменты» конечного размера, над которыми выполняются вычисления. Окно создается, как только появляется первый элемент, который должен принадлежать ему, и полностью удаляется, когда время события или обработки проходит отметку окончания (timestamp) плюс заданное пользователем допустимое время задержки (Allowed Lateness). Flink гарантирует удаление только для временных окон.
Окна позволяют группировать записи по периодам их появления. В потоках без ключей исходный поток не разделяется на несколько логических потоков, все элементы в потоке обрабатываются вместе, и оконная UDF-функция имеет доступ ко всем элементам в потоке. Недостатком этого способа является отсутствие параллелизма: лишь одна машина в кластере может выполнить код. В нашем примере все IP-адреса будут собираться на основе определенного количества окон и получать геолокацию за один вызов. После получения ответа детали геолокации добавляются в запись и обрабатываются дальше.
Пример оператора такой обработки на Java выглядит следующим образом:
SingleOutputStreamOperator<String> broadcastStream = streamPipeLine
.countWindowAll(500)
.apply(new WindowFunction())
.process(new StreamFunction());
Второй способ, разделение исходного потока на несколько согласно значению ключа, реализуется с помощью оператора KeyBy, который чаще всего используется для потоковых преобразований. Он разделяет поток данных на основе свойств или ключей входящих объектов. После применения оператора keyBy, все объекты данных с одинаковым типом ключей группируются, что очень похоже на GroupBy в традиционном SQL. В случае рассматриваемого примера в функции ключа для каждого IP-адреса, полученного в определенное время, все записи будут сгруппированы. Один вызов геолокации станет триггером для одного IP-адреса, независимо от количества самих IP-адресов. После получения ответа детали геолокации будут добавляются в запись и обрабатываются дальше.
Пример оператора такой обработки на Java с использованием «кувыркающегося окна», поверх которого работает разделение по ключу, выглядит следующим образом:
SingleOutputStreamOperator<String> broadcastStream = streamPipeLine
.keyBy(new KeyFunction())
.window(TumblingProcessingTimeWindows.of(Time.seconds(5)))
.apply(new WindowFunction())
.process(new StreamFunction());
Наконец, в случае гибридного подхода сперва все записи собираются и обрабатываются на основе определенного количества окон, например, 500. А затем все объекты данных с ключами одного типа группируются и обрабатываются в потоковой UDF-функции, например, с названием StreamFunction(). Этот подход реализуется следующим участком кода:
SingleOutputStreamOperator<String> broadcastStream = streamPipeLine
.countWindowAll(500)
.apply(new WindowFunction())
.keyBy(new KeyFunction())
.process(new StreamFunction());
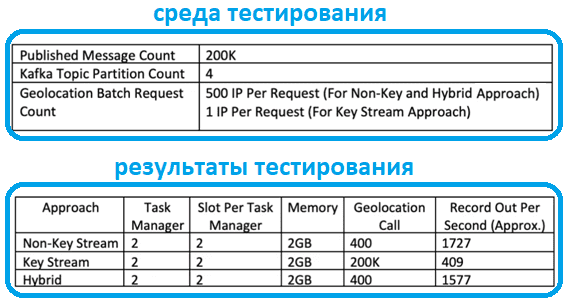
Тестирование производительности каждого из рассмотренных вариантов на потоке из топика Kafka с 4-мя разделами и 200 тысячами сообщений с 500 IP-адресами в одном запросе (для способа 1 и 3), а также 1-м IP-в запросе в случае разделения по ключу, показало, что оконные функции работают быстрее и эффективнее.
Узнайте больше про применение Apache Flink для потоковой обработки событий в распределенных приложениях аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
[elementor-template id=»13619″]
Источники
- https://medium.com/@samarth.sharma02/enriching-the-flink-data-stream-using-external-api-1674923a953f
- https://nightlies.apache.org/flink/flink-docs-master/docs/dev/datastream/operators/windows/
- https://nightlies.apache.org/flink/flink-docs-master/api/java/org/apache/flink/streaming/api/datastream/KeyedStream/

