Что такое потоковое обогащение данных, зачем это нужно и как оно реализуется в Apache Flink. Проблемы и решения предварительной загрузки справочных данных в память, синхронного и асинхронного поиска в источнике по каждой записи и организация потоковой передачи событий.
3 способа загрузить эталонные (справочные) данных в Apache Flink для обогащения потока
Потоковое обогащение наполняет потоки необработанных данных дополнительным контекстом и деталями, чтобы дать более полную картину для принятию управленческих решений. Например, транзакции в интернет-магазине можно дополнить данными учетной записи клиента, события IoT-датчика его эталонными значениями, отчеты о счетах за мобильный телефон – данными о геолокации абонента, а онлайн-журналы потоковой передачи музыки – пользовательскими настройками и плейлистами. Пример подобного сценария мы ранее разбирали здесь.
Обогащение является фундаментальной задачей во многих конвейерах обработки данных, и Apache Flink предоставляет несколько способов ее достижения, в зависимости от размера данных, пропускной способность системы и сети, допустимой задержки, желаемого формата вывода и других факторов. Перед тем, как приступать проектированию и реализации конвейера обогащения потока данных в Apache Flink, следует ответить на несколько вопросов:
- Что является источником истины для справочных данных?
- С какой нагрузкой может справиться этот источник данных (база данных или сервис)?
- Можно ли обогащать устаревшие данные?
- Какова пропускная способность и допустимая задержка обработки?
- Имеет ли смысл полностью отражать данные в состоянии Flink?
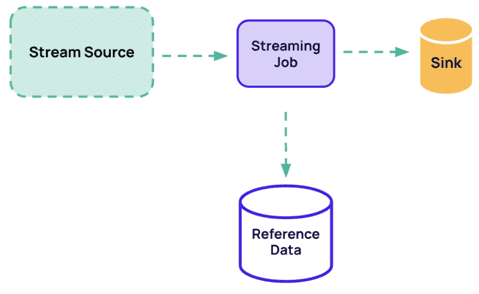
Таким образом, все начинается со справочных данных (Reference Data), доступ к которым можно реализовать одним из 3-х способов:
- предварительно загрузить весь набор эталонных данных в память при запуске потокового приложения;
- выполнить поиск по записям, запрашивая справочные данные по мере необходимости;
- организовать потоковую передачу справочных данных и их сохранение в состоянии Flink.
Далее рассмотрим каждый из этих способов, включая проблемы, которые могут возникнуть при их использовании и устраняющие их решения.
Предварительная загрузка справочных данных
При предварительной загрузке справочных данных может возникнуть проблема с отсутствием ключей, необходимых для извлечения. Обогащение в Apache Flink является сложной задачей при работе с большими наборами эталонных данных. Когда задача требует поиска большого количества значений в наборе эталонных данных, можно предварительно загрузить эталонные данные из базы данных в методе open() функции RichFlatMapFunction. Это позволит искать любой ключ, не зная его заранее. Недостатком этого подхода является то, что он может быть очень неэффективным, если набор эталонных данных большой. Пример Java-кода, реализующего этот подход, выглядит так:
public class EnrichmentWithPreloading extends RichFlatMapFunction<Event, EnrichedEvent> {
private Map<Long, SensorReferenceData> referenceData;
@Override
public void open(final Configuration parameters) throws Exception {
super.open(parameters);
referenceData = loadReferenceData();
}
@Override
public void flatMap(
final Event event,
final Collector<EnrichedEvent> collector) throws Exception {
SensorReferenceData sensorReferenceData =
referenceData.get(sensorMeasurement.getSensorId());
collector.collect(new EnrichedEvent(event, sensorReferenceData));
}
Другое решение — использовать настраиваемый разделитель, чтобы определить, какая задача будет отвечать за каждый ключ. Этот разделитель будет использоваться для распределения эталонных данных по задачам. Этот подход более эффективен, чем предыдущее решение, поскольку требует получения данных только для тех ключей, которые относятся к задаче. Кроме того, этот подход позволяет обрабатывать данные параллельно, что ускоряет процесс обработки.
В качестве примера рассмотрим разделение потока входных данных на основе идентификатора датчика. Метод разделения вычисляет индекс раздела, взяв модуль идентификатора датчика с количеством разделов.
private static class SensorIdPartitioner implements Partitioner<Long> {
@Override
public int partition(final Long event, final int numPartitions) {
return Math.toIntExact(event % numPartitions);
}
}
public static void main(String[] args) throws Exception {
...
DataStream<Event> events = env.addSource(new SensorEventSource(...));
DataStream<EnrichedEvent> enrichedEvents = events
.partitionCustom(new SensorIdPartitioner(), measurement -> measurement.getSensorId())
.flatMap(new EnrichmentFunctionWithPartitionedPreloading());
public class EnrichmentWithPartitionedPreloading extends RichFlatMapFunction<Event, EnrichedEvent> {
private Map<Long, SensorReferenceData> referenceData;
@Override
public void open(final Configuration parameters) throws Exception {
super.open(parameters);
referenceData = loadReferenceData(
getRuntimeContext().getIndexOfThisSubtask(),
getRuntimeContext().getNumberOfParallelSubtasks()
);
}
@Override
public void flatMap(
final Event event,
final Collector<EnrichedEvent> collector) throws Exception {
SensorReferenceData sensorReferenceData = referenceData.get(sensorMeasurement.getSensorId());
collector.collect(new EnrichedEvent(event, sensorReferenceData));
}
В этом коде поток данных событий обрабатывается с помощью преобразования partitionCustom, которое применяет SensorIdPartitioner для разделения потока данных на основе идентификатора датчика. После разделения применяется преобразование flatMap с помощью функции EnrichmentFunctionWithPartitionedPreloading(), которая выполняет фактический процесс обогащения, загружая справочные данные на основе индекса раздела и параллелизма. Затем каждое событие обогащается соответствующими эталонными данными датчика. Класс EnrichmentWithPartitionedPreloading представляет собой пользовательскую реализацию интерфейса RichFlatMapFunction, который содержит логику для загрузки эталонных данных и выполнения обогащения. Метод open() вызывается один раз для каждой параллельной подзадачи и загружает справочные данные на основе индекса подзадачи и параллелизма.
Важно отметить, что предварительная загрузка справочных данных подходит только для определенных случаев использования, когда данные, помещающиеся в память Flink-приложения, меняются редко. Рассмотренные решения довольно просты, имеют высокую пропускную способность, низкую задержку и возможность обогащать потоковые данные данными из баз данных. Однако, есть риск обогащения потока устаревшими данными. Также к недостаткам относится необходимость размещения эталонного набора данных в памяти и невозможность использовать его для начальной загрузки состояния с ключом.
Поиск справочных данных для каждой записи
Этот способ включает в себя поиск связанной информации из набора справочных данных для каждой записи входных данных. Преимущество этого подхода заключается в наличии актуальных данных, поскольку справочный набор данных может обновляться независимо от входных данных. С другой стороны, этот подход требует больше ресурсов и может привести к увеличению времени обработки.
Flink SQL поддерживает как синхронный, так и асинхронный поиск эталонных данных. Синхронный поиск можно реализовать с помощью функции RichFlatMapFunction(), а асинхронный поиск поддерживается оператором асинхронного ввода-вывода Flink. Вызов асинхронной функции AsyncFunction для каждой записи входных данных обеспечивает повышенную пропускную способность, поскольку AsyncFunction может обрабатывать несколько записей одновременно. Кроме того, так можно использовать настраиваемые параметры времени ожидания и пропускной способности, что позволяет пользователю контролировать компромисс между задержкой и пропускной способностью.
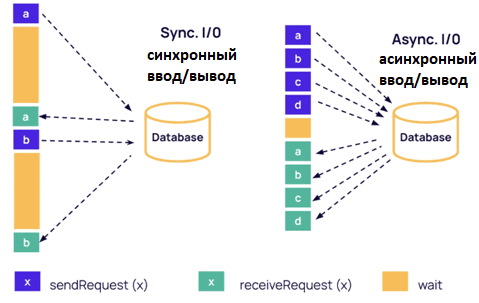
Чтобы соответствовать парадигме потоковой передачи событий, Flink использует водяные знаки. Функция unorderedWait() во Flink обеспечивает, чтобы водяные знаки не выдавались слишком рано или слишком поздно. Нарушение порядка, вызванное unorderedWait(), разрешено только между водяными знаками. Flink также избегает потенциальных ловушек, обеспечивая отказоустойчивость. Функции для текущих запросов хранятся в моментальных снимках состояния и повторно запускаются во время восстановления.
Пример Java-кода, реализующего такой подход, выглядит так:
public class AsyncEnrichmentFunction extends RichAsyncFunction<Event, EnrichedEvent> {
private ReferenceDataClient client;
@Override
public void open(final Configuration parameters) throws Exception {
super.open(parameters);
client = new ReferenceDataClient();
}
@Override
public void asyncInvoke(final Event event, final ResultFuture<EnrichedEvent> resultFuture) {
client.asyncGetReferenceDataFor(
event.getReferenceId(),
new Consumer<ReferenceData>() {
@Override
public void accept(final ReferenceData referenceData) {
resultFuture.complete(Collections.singletonList(new EnrichedEvent(
event,
referenceData)));
}
});
}
}
Этот код представляет собой Java-класс AsyncEnrichmentFunction, который расширяет класс RichAsyncFunction для асинхронного обогащения объекта Событие и создания в результате объекта EnrichedEvent. Класс имеет закрытое поле Клиент типа ReferenceDataClient, которое используется для извлечения справочных данных для процесса обогащения. Метод open() переопределяется для инициализации поля Client путем создания нового экземпляра класса ReferenceDataClient.
Также в коде переопределяется метод asyncInvoke – основной метод, отвечающий за выполнение асинхронного обогащения. Он принимает два параметра: объект Event для обогащения и объект ResultFuture<EnrichedEvent> для завершения процесса обогащения.
В методе asyncInvoke вызывается метод client.asyncGetReferenceDataFor для асинхронного получения эталонных данных для заданного event.getReferenceId(). Результат этой асинхронной операции передается объекту Consumer<ReferenceData>, который реализуется встроенным с помощью метода accept. Внутри метода accept вызывается метод resultFuture.complete для завершения процесса обогащения путем создания нового объекта EnrichedEvent с использованием объектов event и referenceData. Затем это расширенное событие добавляется в список с помощью Collections.singletonList и передается в качестве аргумента в метод resultFuture.complete.
Потоковая передача справочных данных и их сохранение в состоянии Apache Flink
Наконец, можно реализовать захват эталонных данных в виде потока. Для этого Apache Flink предоставляет несколько способов объединения двух потоков и выполнения обогащения:
- включение обоих потоков и их ручное соединение с помощью функции CoProcessFunction;
- включение одного потока и трансляция другого с помощью функции KeyedBroadcastProcessFunction;
- использование API потока данных для соединения с временным окном;
- использование SQL-запросов табличных API с несколькими типами соединений (обычные внутренние INNER и внешние OUTER, эти же соединения с временным окном временные соединения с версионными таблицами, а также соединение поиска с внешними базами данных).
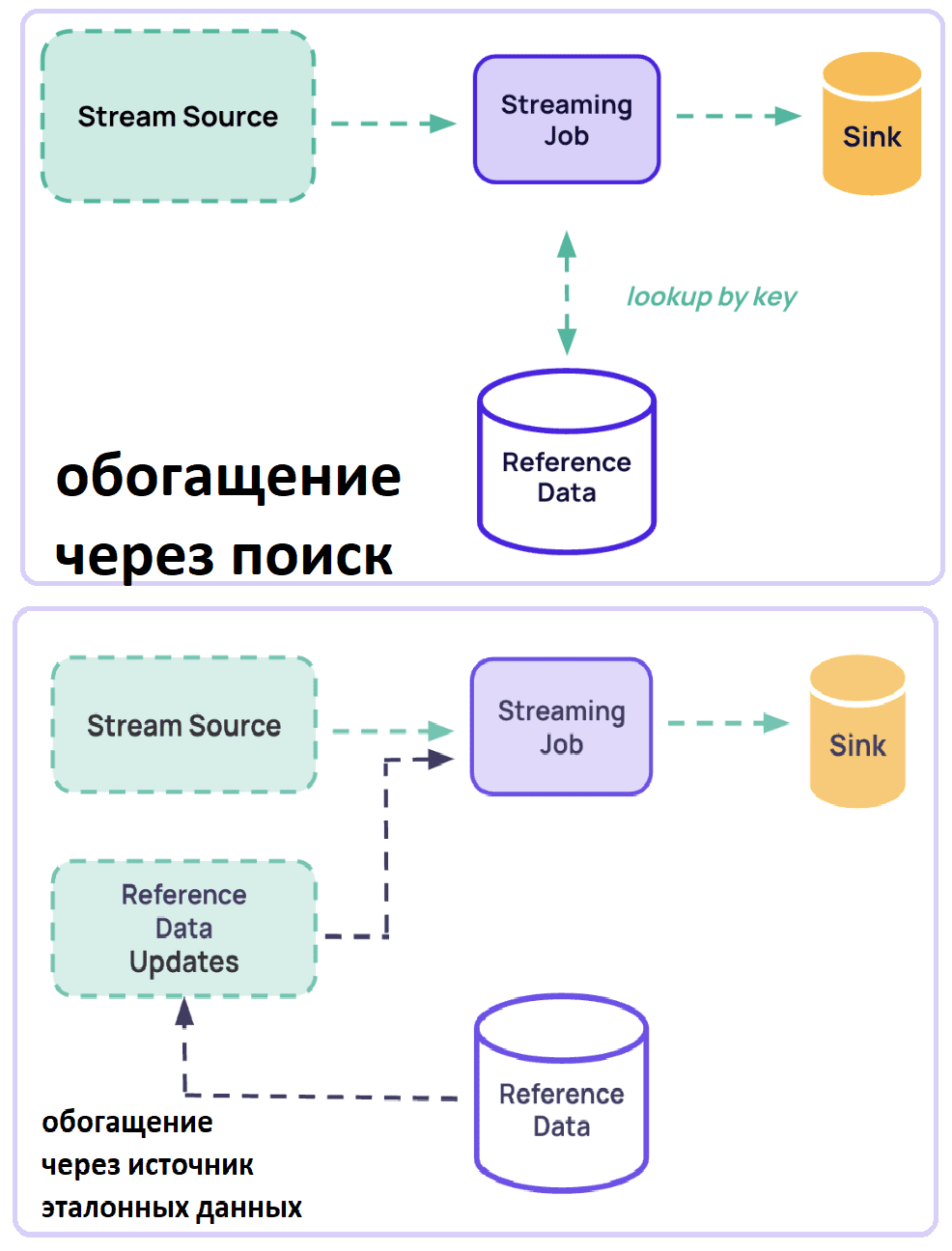
Flink предоставляет коннекторы для популярных потоковых источников, включая Apache Kafka, Debezium, Canal. При работе с состоянием начальной загрузки следует использовать состояние начальной загрузки для обогащения за счет чтения из какого-либо потока до тех пор, пока он не будет достигнут. Затем надо обрабатывать основной поток, используя это состояние обогащения, продолжая получать обновления для потока обогащения. Хотя Flink не упрощает эту задачу, можно использовать State Processor API для создания исходной точки сохранения из дампа БД. Также можно подготовить специальную загрузочную версию задания, которая считывает данные из потока обогащения до тех пор, пока состояние не будет готово. Затем можно создать точку сохранения и начать само задание с этой точки сохранения, убедившись, что операторы с отслеживанием состояния в обоих заданиях имеют совпадающие UID. А как это сделать с помощью Flink SQL, читайте в нашей новой статье.
Освойте возможности Apache Flink для потоковой обработки событий в распределенных приложениях аналитики больших данных и машинного обучения на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники